 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocality Matters for Training-Free Audio Token Compression in Audio-Language Models
May 24, 2026Audio-language models (ALMs) are increasingly used for audio captioning, question answering, and open-ended audio understanding, but their inference cost remains high when audio inputs are represented as long prefix-token sequences. These audio prefixes consume context budget, increase memory usage, and make deployment harder in resource-constrained or latency-sensitive settings. Existing training-free audio-token reduction methods mainly rely on fixed pooling or score-based pruning. Fixed pooling is content-agnostic, while score-based pruning can preserve isolated salient tokens but discard nearby acoustic context. We propose Local Temporal Bipartite Merging (LTBM), a training-free encoder-space compression method that merges similar nearby audio tokens under an explicit temporal window constraint. Beyond introducing LTBM, we use a controlled Global Merge variant to isolate whether temporal locality itself is a useful inductive bias for audio-token compression. Experiments on AudioCaps, Clotho, and MMAU with Qwen2-Audio show evidence of a task-dependent locality effect: locality-aware merging is more favorable for captioning at several compression settings, especially under stronger compression, while global matching is more competitive for multiple-choice audio understanding. A cross-backbone validation on Audio Flamingo 3 further supports the captioning-side advantage of locality-aware merging under moderate and aggressive compression.
Learn Before Represent: Bridging Generative and Contrastive Learning for Domain-Specific LLM Embeddings
Jan 16, 2026Large Language Models (LLMs) adapted via contrastive learning excel in general representation learning but struggle in vertical domains like chemistry and law, primarily due to a lack of domain-specific knowledge. This work identifies a core bottleneck: the prevailing ``LLM+CL'' paradigm focuses on semantic alignment but cannot perform knowledge acquisition, leading to failures on specialized terminology. To bridge this gap, we propose Learn Before Represent (LBR), a novel two-stage framework. LBR first injects domain knowledge via an Information Bottleneck-Constrained Generative Learning stage, preserving the LLM's causal attention to maximize knowledge acquisition while compressing semantics. It then performs Generative-Refined Contrastive Learning on the compressed representations for alignment. This approach maintains architectural consistency and resolves the objective conflict between generative and contrastive learning. Extensive experiments on medical, chemistry, and code retrieval tasks show that LBR significantly outperforms strong baselines. Our work establishes a new paradigm for building accurate and robust representations in vertical domains.
OpenRoboCare: A Multimodal Multi-Task Expert Demonstration Dataset for Robot Caregiving
Nov 17, 2025We present OpenRoboCare, a multimodal dataset for robot caregiving, capturing expert occupational therapist demonstrations of Activities of Daily Living (ADLs). Caregiving tasks involve complex physical human-robot interactions, requiring precise perception under occlusions, safe physical contact, and long-horizon planning. While recent advances in robot learning from demonstrations have shown promise, there is a lack of a large-scale, diverse, and expert-driven dataset that captures real-world caregiving routines. To address this gap, we collect data from 21 occupational therapists performing 15 ADL tasks on two manikins. The dataset spans five modalities: RGB-D video, pose tracking, eye-gaze tracking, task and action annotations, and tactile sensing, providing rich multimodal insights into caregiver movement, attention, force application, and task execution strategies. We further analyze expert caregiving principles and strategies, offering insights to improve robot efficiency and task feasibility. Additionally, our evaluations demonstrate that OpenRoboCare presents challenges for state-of-the-art robot perception and human activity recognition methods, both critical for developing safe and adaptive assistive robots, highlighting the value of our contribution. See our website for additional visualizations: https://emprise.cs.cornell.edu/robo-care/.
SAGE: Semantic-Aware Shared Sampling for Efficient Diffusion
Sep 19, 2025Diffusion models manifest evident benefits across diverse domains, yet their high sampling cost, requiring dozens of sequential model evaluations, remains a major limitation. Prior efforts mainly accelerate sampling via optimized solvers or distillation, which treat each query independently. In contrast, we reduce total number of steps by sharing early-stage sampling across semantically similar queries. To enable such efficiency gains without sacrificing quality, we propose SAGE, a semantic-aware shared sampling framework that integrates a shared sampling scheme for efficiency and a tailored training strategy for quality preservation. Extensive experiments show that SAGE reduces sampling cost by 25.5%, while improving generation quality with 5.0% lower FID, 5.4% higher CLIP, and 160% higher diversity over baselines.
Content-Rich AIGC Video Quality Assessment via Intricate Text Alignment and Motion-Aware Consistency
Feb 06, 2025
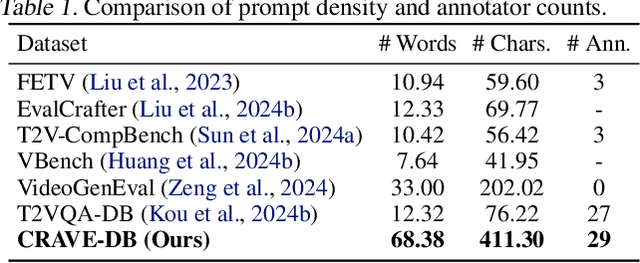

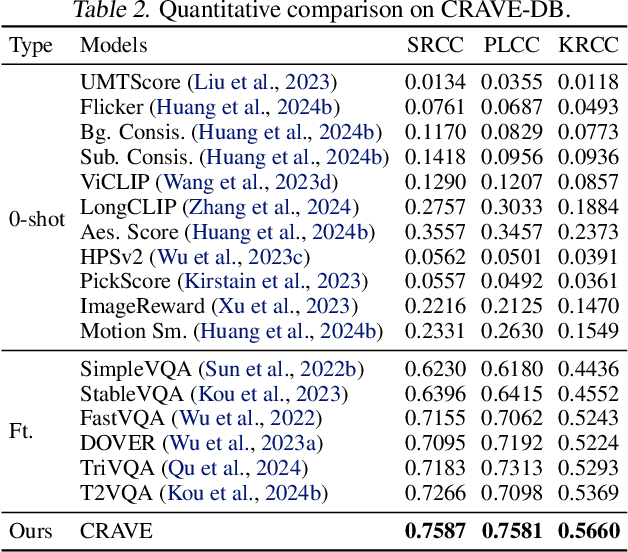
The advent of next-generation video generation models like \textit{Sora} poses challenges for AI-generated content (AIGC) video quality assessment (VQA). These models substantially mitigate flickering artifacts prevalent in prior models, enable longer and complex text prompts and generate longer videos with intricate, diverse motion patterns. Conventional VQA methods designed for simple text and basic motion patterns struggle to evaluate these content-rich videos. To this end, we propose \textbf{CRAVE} (\underline{C}ontent-\underline{R}ich \underline{A}IGC \underline{V}ideo \underline{E}valuator), specifically for the evaluation of Sora-era AIGC videos. CRAVE proposes the multi-granularity text-temporal fusion that aligns long-form complex textual semantics with video dynamics. Additionally, CRAVE leverages the hybrid motion-fidelity modeling to assess temporal artifacts. Furthermore, given the straightforward prompts and content in current AIGC VQA datasets, we introduce \textbf{CRAVE-DB}, a benchmark featuring content-rich videos from next-generation models paired with elaborate prompts. Extensive experiments have shown that the proposed CRAVE achieves excellent results on multiple AIGC VQA benchmarks, demonstrating a high degree of alignment with human perception. All data and code will be publicly available at https://github.com/littlespray/CRAVE.
Dynamic Token Reduction during Generation for Vision Language Models
Jan 24, 2025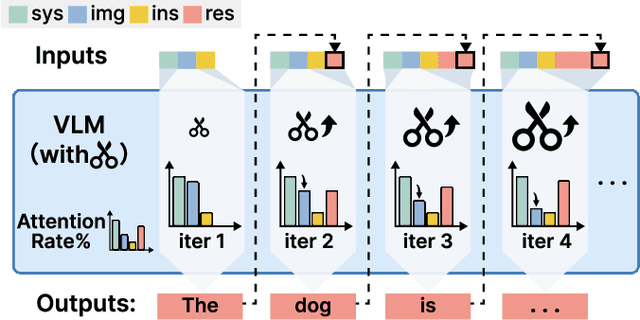
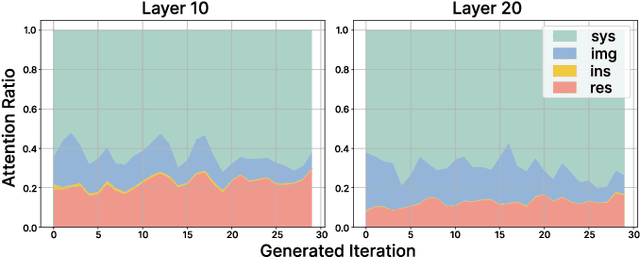
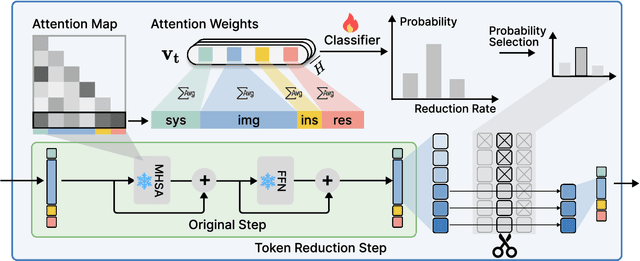

Vision-Language Models (VLMs) have achieved notable success in multimodal tasks but face practical limitations due to the quadratic complexity of decoder attention mechanisms and autoregressive generation. Existing methods like FASTV and VTW have achieved notable results in reducing redundant visual tokens, but these approaches focus on pruning tokens in a single forward pass without systematically analyzing the redundancy of visual tokens throughout the entire generation process. In this paper, we introduce a dynamic pruning strategy tailored for VLMs, namedDynamic Rate (DyRate), which progressively adjusts the compression rate during generation. Our analysis of the distribution of attention reveals that the importance of visual tokens decreases throughout the generation process, inspiring us to adopt a more aggressive compression rate. By integrating a lightweight predictor based on attention distribution, our approach enables flexible adjustment of pruning rates based on the attention distribution. Our experimental results demonstrate that our method not only reduces computational demands but also maintains the quality of responses.
Enhancing Facial Consistency in Conditional Video Generation via Facial Landmark Transformation
Dec 12, 2024

Landmark-guided character animation generation is an important field. Generating character animations with facial features consistent with a reference image remains a significant challenge in conditional video generation, especially involving complex motions like dancing. Existing methods often fail to maintain facial feature consistency due to mismatches between the facial landmarks extracted from source videos and the target facial features in the reference image. To address this problem, we propose a facial landmark transformation method based on the 3D Morphable Model (3DMM). We obtain transformed landmarks that align with the target facial features by reconstructing 3D faces from the source landmarks and adjusting the 3DMM parameters to match the reference image. Our method improves the facial consistency between the generated videos and the reference images, effectively improving the facial feature mismatch problem.
KnowledgeSG: Privacy-Preserving Synthetic Text Generation with Knowledge Distillation from Server
Oct 10, 2024



The success of large language models (LLMs) facilitate many parties to fine-tune LLMs on their own private data. However, this practice raises privacy concerns due to the memorization of LLMs. Existing solutions, such as utilizing synthetic data for substitution, struggle to simultaneously improve performance and preserve privacy. They either rely on a local model for generation, resulting in a performance decline, or take advantage of APIs, directly exposing the data to API servers. To address this issue, we propose KnowledgeSG, a novel client-server framework which enhances synthetic data quality and improves model performance while ensuring privacy. We achieve this by learning local knowledge from the private data with differential privacy (DP) and distilling professional knowledge from the server. Additionally, inspired by federated learning, we transmit models rather than data between the client and server to prevent privacy leakage. Extensive experiments in medical and financial domains demonstrate the effectiveness of KnowledgeSG. Our code is now publicly available at https://github.com/wwh0411/KnowledgeSG.
E-Bench: Subjective-Aligned Benchmark Suite for Text-Driven Video Editing Quality Assessment
Aug 21, 2024



Text-driven video editing has recently experienced rapid development. Despite this, evaluating edited videos remains a considerable challenge. Current metrics tend to fail to align with human perceptions, and effective quantitative metrics for video editing are still notably absent. To address this, we introduce E-Bench, a benchmark suite tailored to the assessment of text-driven video editing. This suite includes E-Bench DB, a video quality assessment (VQA) database for video editing. E-Bench DB encompasses a diverse set of source videos featuring various motions and subjects, along with multiple distinct editing prompts, editing results from 8 different models, and the corresponding Mean Opinion Scores (MOS) from 24 human annotators. Based on E-Bench DB, we further propose E-Bench QA, a quantitative human-aligned measurement for the text-driven video editing task. In addition to the aesthetic, distortion, and other visual quality indicators that traditional VQA methods emphasize, E-Bench QA focuses on the text-video alignment and the relevance modeling between source and edited videos. It proposes a new assessment network for video editing that attains superior performance in alignment with human preferences. To the best of our knowledge, E-Bench introduces the first quality assessment dataset for video editing and an effective subjective-aligned quantitative metric for this domain. All data and code will be publicly available at https://github.com/littlespray/E-Bench.
FALIP: Visual Prompt as Foveal Attention Boosts CLIP Zero-Shot Performance
Jul 08, 2024



CLIP has achieved impressive zero-shot performance after pre-training on a large-scale dataset consisting of paired image-text data. Previous works have utilized CLIP by incorporating manually designed visual prompts like colored circles and blur masks into the images to guide the model's attention, showing enhanced zero-shot performance in downstream tasks. Although these methods have achieved promising results, they inevitably alter the original information of the images, which can lead to failure in specific tasks. We propose a train-free method Foveal-Attention CLIP (FALIP), which adjusts the CLIP's attention by inserting foveal attention masks into the multi-head self-attention module. We demonstrate FALIP effectively boosts CLIP zero-shot performance in tasks such as referring expressions comprehension, image classification, and 3D point cloud recognition. Experimental results further show that FALIP outperforms existing methods on most metrics and can augment current methods to enhance their performance.