 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling State-Space Models from Lines to Paragraphs: An Ablation of Mamba-based OCR
Jun 22, 2026End-to-end OCR increasingly relies on autoregressive sequence models, where the quadratic cost of Transformer attention limits efficient transcription of long, paragraph-level text. State-Space Models (SSMs) such as Mamba offer linear-time decoding and have recently been shown to match Transformer accuracy on printed historical lines, but their behavior as sequences grow from short lines to full paragraphs, and their generalization to handwriting, remain poorly understood. We study how a Mamba-based OCR recognizer scales from lines to paragraphs. We first conduct a systematic exploration of its four core hyperparameters (decoder depth, state dimension, expansion factor, and connector depth) on synthetic paragraphs from 100 to 1,000 characters, identifying the recurrent state dimension and the expansion factor as the dominant levers for long-sequence accuracy. We then compare the recognizer against a Transformer baseline trained under an identical protocol. On clean synthetic paragraphs, both models stay below 1% CER at every length while the SSM runs 1.4 to 4.5 times faster, the speedup growing with sequence length. On real handwriting, however, the SSM lags clearly behind: it reaches 8.2% CER on IAM lines and 10.0% on IAM paragraphs, against 4.2% and 3.5% for the Transformer baseline. Through controlled experiments we show that a substantial part of this gap stems from data scarcity rather than from an intrinsic architectural limit: the autoregressive SSM decoder is markedly data-hungry on long sequences. Our study clarifies when SSMs are a practical choice for large-scale document transcription and when they are not.
FastTab: A Fast Table Recognizer with a Tiny Recursive Module and 1D Transformers
May 21, 2026Table structure recognition (TSR) requires both table-level coherence (row/column counts, headers, spanning cells) and precise separator localization. We introduce FastTab, a grid-centric TSR model that avoids autoregressive HTML decoding by combining (i) a lightweight Tiny Recursive Module (TRM) for global reasoning and (ii) axial 1D Transformer encoders that capture long-range dependencies along rows and columns. The model predicts row/column counts, header rows, and separators to construct a grid, then infers rowspan/colspan using ROI-aligned cell features. Across four benchmarks (PubTabNet, FinTabNet, PubTables-1M, and SciTSR), FastTab achieves competitive structure recovery performance while operating at low-latency inference. We further study robustness under pixel-level anonymisation and show an extension to curved separators for camera-captured documents. The source code will be made publicly available at https://github.com/hamdilaziz/FastTab .
A Benchmark of State-Space Models vs. Transformers and BiLSTM-based Models for Historical Newspaper OCR
Apr 01, 2026End-to-end OCR for historical newspapers remains challenging, as models must handle long text sequences, degraded print quality, and complex layouts. While Transformer-based recognizers dominate current research, their quadratic complexity limits efficient paragraph-level transcription and large-scale deployment. We investigate linear-time State-Space Models (SSMs), specifically Mamba, as a scalable alternative to Transformer-based sequence modeling for OCR. We present to our knowledge, the first OCR architecture based on SSMs, combining a CNN visual encoder with bi-directional and autoregressive Mamba sequence modeling, and conduct a large-scale benchmark comparing SSMs with Transformer- and BiLSTM-based recognizers. Multiple decoding strategies (CTC, autoregressive, and non-autoregressive) are evaluated under identical training conditions alongside strong neural baselines (VAN, DAN, DANIEL) and widely used off-the-shelf OCR engines (PERO-OCR, Tesseract OCR, TrOCR, Gemini). Experiments on historical newspapers from the Bibliothèque nationale du Luxembourg, with newly released >99% verified gold-standard annotations, and cross-dataset tests on Fraktur and Antiqua lines, show that all neural models achieve low error rates (~2% CER), making computational efficiency the main differentiator. Mamba-based models maintain competitive accuracy while halving inference time and exhibiting superior memory scaling (1.26x vs 2.30x growth at 1000 chars), reaching 6.07% CER at the severely degraded paragraph level compared to 5.24% for DAN, while remaining 2.05x faster. We release code, trained models, and standardized evaluation protocols to enable reproducible research and guide practitioners in large-scale cultural heritage OCR.
Few-shot Writer Adaptation via Multimodal In-Context Learning
Mar 31, 2026While state-of-the-art Handwritten Text Recognition (HTR) models perform well on standard benchmarks, they frequently struggle with writers exhibiting highly specific styles that are underrepresented in the training data. To handle unseen and atypical writers, writer adaptation techniques personalize HTR models to individual handwriting styles. Leading writer adaptation methods require either offline fine-tuning or parameter updates at inference time, both involving gradient computation and backpropagation, which increase computational costs and demand careful hyperparameter tuning. In this work, we propose a novel context-driven HTR framework3 inspired by multimodal in-context learning, enabling inference-time writer adaptation using only a few examples from the target writer without any parameter updates. We further demonstrate the impact of context length, design a compact 8M-parameter CNN-Transformer that enables few-shot in-context adaptation, and show that combining context-driven and standard OCR training strategies leads to complementary improvements. Experiments on IAM and RIMES validate our approach with Character Error Rates of 3.92% and 2.34%, respectively, surpassing all writer-independent HTR models without requiring any parameter updates at inference time.
Classifying the Unknown: In-Context Learning for Open-Vocabulary Text and Symbol Recognition
Apr 09, 2025We introduce Rosetta, a multimodal model that leverages Multimodal In-Context Learning (MICL) to classify sequences of novel script patterns in documents by leveraging minimal examples, thus eliminating the need for explicit retraining. To enhance contextual learning, we designed a dataset generation process that ensures varying degrees of contextual informativeness, improving the model's adaptability in leveraging context across different scenarios. A key strength of our method is the use of a Context-Aware Tokenizer (CAT), which enables open-vocabulary classification. This allows the model to classify text and symbol patterns across an unlimited range of classes, extending its classification capabilities beyond the scope of its training alphabet of patterns. As a result, it unlocks applications such as the recognition of new alphabets and languages. Experiments on synthetic datasets demonstrate the potential of Rosetta to successfully classify Out-Of-Distribution visual patterns and diverse sets of alphabets and scripts, including but not limited to Chinese, Greek, Russian, French, Spanish, and Japanese.
VISTA-OCR: Towards generative and interactive end to end OCR models
Apr 04, 2025We introduce \textbf{VISTA-OCR} (Vision and Spatially-aware Text Analysis OCR), a lightweight architecture that unifies text detection and recognition within a single generative model. Unlike conventional methods that require separate branches with dedicated parameters for text recognition and detection, our approach leverages a Transformer decoder to sequentially generate text transcriptions and their spatial coordinates in a unified branch. Built on an encoder-decoder architecture, VISTA-OCR is progressively trained, starting with the visual feature extraction phase, followed by multitask learning with multimodal token generation. To address the increasing demand for versatile OCR systems capable of advanced tasks, such as content-based text localization \ref{content_based_localization}, we introduce new prompt-controllable OCR tasks during pre-training.To enhance the model's capabilities, we built a new dataset composed of real-world examples enriched with bounding box annotations and synthetic samples. Although recent Vision Large Language Models (VLLMs) can efficiently perform these tasks, their high computational cost remains a barrier for practical deployment. In contrast, our VISTA$_{\text{omni}}$ variant processes both handwritten and printed documents with only 150M parameters, interactively, by prompting. Extensive experiments on multiple datasets demonstrate that VISTA-OCR achieves better performance compared to state-of-the-art specialized models on standard OCR tasks while showing strong potential for more sophisticated OCR applications, addressing the growing need for interactive OCR systems. All code and annotations for VISTA-OCR will be made publicly available upon acceptance.
DANIEL: A fast Document Attention Network for Information Extraction and Labelling of handwritten documents
Jul 12, 2024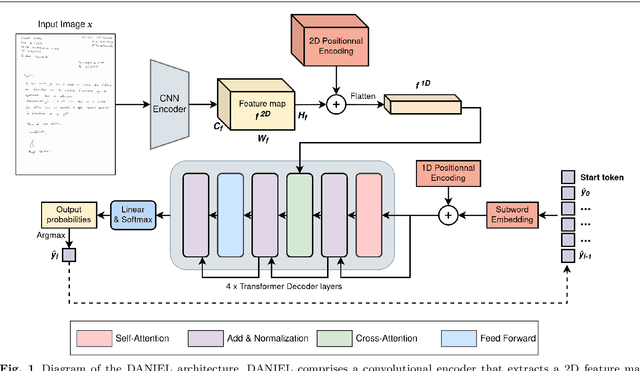
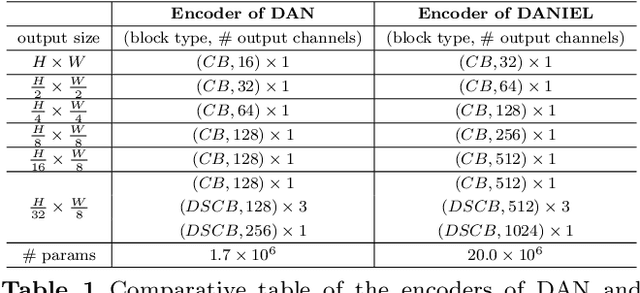

Information extraction from handwritten documents involves traditionally three distinct steps: Document Layout Analysis, Handwritten Text Recognition, and Named Entity Recognition. Recent approaches have attempted to integrate these steps into a single process using fully end-to-end architectures. Despite this, these integrated approaches have not yet matched the performance of language models, when applied to information extraction in plain text. In this paper, we introduce DANIEL (Document Attention Network for Information Extraction and Labelling), a fully end-to-end architecture integrating a language model and designed for comprehensive handwritten document understanding. DANIEL performs layout recognition, handwriting recognition, and named entity recognition on full-page documents. Moreover, it can simultaneously learn across multiple languages, layouts, and tasks. For named entity recognition, the ontology to be applied can be specified via the input prompt. The architecture employs a convolutional encoder capable of processing images of any size without resizing, paired with an autoregressive decoder based on a transformer-based language model. DANIEL achieves competitive results on four datasets, including a new state-of-the-art performance on RIMES 2009 and M-POPP for Handwriting Text Recognition, and IAM NER for Named Entity Recognition. Furthermore, DANIEL is much faster than existing approaches. We provide the source code and the weights of the trained models at \url{https://github.com/Shulk97/daniel}.
End-to-end information extraction in handwritten documents: Understanding Paris marriage records from 1880 to 1940
Apr 30, 2024
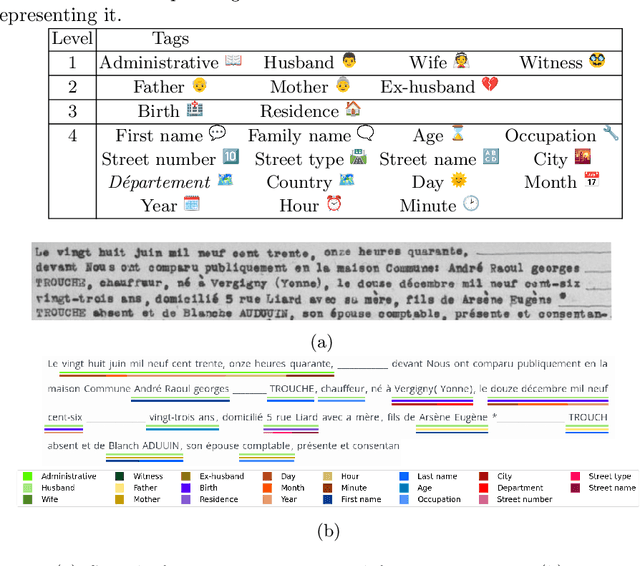


The EXO-POPP project aims to establish a comprehensive database comprising 300,000 marriage records from Paris and its suburbs, spanning the years 1880 to 1940, which are preserved in over 130,000 scans of double pages. Each marriage record may encompass up to 118 distinct types of information that require extraction from plain text. In this paper, we introduce the M-POPP dataset, a subset of the M-POPP database with annotations for full-page text recognition and information extraction in both handwritten and printed documents, and which is now publicly available. We present a fully end-to-end architecture adapted from the DAN, designed to perform both handwritten text recognition and information extraction directly from page images without the need for explicit segmentation. We showcase the information extraction capabilities of this architecture by achieving a new state of the art for full-page Information Extraction on Esposalles and we use this architecture as a baseline for the M-POPP dataset. We also assess and compare how different encoding strategies for named entities in the text affect the performance of jointly recognizing handwritten text and extracting information, from full pages.
Sheet Music Transformer: End-To-End Optical Music Recognition Beyond Monophonic Transcription
Feb 12, 2024State-of-the-art end-to-end Optical Music Recognition (OMR) has, to date, primarily been carried out using monophonic transcription techniques to handle complex score layouts, such as polyphony, often by resorting to simplifications or specific adaptations. Despite their efficacy, these approaches imply challenges related to scalability and limitations. This paper presents the Sheet Music Transformer, the first end-to-end OMR model designed to transcribe complex musical scores without relying solely on monophonic strategies. Our model employs a Transformer-based image-to-sequence framework that predicts score transcriptions in a standard digital music encoding format from input images. Our model has been tested on two polyphonic music datasets and has proven capable of handling these intricate music structures effectively. The experimental outcomes not only indicate the competence of the model, but also show that it is better than the state-of-the-art methods, thus contributing to advancements in end-to-end OMR transcription.
Faster DAN: Multi-target Queries with Document Positional Encoding for End-to-end Handwritten Document Recognition
Jan 25, 2023Recent advances in handwritten text recognition enabled to recognize whole documents in an end-to-end way: the Document Attention Network (DAN) recognizes the characters one after the other through an attention-based prediction process until reaching the end of the document. However, this autoregressive process leads to inference that cannot benefit from any parallelization optimization. In this paper, we propose Faster DAN, a two-step strategy to speed up the recognition process at prediction time: the model predicts the first character of each text line in the document, and then completes all the text lines in parallel through multi-target queries and a specific document positional encoding scheme. Faster DAN reaches competitive results compared to standard DAN, while being at least 4 times faster on whole single-page and double-page images of the RIMES 2009, READ 2016 and MAURDOR datasets. Source code and trained model weights are available at https://github.com/FactoDeepLearning/FasterDAN.