 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLook Twice: Training-Free Evidence Highlighting in Multimodal Large Language Models
Apr 01, 2026Answering questions about images often requires combining visual understanding with external knowledge. Multimodal Large Language Models (MLLMs) provide a natural framework for this setting, but they often struggle to identify the most relevant visual and textual evidence when answering knowledge-intensive queries. In such scenarios, models must integrate visual cues with retrieved textual evidence that is often noisy or only partially relevant, while also localizing fine-grained visual information in the image. In this work, we introduce Look Twice (LoT), a training-free inference-time framework that improves how pretrained MLLMs utilize multimodal evidence. Specifically, we exploit the model attention patterns to estimate which visual regions and retrieved textual elements are relevant to a query, and then generate the answer conditioned on this highlighted evidence. The selected cues are highlighted through lightweight prompt-level markers that encourage the model to re-attend to the relevant evidence during generation. Experiments across multiple knowledge-based VQA benchmarks show consistent improvements over zero-shot MLLMs. Additional evaluations on vision-centric and hallucination-oriented benchmarks further demonstrate that visual evidence highlighting alone improves model performance in settings without textual context, all without additional training or architectural modifications. Source code will be publicly released.
Tiny Inference-Time Scaling with Latent Verifiers
Mar 25, 2026Inference-time scaling has emerged as an effective way to improve generative models at test time by using a verifier to score and select candidate outputs. A common choice is to employ Multimodal Large Language Models (MLLMs) as verifiers, which can improve performance but introduce substantial inference-time cost. Indeed, diffusion pipelines operate in an autoencoder latent space to reduce computation, yet MLLM verifiers still require decoding candidates to pixel space and re-encoding them into the visual embedding space, leading to redundant and costly operations. In this work, we propose Verifier on Hidden States (VHS), a verifier that operates directly on intermediate hidden representations of Diffusion Transformer (DiT) single-step generators. VHS analyzes generator features without decoding to pixel space, thereby reducing the per-candidate verification cost while improving or matching the performance of MLLM-based competitors. We show that, under tiny inference budgets with only a small number of candidates per prompt, VHS enables more efficient inference-time scaling reducing joint generation-and-verification time by 63.3%, compute FLOPs by 51% and VRAM usage by 14.5% with respect to a standard MLLM verifier, achieving a +2.7% improvement on GenEval at the same inference-time budget.
CounterVid: Counterfactual Video Generation for Mitigating Action and Temporal Hallucinations in Video-Language Models
Jan 08, 2026Video-language models (VLMs) achieve strong multimodal understanding but remain prone to hallucinations, especially when reasoning about actions and temporal order. Existing mitigation strategies, such as textual filtering or random video perturbations, often fail to address the root cause: over-reliance on language priors rather than fine-grained visual dynamics. We propose a scalable framework for counterfactual video generation that synthesizes videos differing only in actions or temporal structure while preserving scene context. Our pipeline combines multimodal LLMs for action proposal and editing guidance with diffusion-based image and video models to generate semantic hard negatives at scale. Using this framework, we build CounterVid, a synthetic dataset of ~26k preference pairs targeting action recognition and temporal reasoning. We further introduce MixDPO, a unified Direct Preference Optimization approach that jointly leverages textual and visual preferences. Fine-tuning Qwen2.5-VL with MixDPO yields consistent improvements, notably in temporal ordering, and transfers effectively to standard video hallucination benchmarks. Code and models will be made publicly available.
Seeing Beyond Words: Self-Supervised Visual Learning for Multimodal Large Language Models
Dec 17, 2025Multimodal Large Language Models (MLLMs) have recently demonstrated impressive capabilities in connecting vision and language, yet their proficiency in fundamental visual reasoning tasks remains limited. This limitation can be attributed to the fact that MLLMs learn visual understanding primarily from textual descriptions, which constitute a subjective and inherently incomplete supervisory signal. Furthermore, the modest scale of multimodal instruction tuning compared to massive text-only pre-training leads MLLMs to overfit language priors while overlooking visual details. To address these issues, we introduce JARVIS, a JEPA-inspired framework for self-supervised visual enhancement in MLLMs. Specifically, we integrate the I-JEPA learning paradigm into the standard vision-language alignment pipeline of MLLMs training. Our approach leverages frozen vision foundation models as context and target encoders, while training the predictor, implemented as the early layers of an LLM, to learn structural and semantic regularities from images without relying exclusively on language supervision. Extensive experiments on standard MLLM benchmarks show that JARVIS consistently improves performance on vision-centric benchmarks across different LLM families, without degrading multimodal reasoning abilities. Our source code is publicly available at: https://github.com/aimagelab/JARVIS.
Recurrence Meets Transformers for Universal Multimodal Retrieval
Sep 10, 2025


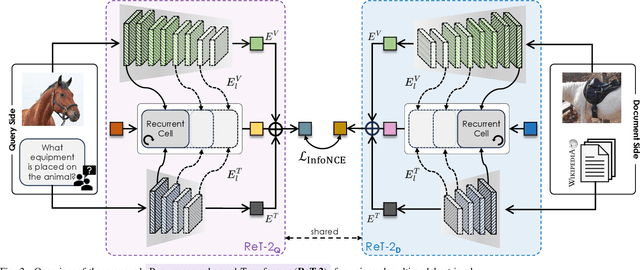
With the rapid advancement of multimodal retrieval and its application in LLMs and multimodal LLMs, increasingly complex retrieval tasks have emerged. Existing methods predominantly rely on task-specific fine-tuning of vision-language models and are limited to single-modality queries or documents. In this paper, we propose ReT-2, a unified retrieval model that supports multimodal queries, composed of both images and text, and searches across multimodal document collections where text and images coexist. ReT-2 leverages multi-layer representations and a recurrent Transformer architecture with LSTM-inspired gating mechanisms to dynamically integrate information across layers and modalities, capturing fine-grained visual and textual details. We evaluate ReT-2 on the challenging M2KR and M-BEIR benchmarks across different retrieval configurations. Results demonstrate that ReT-2 consistently achieves state-of-the-art performance across diverse settings, while offering faster inference and reduced memory usage compared to prior approaches. When integrated into retrieval-augmented generation pipelines, ReT-2 also improves downstream performance on Encyclopedic-VQA and InfoSeek datasets. Our source code and trained models are publicly available at: https://github.com/aimagelab/ReT-2
SVGauge: Towards Human-Aligned Evaluation for SVG Generation
Sep 08, 2025Generated Scalable Vector Graphics (SVG) images demand evaluation criteria tuned to their symbolic and vectorial nature: criteria that existing metrics such as FID, LPIPS, or CLIPScore fail to satisfy. In this paper, we introduce SVGauge, the first human-aligned, reference based metric for text-to-SVG generation. SVGauge jointly measures (i) visual fidelity, obtained by extracting SigLIP image embeddings and refining them with PCA and whitening for domain alignment, and (ii) semantic consistency, captured by comparing BLIP-2-generated captions of the SVGs against the original prompts in the combined space of SBERT and TF-IDF. Evaluation on the proposed SHE benchmark shows that SVGauge attains the highest correlation with human judgments and reproduces system-level rankings of eight zero-shot LLM-based generators more faithfully than existing metrics. Our results highlight the necessity of vector-specific evaluation and provide a practical tool for benchmarking future text-to-SVG generation models.
RAID: A Dataset for Testing the Adversarial Robustness of AI-Generated Image Detectors
Jun 09, 2025AI-generated images have reached a quality level at which humans are incapable of reliably distinguishing them from real images. To counteract the inherent risk of fraud and disinformation, the detection of AI-generated images is a pressing challenge and an active research topic. While many of the presented methods claim to achieve high detection accuracy, they are usually evaluated under idealized conditions. In particular, the adversarial robustness is often neglected, potentially due to a lack of awareness or the substantial effort required to conduct a comprehensive robustness analysis. In this work, we tackle this problem by providing a simpler means to assess the robustness of AI-generated image detectors. We present RAID (Robust evaluation of AI-generated image Detectors), a dataset of 72k diverse and highly transferable adversarial examples. The dataset is created by running attacks against an ensemble of seven state-of-the-art detectors and images generated by four different text-to-image models. Extensive experiments show that our methodology generates adversarial images that transfer with a high success rate to unseen detectors, which can be used to quickly provide an approximate yet still reliable estimate of a detector's adversarial robustness. Our findings indicate that current state-of-the-art AI-generated image detectors can be easily deceived by adversarial examples, highlighting the critical need for the development of more robust methods. We release our dataset at https://huggingface.co/datasets/aimagelab/RAID and evaluation code at https://github.com/pralab/RAID.
What Changed? Detecting and Evaluating Instruction-Guided Image Edits with Multimodal Large Language Models
May 26, 2025Instruction-based image editing models offer increased personalization opportunities in generative tasks. However, properly evaluating their results is challenging, and most of the existing metrics lag in terms of alignment with human judgment and explainability. To tackle these issues, we introduce DICE (DIfference Coherence Estimator), a model designed to detect localized differences between the original and the edited image and to assess their relevance to the given modification request. DICE consists of two key components: a difference detector and a coherence estimator, both built on an autoregressive Multimodal Large Language Model (MLLM) and trained using a strategy that leverages self-supervision, distillation from inpainting networks, and full supervision. Through extensive experiments, we evaluate each stage of our pipeline, comparing different MLLMs within the proposed framework. We demonstrate that DICE effectively identifies coherent edits, effectively evaluating images generated by different editing models with a strong correlation with human judgment. We publicly release our source code, models, and data.
Improving LLM First-Token Predictions in Multiple-Choice Question Answering via Prefilling Attack
May 21, 2025Large Language Models (LLMs) are increasingly evaluated on multiple-choice question answering (MCQA) tasks using *first-token probability* (FTP), which selects the answer option whose initial token has the highest likelihood. While efficient, FTP can be fragile: models may assign high probability to unrelated tokens (*misalignment*) or use a valid token merely as part of a generic preamble rather than as a clear answer choice (*misinterpretation*), undermining the reliability of symbolic evaluation. We propose a simple solution: the *prefilling attack*, a structured natural-language prefix (e.g., "*The correct option is:*") prepended to the model output. Originally explored in AI safety, we repurpose prefilling to steer the model to respond with a clean, valid option, without modifying its parameters. Empirically, the FTP with prefilling strategy substantially improves accuracy, calibration, and output consistency across a broad set of LLMs and MCQA benchmarks. It outperforms standard FTP and often matches the performance of open-ended generation approaches that require full decoding and external classifiers, while being significantly more efficient. Our findings suggest that prefilling is a simple, robust, and low-cost method to enhance the reliability of FTP-based evaluation in multiple-choice settings.
LLaVA-MORE: A Comparative Study of LLMs and Visual Backbones for Enhanced Visual Instruction Tuning
Mar 19, 2025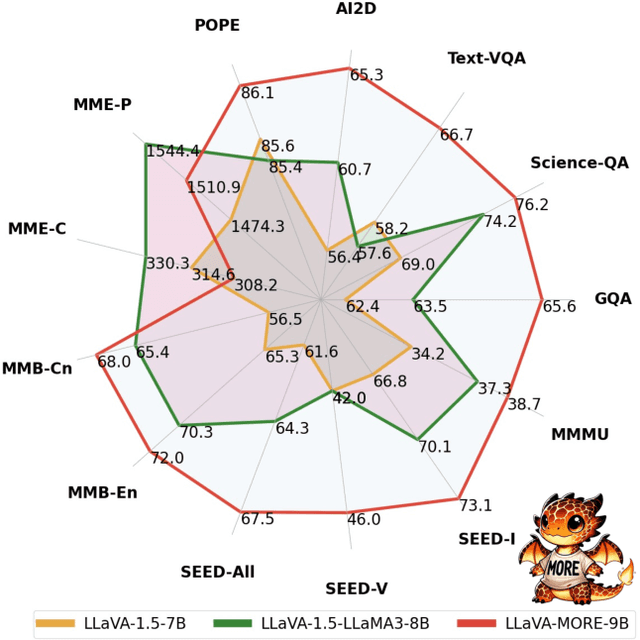
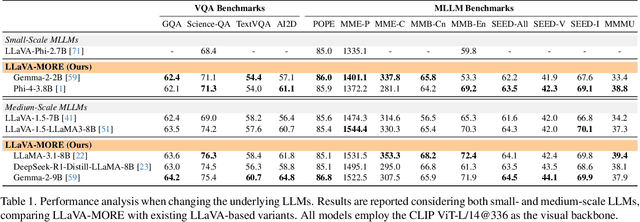
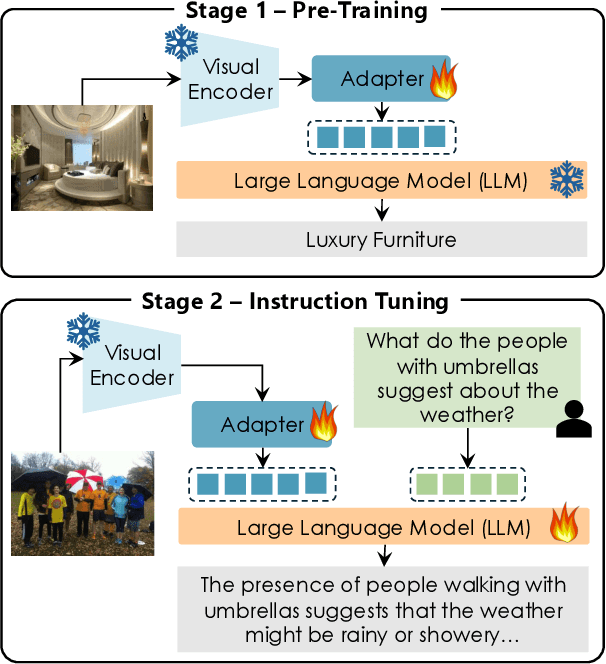
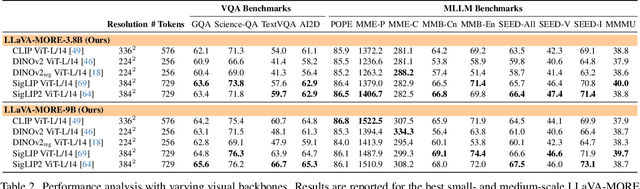
Recent progress in Multimodal Large Language Models (MLLMs) has highlighted the critical roles of both the visual backbone and the underlying language model. While prior work has primarily focused on scaling these components to billions of parameters, the trade-offs between model size, architecture, and performance remain underexplored. Additionally, inconsistencies in training data and evaluation protocols have hindered direct comparisons, making it difficult to derive optimal design choices. In this paper, we introduce LLaVA-MORE, a new family of MLLMs that integrates recent language models with diverse visual backbones. To ensure fair comparisons, we employ a unified training protocol applied consistently across all architectures. Our analysis systematically explores both small- and medium-scale LLMs -- including Phi-4, LLaMA-3.1, and Gemma-2 -- to evaluate multimodal reasoning, generation, and instruction following, while examining the relationship between model size and performance. Beyond evaluating the LLM impact on final results, we conduct a comprehensive study of various visual encoders, ranging from CLIP-based architectures to alternatives such as DINOv2, SigLIP, and SigLIP2. Additional experiments investigate the effects of increased image resolution and variations in pre-training datasets. Overall, our results provide insights into the design of more effective MLLMs, offering a reproducible evaluation framework that facilitates direct comparisons and can guide future model development. Our source code and trained models are publicly available at: https://github.com/aimagelab/LLaVA-MORE.