 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReWind: Understanding Long Videos with Instructed Learnable Memory
Nov 23, 2024Vision-Language Models (VLMs) are crucial for applications requiring integrated understanding textual and visual information. However, existing VLMs struggle with long videos due to computational inefficiency, memory limitations, and difficulties in maintaining coherent understanding across extended sequences. To address these challenges, we introduce ReWind, a novel memory-based VLM designed for efficient long video understanding while preserving temporal fidelity. ReWind operates in a two-stage framework. In the first stage, ReWind maintains a dynamic learnable memory module with a novel \textbf{read-perceive-write} cycle that stores and updates instruction-relevant visual information as the video unfolds. This module utilizes learnable queries and cross-attentions between memory contents and the input stream, ensuring low memory requirements by scaling linearly with the number of tokens. In the second stage, we propose an adaptive frame selection mechanism guided by the memory content to identify instruction-relevant key moments. It enriches the memory representations with detailed spatial information by selecting a few high-resolution frames, which are then combined with the memory contents and fed into a Large Language Model (LLM) to generate the final answer. We empirically demonstrate ReWind's superior performance in visual question answering (VQA) and temporal grounding tasks, surpassing previous methods on long video benchmarks. Notably, ReWind achieves a +13\% score gain and a +12\% accuracy improvement on the MovieChat-1K VQA dataset and an +8\% mIoU increase on Charades-STA for temporal grounding.
Towards the Desirable Decision Boundary by Moderate-Margin Adversarial Training
Jul 16, 2022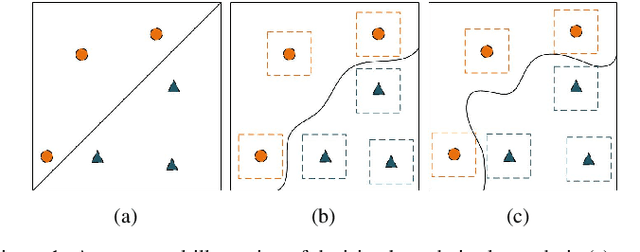
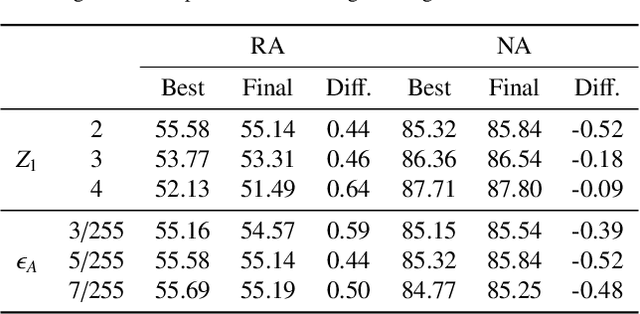

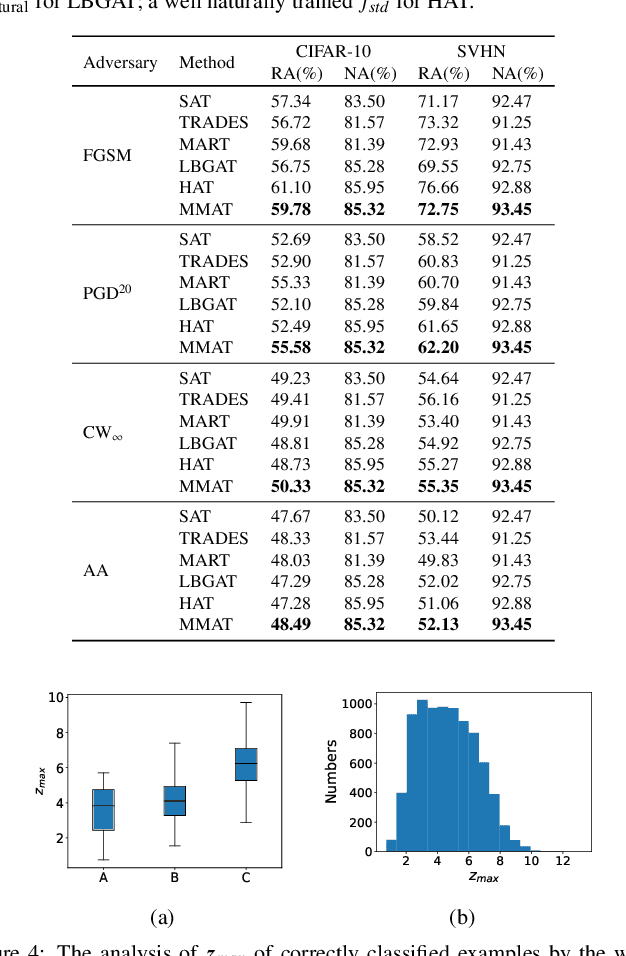
Adversarial training, as one of the most effective defense methods against adversarial attacks, tends to learn an inclusive decision boundary to increase the robustness of deep learning models. However, due to the large and unnecessary increase in the margin along adversarial directions, adversarial training causes heavy cross-over between natural examples and adversarial examples, which is not conducive to balancing the trade-off between robustness and natural accuracy. In this paper, we propose a novel adversarial training scheme to achieve a better trade-off between robustness and natural accuracy. It aims to learn a moderate-inclusive decision boundary, which means that the margins of natural examples under the decision boundary are moderate. We call this scheme Moderate-Margin Adversarial Training (MMAT), which generates finer-grained adversarial examples to mitigate the cross-over problem. We also take advantage of logits from a teacher model that has been well-trained to guide the learning of our model. Finally, MMAT achieves high natural accuracy and robustness under both black-box and white-box attacks. On SVHN, for example, state-of-the-art robustness and natural accuracy are achieved.
Hessian-Free Second-Order Adversarial Examples for Adversarial Learning
Jul 04, 2022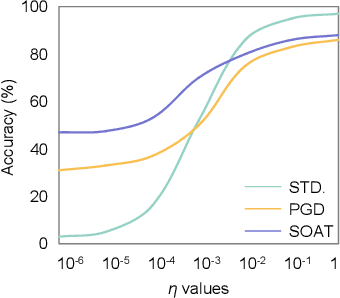
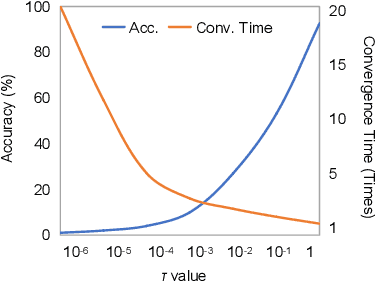
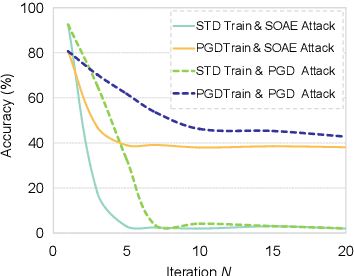
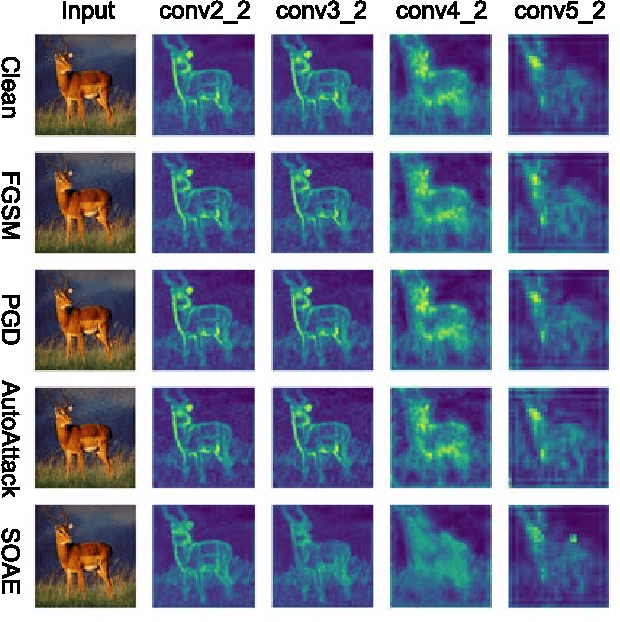
Recent studies show deep neural networks (DNNs) are extremely vulnerable to the elaborately designed adversarial examples. Adversarial learning with those adversarial examples has been proved as one of the most effective methods to defend against such an attack. At present, most existing adversarial examples generation methods are based on first-order gradients, which can hardly further improve models' robustness, especially when facing second-order adversarial attacks. Compared with first-order gradients, second-order gradients provide a more accurate approximation of the loss landscape with respect to natural examples. Inspired by this, our work crafts second-order adversarial examples and uses them to train DNNs. Nevertheless, second-order optimization involves time-consuming calculation for Hessian-inverse. We propose an approximation method through transforming the problem into an optimization in the Krylov subspace, which remarkably reduce the computational complexity to speed up the training procedure. Extensive experiments conducted on the MINIST and CIFAR-10 datasets show that our adversarial learning with second-order adversarial examples outperforms other fisrt-order methods, which can improve the model robustness against a wide range of attacks.
Versailles-FP dataset: Wall Detection in Ancient
Mar 14, 2021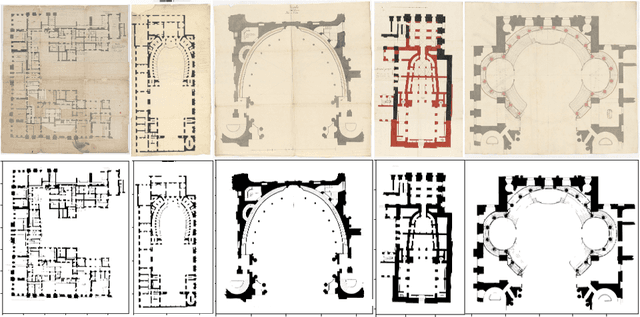

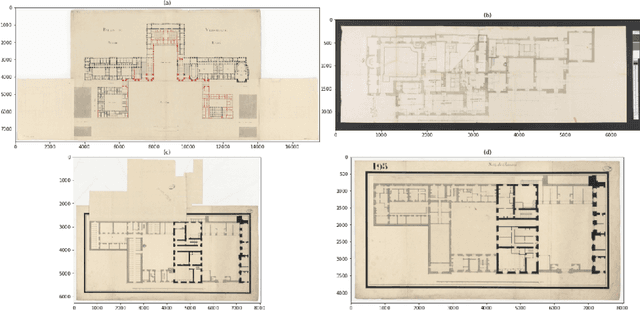

Access to historical monuments' floor plans over a time period is necessary to understand the architectural evolution and history. Such knowledge bases also helps to rebuild the history by establishing connection between different event, person and facts which are once part of the buildings. Since the two-dimensional plans do not capture the entire space, 3D modeling sheds new light on the reading of these unique archives and thus opens up great perspectives for understanding the ancient states of the monument. Since the first step in the building's or monument's 3D model is the wall detection in the floor plan, we introduce in this paper the new and unique Versailles FP dataset of wall groundtruthed images of the Versailles Palace dated between 17th and 18th century. The dataset's wall masks are generated using an automatic approach based on multi directional steerable filters. The generated wall masks are then validated and corrected manually. We validate our approach of wall mask generation in state-of-the-art modern datasets. Finally we propose a U net based convolutional framework for wall detection. Our method achieves state of the art result surpassing fully connected network based approach.
Towards Speeding up Adversarial Training in Latent Spaces
Feb 01, 2021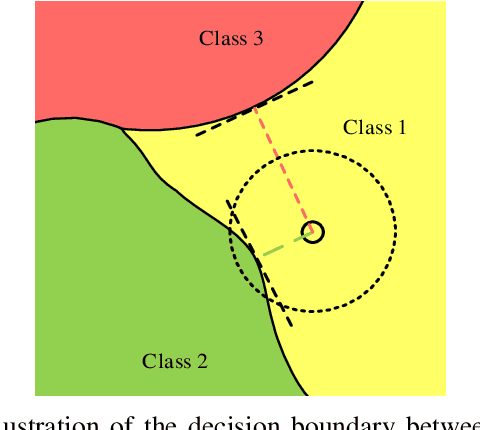
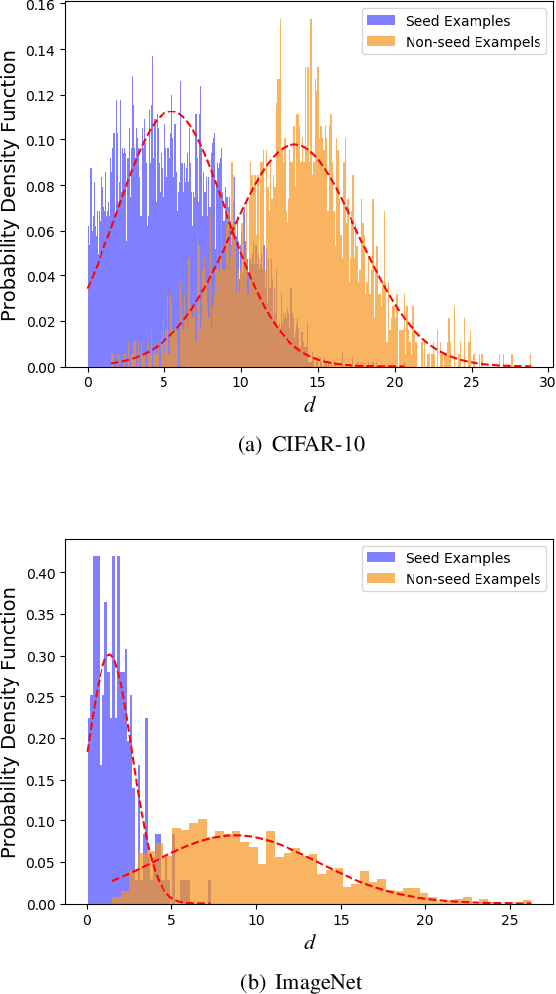
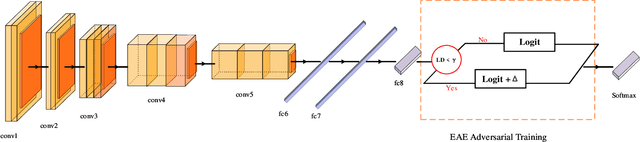
Adversarial training is wildly considered as the most effective way to defend against adversarial examples. However, existing adversarial training methods consume unbearable time cost, since they need to generate adversarial examples in the input space, which accounts for the main part of total time-consuming. For speeding up the training process, we propose a novel adversarial training method that does not need to generate real adversarial examples. We notice that a clean example is closer to the decision boundary of the class with the second largest logit component than any other class besides its own class. Thus, by adding perturbations to logits to generate Endogenous Adversarial Examples(EAEs) -- adversarial examples in the latent space, it can avoid calculating gradients to speed up the training process. We further gain a deep insight into the existence of EAEs by the theory of manifold. To guarantee the added perturbation is within the range of constraint, we use statistical distributions to select seed examples to craft EAEs. Extensive experiments are conducted on CIFAR-10 and ImageNet, and the results show that compare with state-of-the-art "Free" and "Fast" methods, our EAE adversarial training not only shortens the training time, but also enhances the robustness of the model. Moreover, the EAE adversarial training has little impact on the accuracy of clean examples than the existing methods.
TEAM: We Need More Powerful Adversarial Examples for DNNs
Aug 10, 2020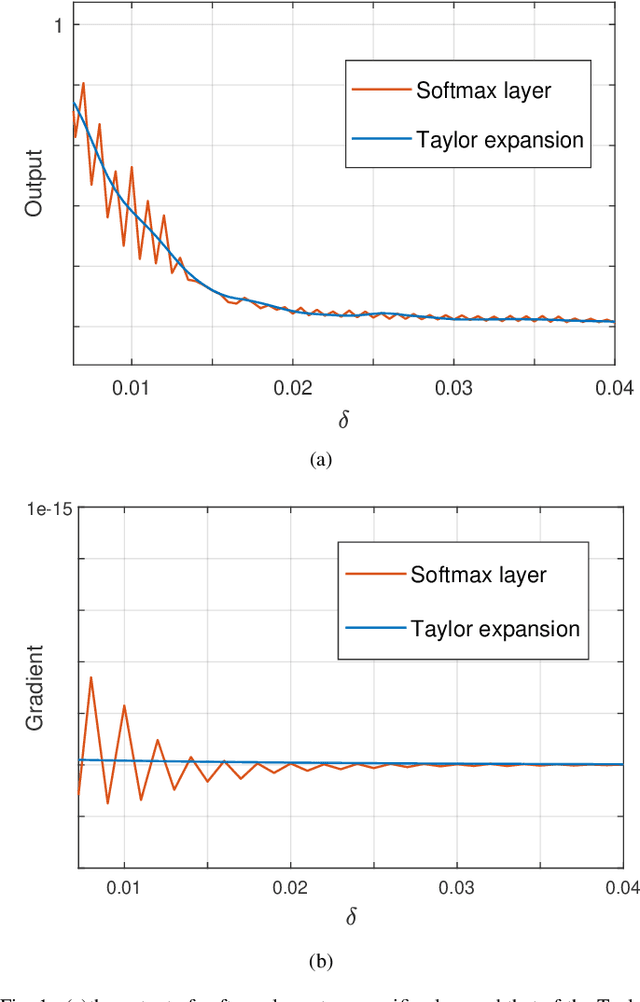

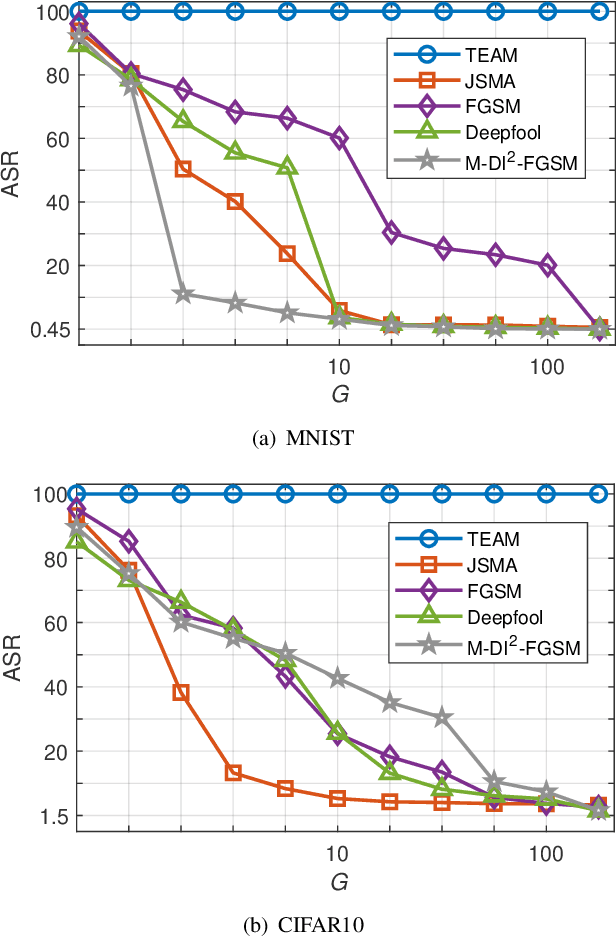

Although deep neural networks (DNNs) have achieved success in many application fields, it is still vulnerable to imperceptible adversarial examples that can lead to misclassification of DNNs easily. To overcome this challenge, many defensive methods are proposed. Indeed, a powerful adversarial example is a key benchmark to measure these defensive mechanisms. In this paper, we propose a novel method (TEAM, Taylor Expansion-Based Adversarial Methods) to generate more powerful adversarial examples than previous methods. The main idea is to craft adversarial examples by minimizing the confidence of the ground-truth class under untargeted attacks or maximizing the confidence of the target class under targeted attacks. Specifically, we define the new objective functions that approximate DNNs by using the second-order Taylor expansion within a tiny neighborhood of the input. Then the Lagrangian multiplier method is used to obtain the optimize perturbations for these objective functions. To decrease the amount of computation, we further introduce the Gauss-Newton (GN) method to speed it up. Finally, the experimental result shows that our method can reliably produce adversarial examples with 100% attack success rate (ASR) while only by smaller perturbations. In addition, the adversarial example generated with our method can defeat defensive distillation based on gradient masking.
A Unified Multilingual Handwriting Recognition System using multigrams sub-lexical units
Aug 28, 2018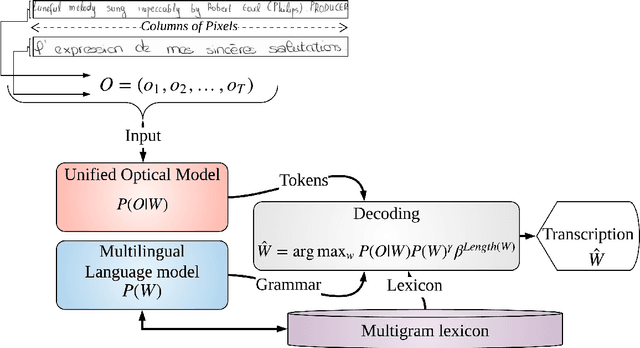

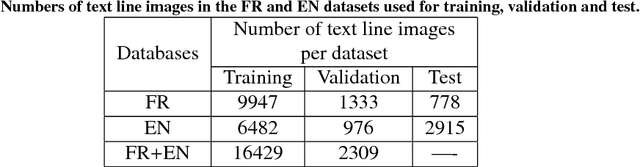
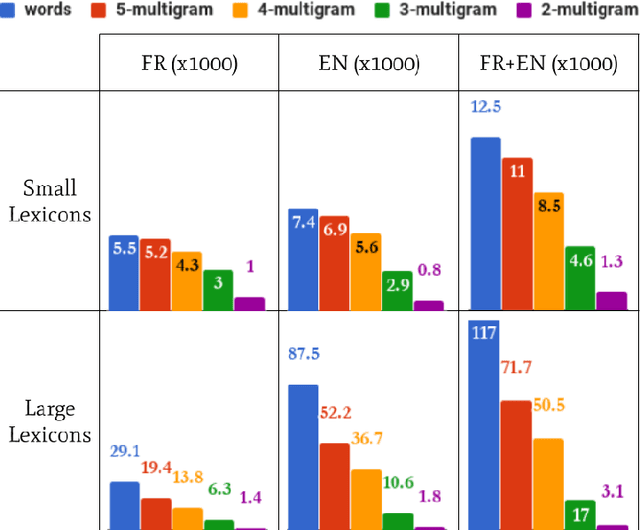
We address the design of a unified multilingual system for handwriting recognition. Most of multi- lingual systems rests on specialized models that are trained on a single language and one of them is selected at test time. While some recognition systems are based on a unified optical model, dealing with a unified language model remains a major issue, as traditional language models are generally trained on corpora composed of large word lexicons per language. Here, we bring a solution by con- sidering language models based on sub-lexical units, called multigrams. Dealing with multigrams strongly reduces the lexicon size and thus decreases the language model complexity. This makes pos- sible the design of an end-to-end unified multilingual recognition system where both a single optical model and a single language model are trained on all the languages. We discuss the impact of the language unification on each model and show that our system reaches state-of-the-art methods perfor- mance with a strong reduction of the complexity.
* preprint
A syllable based model for handwriting recognition
Aug 22, 2018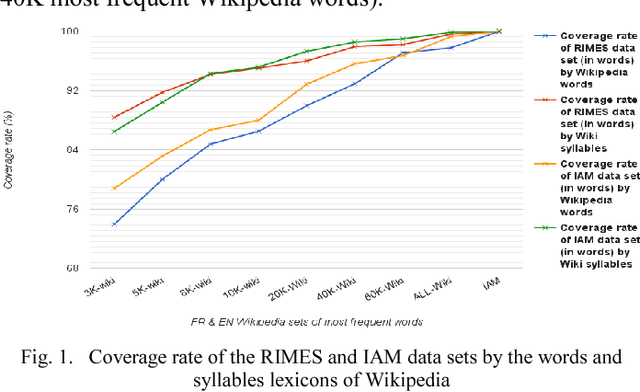
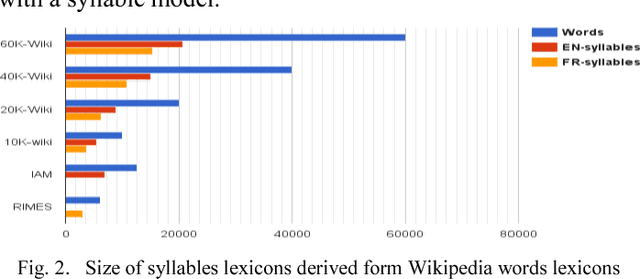
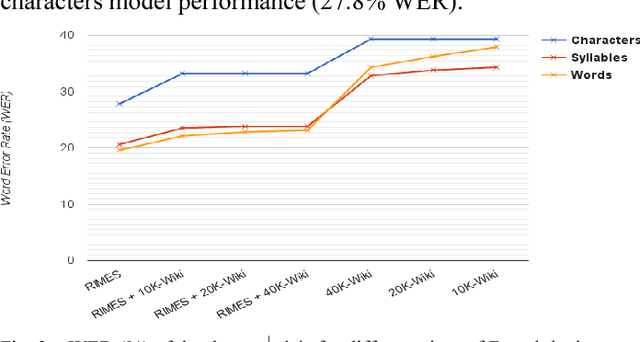
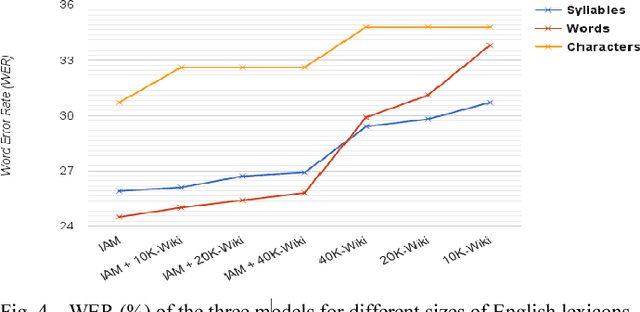
In this paper, we introduce a new modeling approach of texts for handwriting recognition based on syllables. We propose a supervised syllabification approach for the French and English languages for building a vocabulary of syllables. Statistical n-gram language models of syllables are trained on French and English Wikipedia corpora. The handwriting recognition system, based on optical HMM context independent character models, performs a two pass decoding, integrating the proposed syllabic models. Evaluation is carried out on the French RIMES dataset and English IAM dataset by analyzing the performance for various coverage of the syllable models. We also compare the syllable models with lexicon and character n-gram models. The proposed approach reaches interesting performances thanks to its capacity to cover a large amount of out of vocabulary words working with a limited amount of syllables combined with statistical n-gram of reasonable order.