 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimating Mutual Information between Time Series and Temporal Event Sequences Across Diverse Analysis Tasks
Jun 01, 2026Pairwise dependence measures such as correlation and causality are fundamental to temporal data mining, yet there is still no principled and robust way to quantify dependence between heterogeneous data types, especially between continuous time series and discrete temporal event sequences. Existing approaches rely on ad hoc transformations or mutual-information estimators that are highly sensitive to quantization, repeated values, and event redundancy, leading to biased or unstable results in practice. We propose a nonparametric mutual information estimator that directly measures the dependence between time series and event sequences without data transformation, learning, or ad hoc discretization. Our method models the continuous-discrete duality of real-world time series to handle quantization and repeated-value artifacts and introduces a latent event clustering strategy to mitigate bias from event co-occurrence and redundancy. Together, these yield a robust and unified framework that bridges discrete and continuous mutual information. We evaluate the proposed estimator on four representative tasks: discrete-continuous time-delayed mutual information for causality analysis, global and local temporal repetition discovery, discrete covariate selection for time series forecasting, and continuous feature selection for classification. Experiments on synthetic and real-world datasets show consistent improvements over existing methods in accuracy, robustness, and interpretability, positioning our approach as a general-purpose dependence operator for heterogeneous temporal data, similar to Pearson correlation for homogeneous time series. Code available at: https://github.com/HaojiHu/Multimodal-Temporal-Data-Quantification
Locality Matters for Training-Free Audio Token Compression in Audio-Language Models
May 24, 2026Audio-language models (ALMs) are increasingly used for audio captioning, question answering, and open-ended audio understanding, but their inference cost remains high when audio inputs are represented as long prefix-token sequences. These audio prefixes consume context budget, increase memory usage, and make deployment harder in resource-constrained or latency-sensitive settings. Existing training-free audio-token reduction methods mainly rely on fixed pooling or score-based pruning. Fixed pooling is content-agnostic, while score-based pruning can preserve isolated salient tokens but discard nearby acoustic context. We propose Local Temporal Bipartite Merging (LTBM), a training-free encoder-space compression method that merges similar nearby audio tokens under an explicit temporal window constraint. Beyond introducing LTBM, we use a controlled Global Merge variant to isolate whether temporal locality itself is a useful inductive bias for audio-token compression. Experiments on AudioCaps, Clotho, and MMAU with Qwen2-Audio show evidence of a task-dependent locality effect: locality-aware merging is more favorable for captioning at several compression settings, especially under stronger compression, while global matching is more competitive for multiple-choice audio understanding. A cross-backbone validation on Audio Flamingo 3 further supports the captioning-side advantage of locality-aware merging under moderate and aggressive compression.
D3S2: Diffusion-Guided Dataset Distillation for Semantic Segmentation
May 24, 2026Dataset distillation (DD) aims to compress large-scale datasets into compact synthetic sets while preserving training efficacy. However, existing studies mainly focus on image classification, leaving dense prediction tasks such as semantic segmentation largely underexplored. In this work, we identify three key challenges for segmentation DD: (i) long-tailed class imbalance, (ii) the need for strict pixel-wise alignment between images and dense labels, and (iii) the high computational cost of optimizing high-resolution data with complex models. To address these challenges, we propose D3S2, a Diffusion-guided Dataset Distillation framework for Semantic Segmentation. Our method adopts a two-stage design. In Class-Balanced Mask Selection, we construct a representative mask set via a greedy strategy that prioritizes underrepresented classes. In Diffusion-Guided Image Synthesis, we employ a pretrained layout-to-image diffusion model to generate images conditioned on the selected masks, naturally ensuring spatial alignment. To further enhance the training utility of synthesized data, we introduce guided diffusion sampling with two complementary objectives: a segmentation-consistency loss for pixel-level alignment, and a class-wise feature matching loss for aligning per-class feature statistics across layers. Extensive experiments demonstrate the superiority of D3S2. Notably, at an extremely compression rate of 1%, our method achieves 24.99% and 35.49% mIoU on ADE20K and COCO-Stuff with Mask2Former (Swin-S), outperforming random selection by 9.34% and 5.70%, respectively.
ActionNex: A Virtual Outage Manager for Cloud
Apr 03, 2026Outage management in large-scale cloud operations remains heavily manual, requiring rapid triage, cross-team coordination, and experience-driven decisions under partial observability. We present \textbf{ActionNex}, a production-grade agentic system that supports end-to-end outage assistance, including real-time updates, knowledge distillation, and role- and stage-conditioned next-best action recommendations. ActionNex ingests multimodal operational signals (e.g., outage content, telemetry, and human communications) and compresses them into critical events that represent meaningful state transitions. It couples this perception layer with a hierarchical memory subsystem: long-term Key-Condition-Action (KCA) knowledge distilled from playbooks and historical executions, episodic memory of prior outages, and working memory of the live context. A reasoning agent aligns current critical events to preconditions, retrieves relevant memories, and generates actionable recommendations; executed human actions serve as an implicit feedback signal to enable continual self-evolution in a human-agent hybrid system. We evaluate ActionNex on eight real Azure outages (8M tokens, 4,000 critical events) using two complementary ground-truth action sets, achieving 71.4\% precision and 52.8-54.8\% recall. The system has been piloted in production and has received positive early feedback.
MobileKernelBench: Can LLMs Write Efficient Kernels for Mobile Devices?
Mar 12, 2026Large language models (LLMs) have demonstrated remarkable capabilities in code generation, yet their potential for generating kernels specifically for mobile de- vices remains largely unexplored. In this work, we extend the scope of automated kernel generation to the mobile domain to investigate the central question: Can LLMs write efficient kernels for mobile devices? To enable systematic investigation, we introduce MobileKernelBench, a comprehensive evaluation framework comprising a benchmark prioritizing operator diversity and cross-framework interoperability, coupled with an automated pipeline that bridges the host-device gap for on-device verification. Leveraging this framework, we conduct extensive evaluation on the CPU backend of Mobile Neural Network (MNN), revealing that current LLMs struggle with the engineering complexity and data scarcity inher-ent to mobile frameworks; standard models and even fine-tuned variants exhibit high compilation failure rates (over 54%) and negligible performance gains due to hallucinations and a lack of domain-specific grounding. To overcome these limitations, we propose the Mobile K ernel A gent (MoKA), a multi-agent system equipped with repository-aware reasoning and a plan-and-execute paradigm.Validated on MobileKernelBench, MoKA achieves state-of-the-art performance, boosting compilation success to 93.7% and enabling 27.4% of generated kernelsto deliver measurable speedups over native libraries.
Q Cache: Visual Attention is Valuable in Less than Half of Decode Layers for Multimodal Large Language Model
Feb 02, 2026Multimodal large language models (MLLMs) are plagued by exorbitant inference costs attributable to the profusion of visual tokens within the vision encoder. The redundant visual tokens engenders a substantial computational load and key-value (KV) cache footprint bottleneck. Existing approaches focus on token-wise optimization, leveraging diverse intricate token pruning techniques to eliminate non-crucial visual tokens. Nevertheless, these methods often unavoidably undermine the integrity of the KV cache, resulting in failures in long-text generation tasks. To this end, we conduct an in-depth investigation towards the attention mechanism of the model from a new perspective, and discern that attention within more than half of all decode layers are semantic similar. Upon this finding, we contend that the attention in certain layers can be streamlined by inheriting the attention from their preceding layers. Consequently, we propose Lazy Attention, an efficient attention mechanism that enables cross-layer sharing of similar attention patterns. It ingeniously reduces layer-wise redundant computation in attention. In Lazy Attention, we develop a novel layer-shared cache, Q Cache, tailored for MLLMs, which facilitates the reuse of queries across adjacent layers. In particular, Q Cache is lightweight and fully compatible with existing inference frameworks, including Flash Attention and KV cache. Additionally, our method is highly flexible as it is orthogonal to existing token-wise techniques and can be deployed independently or combined with token pruning approaches. Empirical evaluations on multiple benchmarks demonstrate that our method can reduce KV cache usage by over 35% and achieve 1.5x throughput improvement, while sacrificing only approximately 1% of performance on various MLLMs. Compared with SOTA token-wise methods, our technique achieves superior accuracy preservation.
Learn Before Represent: Bridging Generative and Contrastive Learning for Domain-Specific LLM Embeddings
Jan 16, 2026Large Language Models (LLMs) adapted via contrastive learning excel in general representation learning but struggle in vertical domains like chemistry and law, primarily due to a lack of domain-specific knowledge. This work identifies a core bottleneck: the prevailing ``LLM+CL'' paradigm focuses on semantic alignment but cannot perform knowledge acquisition, leading to failures on specialized terminology. To bridge this gap, we propose Learn Before Represent (LBR), a novel two-stage framework. LBR first injects domain knowledge via an Information Bottleneck-Constrained Generative Learning stage, preserving the LLM's causal attention to maximize knowledge acquisition while compressing semantics. It then performs Generative-Refined Contrastive Learning on the compressed representations for alignment. This approach maintains architectural consistency and resolves the objective conflict between generative and contrastive learning. Extensive experiments on medical, chemistry, and code retrieval tasks show that LBR significantly outperforms strong baselines. Our work establishes a new paradigm for building accurate and robust representations in vertical domains.
SemanticGen: Video Generation in Semantic Space
Dec 24, 2025

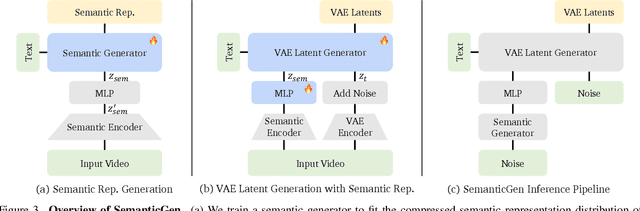

State-of-the-art video generative models typically learn the distribution of video latents in the VAE space and map them to pixels using a VAE decoder. While this approach can generate high-quality videos, it suffers from slow convergence and is computationally expensive when generating long videos. In this paper, we introduce SemanticGen, a novel solution to address these limitations by generating videos in the semantic space. Our main insight is that, due to the inherent redundancy in videos, the generation process should begin in a compact, high-level semantic space for global planning, followed by the addition of high-frequency details, rather than directly modeling a vast set of low-level video tokens using bi-directional attention. SemanticGen adopts a two-stage generation process. In the first stage, a diffusion model generates compact semantic video features, which define the global layout of the video. In the second stage, another diffusion model generates VAE latents conditioned on these semantic features to produce the final output. We observe that generation in the semantic space leads to faster convergence compared to the VAE latent space. Our method is also effective and computationally efficient when extended to long video generation. Extensive experiments demonstrate that SemanticGen produces high-quality videos and outperforms state-of-the-art approaches and strong baselines.
Training-Free Multi-View Extension of IC-Light for Textual Position-Aware Scene Relighting
Nov 17, 2025We introduce GS-Light, an efficient, textual position-aware pipeline for text-guided relighting of 3D scenes represented via Gaussian Splatting (3DGS). GS-Light implements a training-free extension of a single-input diffusion model to handle multi-view inputs. Given a user prompt that may specify lighting direction, color, intensity, or reference objects, we employ a large vision-language model (LVLM) to parse the prompt into lighting priors. Using off-the-shelf estimators for geometry and semantics (depth, surface normals, and semantic segmentation), we fuse these lighting priors with view-geometry constraints to compute illumination maps and generate initial latent codes for each view. These meticulously derived init latents guide the diffusion model to generate relighting outputs that more accurately reflect user expectations, especially in terms of lighting direction. By feeding multi-view rendered images, along with the init latents, into our multi-view relighting model, we produce high-fidelity, artistically relit images. Finally, we fine-tune the 3DGS scene with the relit appearance to obtain a fully relit 3D scene. We evaluate GS-Light on both indoor and outdoor scenes, comparing it to state-of-the-art baselines including per-view relighting, video relighting, and scene editing methods. Using quantitative metrics (multi-view consistency, imaging quality, aesthetic score, semantic similarity, etc.) and qualitative assessment (user studies), GS-Light demonstrates consistent improvements over baselines. Code and assets will be made available upon publication.
No Pixel Left Behind: A Detail-Preserving Architecture for Robust High-Resolution AI-Generated Image Detection
Aug 24, 2025The rapid growth of high-resolution, meticulously crafted AI-generated images poses a significant challenge to existing detection methods, which are often trained and evaluated on low-resolution, automatically generated datasets that do not align with the complexities of high-resolution scenarios. A common practice is to resize or center-crop high-resolution images to fit standard network inputs. However, without full coverage of all pixels, such strategies risk either obscuring subtle, high-frequency artifacts or discarding information from uncovered regions, leading to input information loss. In this paper, we introduce the High-Resolution Detail-Aggregation Network (HiDA-Net), a novel framework that ensures no pixel is left behind. We use the Feature Aggregation Module (FAM), which fuses features from multiple full-resolution local tiles with a down-sampled global view of the image. These local features are aggregated and fused with global representations for final prediction, ensuring that native-resolution details are preserved and utilized for detection. To enhance robustness against challenges such as localized AI manipulations and compression, we introduce Token-wise Forgery Localization (TFL) module for fine-grained spatial sensitivity and JPEG Quality Factor Estimation (QFE) module to disentangle generative artifacts from compression noise explicitly. Furthermore, to facilitate future research, we introduce HiRes-50K, a new challenging benchmark consisting of 50,568 images with up to 64 megapixels. Extensive experiments show that HiDA-Net achieves state-of-the-art, increasing accuracy by over 13% on the challenging Chameleon dataset and 10% on our HiRes-50K.