 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Automatic Text Recognition with Language Models in the PyLaia Open-Source Library
Apr 29, 2024



PyLaia is one of the most popular open-source software for Automatic Text Recognition (ATR), delivering strong performance in terms of speed and accuracy. In this paper, we outline our recent contributions to the PyLaia library, focusing on the incorporation of reliable confidence scores and the integration of statistical language modeling during decoding. Our implementation provides an easy way to combine PyLaia with n-grams language models at different levels. One of the highlights of this work is that language models are completely auto-tuned: they can be built and used easily without any expert knowledge, and without requiring any additional data. To demonstrate the significance of our contribution, we evaluate PyLaia's performance on twelve datasets, both with and without language modelling. The results show that decoding with small language models improves the Word Error Rate by 13% and the Character Error Rate by 12% in average. Additionally, we conduct an analysis of confidence scores and highlight the importance of calibration techniques. Our implementation is publicly available in the official PyLaia repository at https://gitlab.teklia.com/atr/pylaia, and twelve open-source models are released on Hugging Face.
The Socface Project: Large-Scale Collection, Processing, and Analysis of a Century of French Censuses
Apr 29, 2024This paper presents a complete processing workflow for extracting information from French census lists from 1836 to 1936. These lists contain information about individuals living in France and their households. We aim at extracting all the information contained in these tables using automatic handwritten table recognition. At the end of the Socface project, in which our work is taking place, the extracted information will be redistributed to the departmental archives, and the nominative lists will be freely available to the public, allowing anyone to browse hundreds of millions of records. The extracted data will be used by demographers to analyze social change over time, significantly improving our understanding of French economic and social structures. For this project, we developed a complete processing workflow: large-scale data collection from French departmental archives, collaborative annotation of documents, training of handwritten table text and structure recognition models, and mass processing of millions of images. We present the tools we have developed to easily collect and process millions of pages. We also show that it is possible to process such a wide variety of tables with a single table recognition model that uses the image of the entire page to recognize information about individuals, categorize them and automatically group them into households. The entire process has been successfully used to process the documents of a departmental archive, representing more than 450,000 images.
Handwritten Text Recognition from Crowdsourced Annotations
Jun 19, 2023In this paper, we explore different ways of training a model for handwritten text recognition when multiple imperfect or noisy transcriptions are available. We consider various training configurations, such as selecting a single transcription, retaining all transcriptions, or computing an aggregated transcription from all available annotations. In addition, we evaluate the impact of quality-based data selection, where samples with low agreement are removed from the training set. Our experiments are carried out on municipal registers of the city of Belfort (France) written between 1790 and 1946. % results The results show that computing a consensus transcription or training on multiple transcriptions are good alternatives. However, selecting training samples based on the degree of agreement between annotators introduces a bias in the training data and does not improve the results. Our dataset is publicly available on Zenodo: https://zenodo.org/record/8041668.
Large Scale Genealogical Information Extraction From Handwritten Quebec Parish Records
Apr 27, 2023This paper presents a complete workflow designed for extracting information from Quebec handwritten parish registers. The acts in these documents contain individual and family information highly valuable for genetic, demographic and social studies of the Quebec population. From an image of parish records, our workflow is able to identify the acts and extract personal information. The workflow is divided into successive steps: page classification, text line detection, handwritten text recognition, named entity recognition and act detection and classification. For all these steps, different machine learning models are compared. Once the information is extracted, validation rules designed by experts are then applied to standardize the extracted information and ensure its consistency with the type of act (birth, marriage, and death). This validation step is able to reject records that are considered invalid or merged. The full workflow has been used to process over two million pages of Quebec parish registers from the 19-20th centuries. On a sample comprising 65% of registers, 3.2 million acts were recognized. Verification of the birth and death acts from this sample shows that 74% of them are considered complete and valid. These records will be integrated into the BALSAC database and linked together to recreate family and genealogical relations at large scale.
Key-value information extraction from full handwritten pages
Apr 26, 2023



We propose a Transformer-based approach for information extraction from digitized handwritten documents. Our approach combines, in a single model, the different steps that were so far performed by separate models: feature extraction, handwriting recognition and named entity recognition. We compare this integrated approach with traditional two-stage methods that perform handwriting recognition before named entity recognition, and present results at different levels: line, paragraph, and page. Our experiments show that attention-based models are especially interesting when applied on full pages, as they do not require any prior segmentation step. Finally, we show that they are able to learn from key-value annotations: a list of important words with their corresponding named entities. We compare our models to state-of-the-art methods on three public databases (IAM, ESPOSALLES, and POPP) and outperform previous performances on all three datasets.
SIMARA: a database for key-value information extraction from full pages
Apr 26, 2023



We propose a new database for information extraction from historical handwritten documents. The corpus includes 5,393 finding aids from six different series, dating from the 18th-20th centuries. Finding aids are handwritten documents that contain metadata describing older archives. They are stored in the National Archives of France and are used by archivists to identify and find archival documents. Each document is annotated at page-level, and contains seven fields to retrieve. The localization of each field is not available in such a way that this dataset encourages research on segmentation-free systems for information extraction. We propose a model based on the Transformer architecture trained for end-to-end information extraction and provide three sets for training, validation and testing, to ensure fair comparison with future works. The database is freely accessible at https://zenodo.org/record/7868059.
Détection d'Objets dans les documents numérisés par réseaux de neurones profonds
Jan 27, 2023



In this thesis, we study multiple tasks related to document layout analysis such as the detection of text lines, the splitting into acts or the detection of the writing support. Thus, we propose two deep neural models following two different approaches. We aim at proposing a model for object detection that considers the difficulties associated with document processing, including the limited amount of training data available. In this respect, we propose a pixel-level detection model and a second object-level detection model. We first propose a detection model with few parameters, fast in prediction, and which can obtain accurate prediction masks from a reduced number of training data. We implemented a strategy of collection and uniformization of many datasets, which are used to train a single line detection model that demonstrates high generalization capabilities to out-of-sample documents. We also propose a Transformer-based detection model. The design of such a model required redefining the task of object detection in document images and to study different approaches. Following this study, we propose an object detection strategy consisting in sequentially predicting the coordinates of the objects enclosing rectangles through a pixel classification. This strategy allows obtaining a fast model with only few parameters. Finally, in an industrial setting, new non-annotated data are often available. Thus, in the case of a model adaptation to this new data, it is expected to provide the system as few new annotated samples as possible. The selection of relevant samples for manual annotation is therefore crucial to enable successful adaptation. For this purpose, we propose confidence estimators from different approaches for object detection. We show that these estimators greatly reduce the amount of annotated data while optimizing the performances.
Confidence Estimation for Object Detection in Document Images
Aug 29, 2022

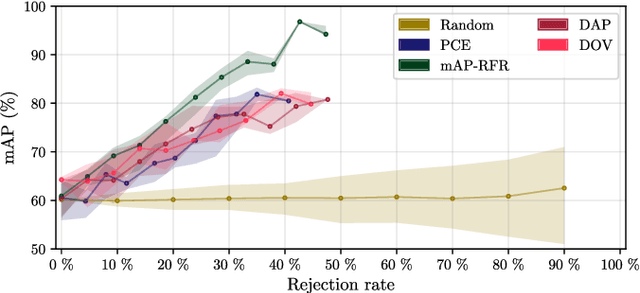
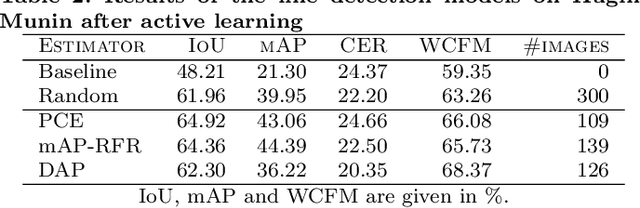
Deep neural networks are becoming increasingly powerful and large and always require more labelled data to be trained. However, since annotating data is time-consuming, it is now necessary to develop systems that show good performance while learning on a limited amount of data. These data must be correctly chosen to obtain models that are still efficient. For this, the systems must be able to determine which data should be annotated to achieve the best results. In this paper, we propose four estimators to estimate the confidence of object detection predictions. The first two are based on Monte Carlo dropout, the third one on descriptive statistics and the last one on the detector posterior probabilities. In the active learning framework, the three first estimators show a significant improvement in performance for the detection of document physical pages and text lines compared to a random selection of images. We also show that the proposed estimator based on descriptive statistics can replace MC dropout, reducing the computational cost without compromising the performances.
Robust Text Line Detection in Historical Documents: Learning and Evaluation Methods
Mar 23, 2022



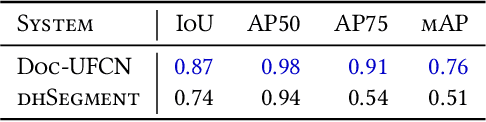
Text line segmentation is one of the key steps in historical document understanding. It is challenging due to the variety of fonts, contents, writing styles and the quality of documents that have degraded through the years. In this paper, we address the limitations that currently prevent people from building line segmentation models with a high generalization capacity. We present a study conducted using three state-of-the-art systems Doc-UFCN, dhSegment and ARU-Net and show that it is possible to build generic models trained on a wide variety of historical document datasets that can correctly segment diverse unseen pages. This paper also highlights the importance of the annotations used during training: each existing dataset is annotated differently. We present a unification of the annotations and show its positive impact on the final text recognition results. In this end, we present a complete evaluation strategy using standard pixel-level metrics, object-level ones and introducing goal-oriented metrics.
Including Keyword Position in Image-based Models for Act Segmentation of Historical Registers
Sep 17, 2021


The segmentation of complex images into semantic regions has seen a growing interest these last years with the advent of Deep Learning. Until recently, most existing methods for Historical Document Analysis focused on the visual appearance of documents, ignoring the rich information that textual content can offer. However, the segmentation of complex documents into semantic regions is sometimes impossible relying only on visual features and recent models embed both visual and textual information. In this paper, we focus on the use of both visual and textual information for segmenting historical registers into structured and meaningful units such as acts. An act is a text recording containing valuable knowledge such as demographic information (baptism, marriage or death) or royal decisions (donation or pardon). We propose a simple pipeline to enrich document images with the position of text lines containing key-phrases and show that running a standard image-based layout analysis system on these images can lead to significant gains. Our experiments show that the detection of acts increases from 38 % of mAP to 74 % when adding textual information, in real use-case conditions where text lines positions and content are extracted with an automatic recognition system.