 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Scale Genealogical Information Extraction From Handwritten Quebec Parish Records
Apr 27, 2023This paper presents a complete workflow designed for extracting information from Quebec handwritten parish registers. The acts in these documents contain individual and family information highly valuable for genetic, demographic and social studies of the Quebec population. From an image of parish records, our workflow is able to identify the acts and extract personal information. The workflow is divided into successive steps: page classification, text line detection, handwritten text recognition, named entity recognition and act detection and classification. For all these steps, different machine learning models are compared. Once the information is extracted, validation rules designed by experts are then applied to standardize the extracted information and ensure its consistency with the type of act (birth, marriage, and death). This validation step is able to reject records that are considered invalid or merged. The full workflow has been used to process over two million pages of Quebec parish registers from the 19-20th centuries. On a sample comprising 65% of registers, 3.2 million acts were recognized. Verification of the birth and death acts from this sample shows that 74% of them are considered complete and valid. These records will be integrated into the BALSAC database and linked together to recreate family and genealogical relations at large scale.
The LAM Dataset: A Novel Benchmark for Line-Level Handwritten Text Recognition
Aug 16, 2022
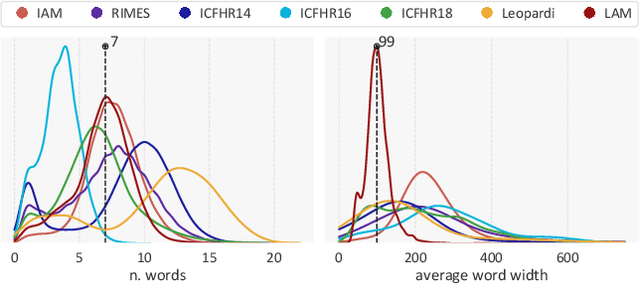
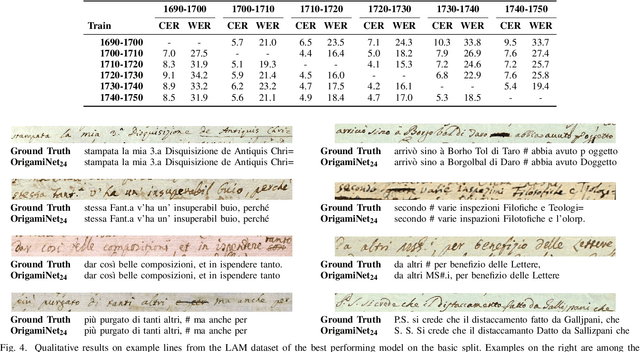
Handwritten Text Recognition (HTR) is an open problem at the intersection of Computer Vision and Natural Language Processing. The main challenges, when dealing with historical manuscripts, are due to the preservation of the paper support, the variability of the handwriting -- even of the same author over a wide time-span -- and the scarcity of data from ancient, poorly represented languages. With the aim of fostering the research on this topic, in this paper we present the Ludovico Antonio Muratori (LAM) dataset, a large line-level HTR dataset of Italian ancient manuscripts edited by a single author over 60 years. The dataset comes in two configurations: a basic splitting and a date-based splitting which takes into account the age of the author. The first setting is intended to study HTR on ancient documents in Italian, while the second focuses on the ability of HTR systems to recognize text written by the same writer in time periods for which training data are not available. For both configurations, we analyze quantitative and qualitative characteristics, also with respect to other line-level HTR benchmarks, and present the recognition performance of state-of-the-art HTR architectures. The dataset is available for download at \url{https://aimagelab.ing.unimore.it/go/lam}.
Including Keyword Position in Image-based Models for Act Segmentation of Historical Registers
Sep 17, 2021
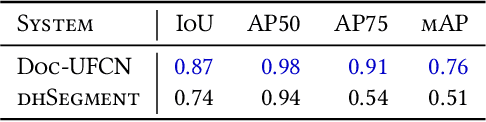


The segmentation of complex images into semantic regions has seen a growing interest these last years with the advent of Deep Learning. Until recently, most existing methods for Historical Document Analysis focused on the visual appearance of documents, ignoring the rich information that textual content can offer. However, the segmentation of complex documents into semantic regions is sometimes impossible relying only on visual features and recent models embed both visual and textual information. In this paper, we focus on the use of both visual and textual information for segmenting historical registers into structured and meaningful units such as acts. An act is a text recording containing valuable knowledge such as demographic information (baptism, marriage or death) or royal decisions (donation or pardon). We propose a simple pipeline to enrich document images with the position of text lines containing key-phrases and show that running a standard image-based layout analysis system on these images can lead to significant gains. Our experiments show that the detection of acts increases from 38 % of mAP to 74 % when adding textual information, in real use-case conditions where text lines positions and content are extracted with an automatic recognition system.