 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAID: A Dataset for Testing the Adversarial Robustness of AI-Generated Image Detectors
Jun 09, 2025AI-generated images have reached a quality level at which humans are incapable of reliably distinguishing them from real images. To counteract the inherent risk of fraud and disinformation, the detection of AI-generated images is a pressing challenge and an active research topic. While many of the presented methods claim to achieve high detection accuracy, they are usually evaluated under idealized conditions. In particular, the adversarial robustness is often neglected, potentially due to a lack of awareness or the substantial effort required to conduct a comprehensive robustness analysis. In this work, we tackle this problem by providing a simpler means to assess the robustness of AI-generated image detectors. We present RAID (Robust evaluation of AI-generated image Detectors), a dataset of 72k diverse and highly transferable adversarial examples. The dataset is created by running attacks against an ensemble of seven state-of-the-art detectors and images generated by four different text-to-image models. Extensive experiments show that our methodology generates adversarial images that transfer with a high success rate to unseen detectors, which can be used to quickly provide an approximate yet still reliable estimate of a detector's adversarial robustness. Our findings indicate that current state-of-the-art AI-generated image detectors can be easily deceived by adversarial examples, highlighting the critical need for the development of more robust methods. We release our dataset at https://huggingface.co/datasets/aimagelab/RAID and evaluation code at https://github.com/pralab/RAID.
Security Benefits and Side Effects of Labeling AI-Generated Images
May 28, 2025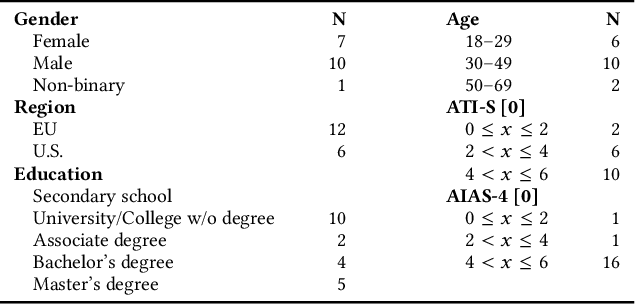

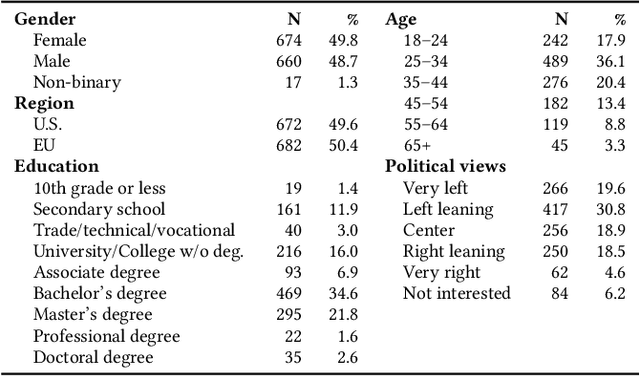
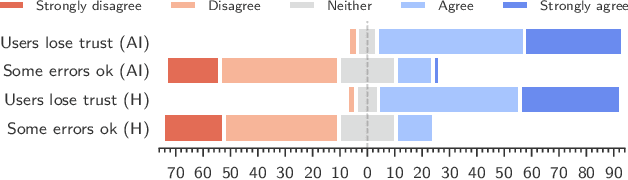
Generative artificial intelligence is developing rapidly, impacting humans' interaction with information and digital media. It is increasingly used to create deceptively realistic misinformation, so lawmakers have imposed regulations requiring the disclosure of AI-generated content. However, only little is known about whether these labels reduce the risks of AI-generated misinformation. Our work addresses this research gap. Focusing on AI-generated images, we study the implications of labels, including the possibility of mislabeling. Assuming that simplicity, transparency, and trust are likely to impact the successful adoption of such labels, we first qualitatively explore users' opinions and expectations of AI labeling using five focus groups. Second, we conduct a pre-registered online survey with over 1300 U.S. and EU participants to quantitatively assess the effect of AI labels on users' ability to recognize misinformation containing either human-made or AI-generated images. Our focus groups illustrate that, while participants have concerns about the practical implementation of labeling, they consider it helpful in identifying AI-generated images and avoiding deception. However, considering security benefits, our survey revealed an ambiguous picture, suggesting that users might over-rely on labels. While inaccurate claims supported by labeled AI-generated images were rated less credible than those with unlabeled AI-images, the belief in accurate claims also decreased when accompanied by a labeled AI-generated image. Moreover, we find the undesired side effect that human-made images conveying inaccurate claims were perceived as more credible in the presence of labels.
Fake It Until You Break It: On the Adversarial Robustness of AI-generated Image Detectors
Oct 02, 2024



While generative AI (GenAI) offers countless possibilities for creative and productive tasks, artificially generated media can be misused for fraud, manipulation, scams, misinformation campaigns, and more. To mitigate the risks associated with maliciously generated media, forensic classifiers are employed to identify AI-generated content. However, current forensic classifiers are often not evaluated in practically relevant scenarios, such as the presence of an attacker or when real-world artifacts like social media degradations affect images. In this paper, we evaluate state-of-the-art AI-generated image (AIGI) detectors under different attack scenarios. We demonstrate that forensic classifiers can be effectively attacked in realistic settings, even when the attacker does not have access to the target model and post-processing occurs after the adversarial examples are created, which is standard on social media platforms. These attacks can significantly reduce detection accuracy to the extent that the risks of relying on detectors outweigh their benefits. Finally, we propose a simple defense mechanism to make CLIP-based detectors, which are currently the best-performing detectors, robust against these attacks.
AI-Generated Faces in the Real World: A Large-Scale Case Study of Twitter Profile Images
Apr 22, 2024



Recent advances in the field of generative artificial intelligence (AI) have blurred the lines between authentic and machine-generated content, making it almost impossible for humans to distinguish between such media. One notable consequence is the use of AI-generated images for fake profiles on social media. While several types of disinformation campaigns and similar incidents have been reported in the past, a systematic analysis has been lacking. In this work, we conduct the first large-scale investigation of the prevalence of AI-generated profile pictures on Twitter. We tackle the challenges of a real-world measurement study by carefully integrating various data sources and designing a multi-stage detection pipeline. Our analysis of nearly 15 million Twitter profile pictures shows that 0.052% were artificially generated, confirming their notable presence on the platform. We comprehensively examine the characteristics of these accounts and their tweet content, and uncover patterns of coordinated inauthentic behavior. The results also reveal several motives, including spamming and political amplification campaigns. Our research reaffirms the need for effective detection and mitigation strategies to cope with the potential negative effects of generative AI in the future.
AEROBLADE: Training-Free Detection of Latent Diffusion Images Using Autoencoder Reconstruction Error
Jan 31, 2024
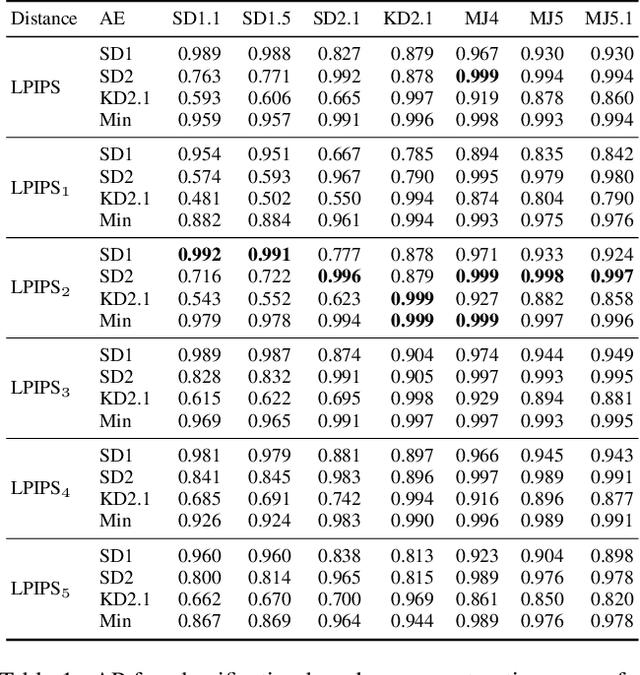
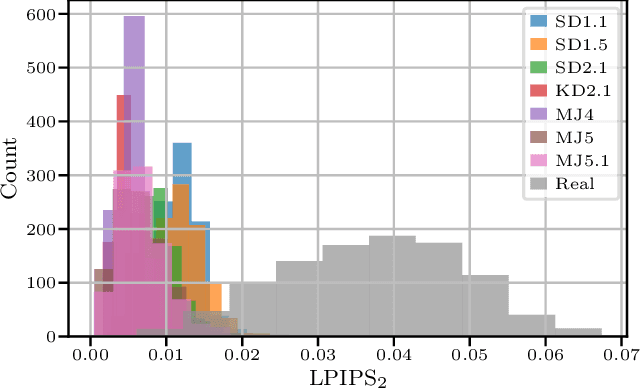

With recent text-to-image models, anyone can generate deceptively realistic images with arbitrary contents, fueling the growing threat of visual disinformation. A key enabler for generating high-resolution images with low computational cost has been the development of latent diffusion models (LDMs). In contrast to conventional diffusion models, LDMs perform the denoising process in the low-dimensional latent space of a pre-trained autoencoder (AE) instead of the high-dimensional image space. Despite their relevance, the forensic analysis of LDMs is still in its infancy. In this work we propose AEROBLADE, a novel detection method which exploits an inherent component of LDMs: the AE used to transform images between image and latent space. We find that generated images can be more accurately reconstructed by the AE than real images, allowing for a simple detection approach based on the reconstruction error. Most importantly, our method is easy to implement and does not require any training, yet nearly matches the performance of detectors that rely on extensive training. We empirically demonstrate that AEROBLADE is effective against state-of-the-art LDMs including Stable Diffusion and Midjourney. Beyond detection, our approach allows for the qualitative analysis of images, which can be leveraged for identifying inpainted regions.
A Representative Study on Human Detection of Artificially Generated Media Across Countries
Dec 10, 2023



AI-generated media has become a threat to our digital society as we know it. These forgeries can be created automatically and on a large scale based on publicly available technology. Recognizing this challenge, academics and practitioners have proposed a multitude of automatic detection strategies to detect such artificial media. However, in contrast to these technical advances, the human perception of generated media has not been thoroughly studied yet. In this paper, we aim at closing this research gap. We perform the first comprehensive survey into people's ability to detect generated media, spanning three countries (USA, Germany, and China) with 3,002 participants across audio, image, and text media. Our results indicate that state-of-the-art forgeries are almost indistinguishable from "real" media, with the majority of participants simply guessing when asked to rate them as human- or machine-generated. In addition, AI-generated media receive is voted more human like across all media types and all countries. To further understand which factors influence people's ability to detect generated media, we include personal variables, chosen based on a literature review in the domains of deepfake and fake news research. In a regression analysis, we found that generalized trust, cognitive reflection, and self-reported familiarity with deepfakes significantly influence participant's decision across all media categories.
Single-Model Attribution via Final-Layer Inversion
May 26, 2023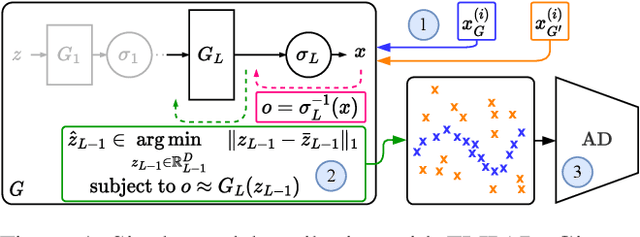
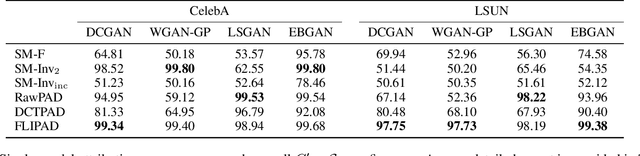
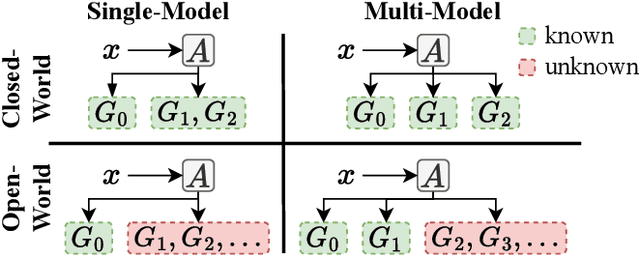

Recent groundbreaking developments on generative modeling have sparked interest in practical single-model attribution. Such methods predict whether a sample was generated by a specific generator or not, for instance, to prove intellectual property theft. However, previous works are either limited to the closed-world setting or require undesirable changes of the generative model. We address these shortcomings by proposing FLIPAD, a new approach for single-model attribution in the open-world setting based on final-layer inversion and anomaly detection. We show that the utilized final-layer inversion can be reduced to a convex lasso optimization problem, making our approach theoretically sound and computationally efficient. The theoretical findings are accompanied by an experimental study demonstrating the effectiveness of our approach, outperforming the existing methods.
Towards the Detection of Diffusion Model Deepfakes
Oct 26, 2022Diffusion models (DMs) have recently emerged as a promising method in image synthesis. They have surpassed generative adversarial networks (GANs) in both diversity and quality, and have achieved impressive results in text-to-image and image-to-image modeling. However, to date, only little attention has been paid to the detection of DM-generated images, which is critical to prevent adverse impacts on our society. Although prior work has shown that GAN-generated images can be reliably detected using automated methods, it is unclear whether the same methods are effective against DMs. In this work, we address this challenge and take a first look at detecting DM-generated images. We approach the problem from two different angles: First, we evaluate the performance of state-of-the-art detectors on a variety of DMs. Second, we analyze DM-generated images in the frequency domain and study different factors that influence the spectral properties of these images. Most importantly, we demonstrate that GANs and DMs produce images with different characteristics, which requires adaptation of existing classifiers to ensure reliable detection. We believe this work provides the foundation and starting point for further research to detect DM deepfakes effectively.