 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
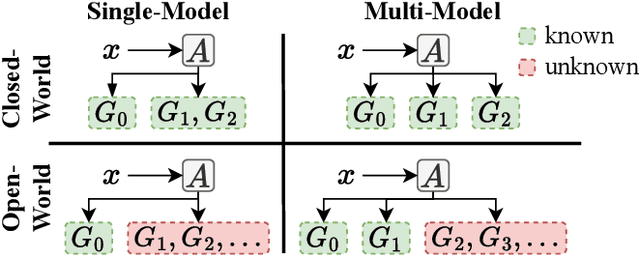
Add to EdgeSingle-Model Attribution for Spoofed Speech via Vocoder Fingerprints in an Open-World Setting
Nov 21, 2024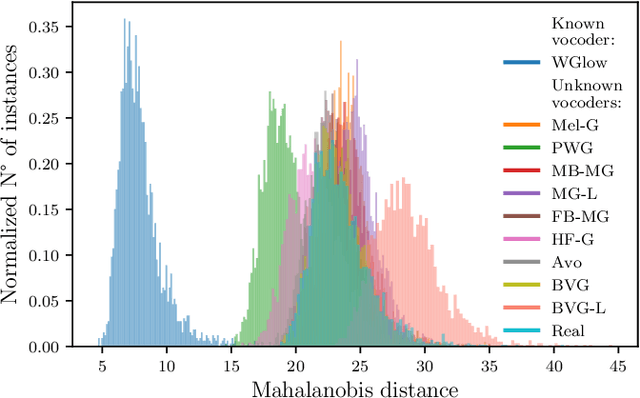
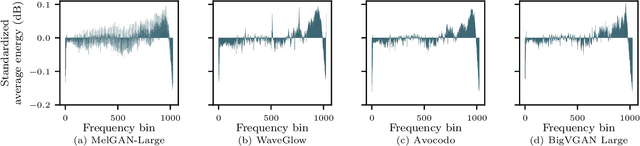
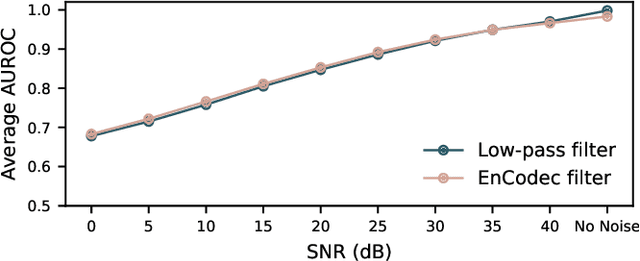
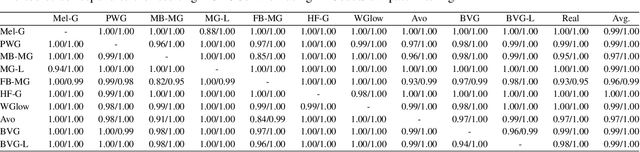
As speech generation technology advances, so do the potential threats of misusing spoofed speech signals. One way to address these threats is by attributing the signals to their source generative model. In this work, we are the first to tackle the single-model attribution task in an open-world setting, that is, we aim at identifying whether spoofed speech signals from unknown sources originate from a specific vocoder. We show that the standardized average residual between audio signals and their low-pass filtered or EnCodec filtered versions can serve as powerful vocoder fingerprints. The approach only requires data from the target vocoder and allows for simple but highly accurate distance-based model attribution. We demonstrate its effectiveness on LJSpeech and JSUT, achieving an average AUROC of over 99% in most settings. The accompanying robustness study shows that it is also resilient to noise levels up to a certain degree.
AnomalyDINO: Boosting Patch-based Few-shot Anomaly Detection with DINOv2
May 23, 2024


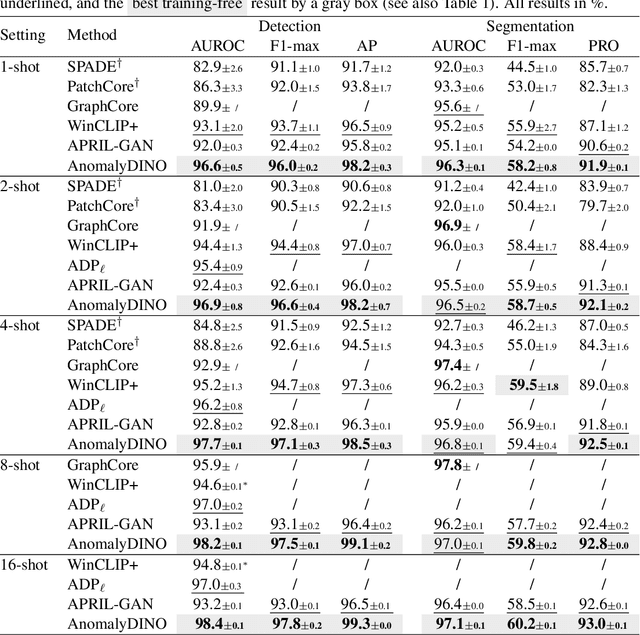
Recent advances in multimodal foundation models have set new standards in few-shot anomaly detection. This paper explores whether high-quality visual features alone are sufficient to rival existing state-of-the-art vision-language models. We affirm this by adapting DINOv2 for one-shot and few-shot anomaly detection, with a focus on industrial applications. We show that this approach does not only rival existing techniques but can even outmatch them in many settings. Our proposed vision-only approach, AnomalyDINO, is based on patch similarities and enables both image-level anomaly prediction and pixel-level anomaly segmentation. The approach is methodologically simple and training-free and, thus, does not require any additional data for fine-tuning or meta-learning. Despite its simplicity, AnomalyDINO achieves state-of-the-art results in one- and few-shot anomaly detection (e.g., pushing the one-shot performance on MVTec-AD from an AUROC of 93.1% to 96.6%). The reduced overhead, coupled with its outstanding few-shot performance, makes AnomalyDINO a strong candidate for fast deployment, for example, in industrial contexts.
Benchmarking the Fairness of Image Upsampling Methods
Jan 24, 2024
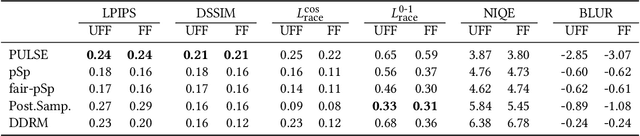
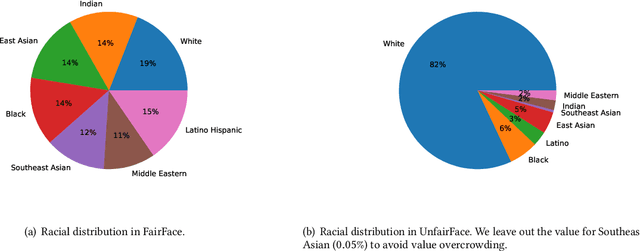
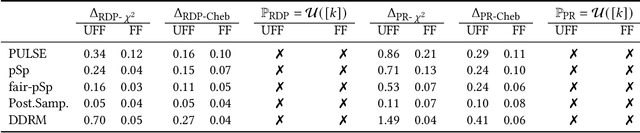
Recent years have witnessed a rapid development of deep generative models for creating synthetic media, such as images and videos. While the practical applications of these models in everyday tasks are enticing, it is crucial to assess the inherent risks regarding their fairness. In this work, we introduce a comprehensive framework for benchmarking the performance and fairness of conditional generative models. We develop a set of metrics$\unicode{x2013}$inspired by their supervised fairness counterparts$\unicode{x2013}$to evaluate the models on their fairness and diversity. Focusing on the specific application of image upsampling, we create a benchmark covering a wide variety of modern upsampling methods. As part of the benchmark, we introduce UnfairFace, a subset of FairFace that replicates the racial distribution of common large-scale face datasets. Our empirical study highlights the importance of using an unbiased training set and reveals variations in how the algorithms respond to dataset imbalances. Alarmingly, we find that none of the considered methods produces statistically fair and diverse results.
Single-Model Attribution via Final-Layer Inversion
May 26, 2023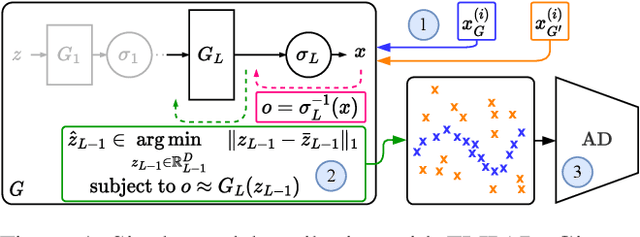
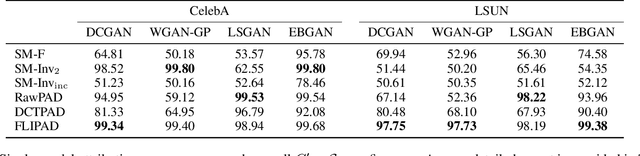

Recent groundbreaking developments on generative modeling have sparked interest in practical single-model attribution. Such methods predict whether a sample was generated by a specific generator or not, for instance, to prove intellectual property theft. However, previous works are either limited to the closed-world setting or require undesirable changes of the generative model. We address these shortcomings by proposing FLIPAD, a new approach for single-model attribution in the open-world setting based on final-layer inversion and anomaly detection. We show that the utilized final-layer inversion can be reduced to a convex lasso optimization problem, making our approach theoretically sound and computationally efficient. The theoretical findings are accompanied by an experimental study demonstrating the effectiveness of our approach, outperforming the existing methods.
Marginal Tail-Adaptive Normalizing Flows
Jun 27, 2022
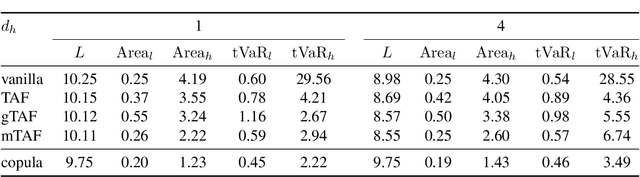
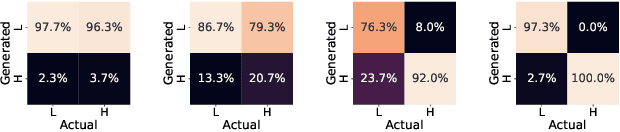

Learning the tail behavior of a distribution is a notoriously difficult problem. By definition, the number of samples from the tail is small, and deep generative models, such as normalizing flows, tend to concentrate on learning the body of the distribution. In this paper, we focus on improving the ability of normalizing flows to correctly capture the tail behavior and, thus, form more accurate models. We prove that the marginal tailedness of an autoregressive flow can be controlled via the tailedness of the marginals of its base distribution. This theoretical insight leads us to a novel type of flows based on flexible base distributions and data-driven linear layers. An empirical analysis shows that the proposed method improves on the accuracy -- especially on the tails of the distribution -- and is able to generate heavy-tailed data. We demonstrate its application on a weather and climate example, in which capturing the tail behavior is essential.
Copula-Based Normalizing Flows
Jul 15, 2021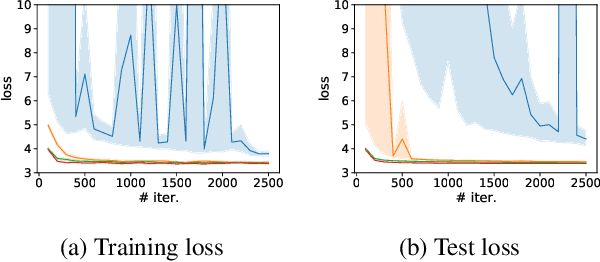
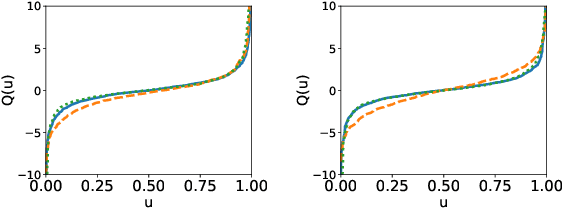
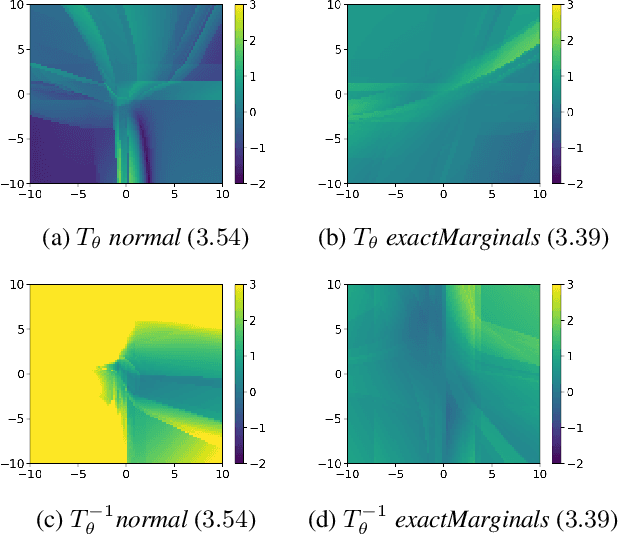
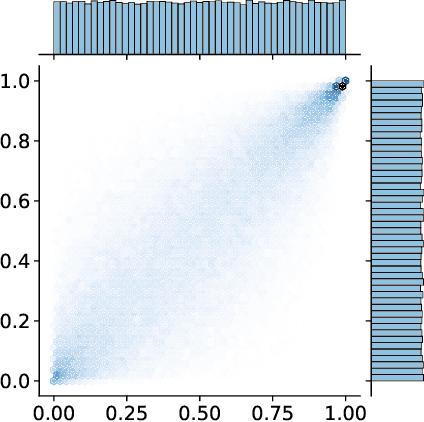
Normalizing flows, which learn a distribution by transforming the data to samples from a Gaussian base distribution, have proven powerful density approximations. But their expressive power is limited by this choice of the base distribution. We, therefore, propose to generalize the base distribution to a more elaborate copula distribution to capture the properties of the target distribution more accurately. In a first empirical analysis, we demonstrate that this replacement can dramatically improve the vanilla normalizing flows in terms of flexibility, stability, and effectivity for heavy-tailed data. Our results suggest that the improvements are related to an increased local Lipschitz-stability of the learned flow.
Thresholded Adaptive Validation: Tuning the Graphical Lasso for Graph Recovery
May 01, 2020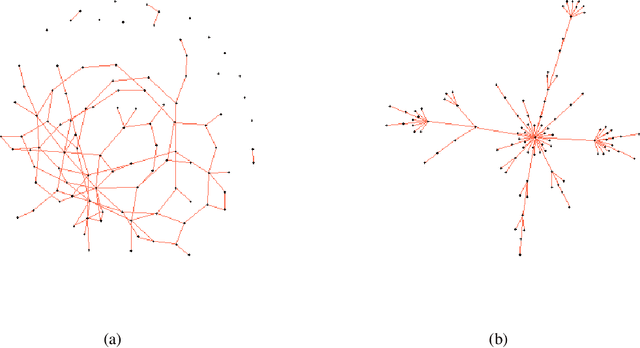
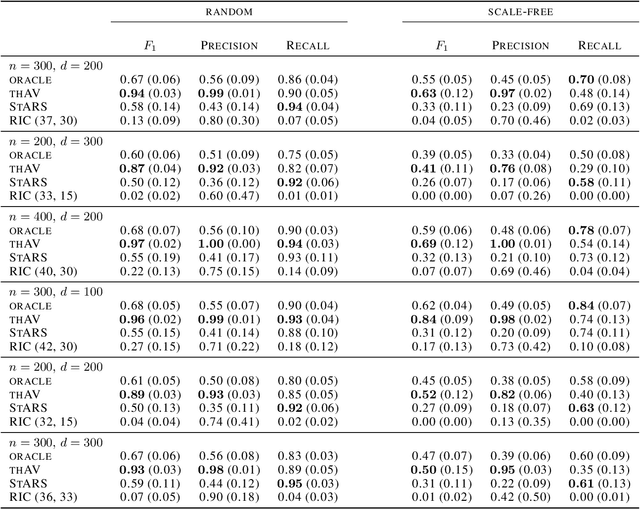
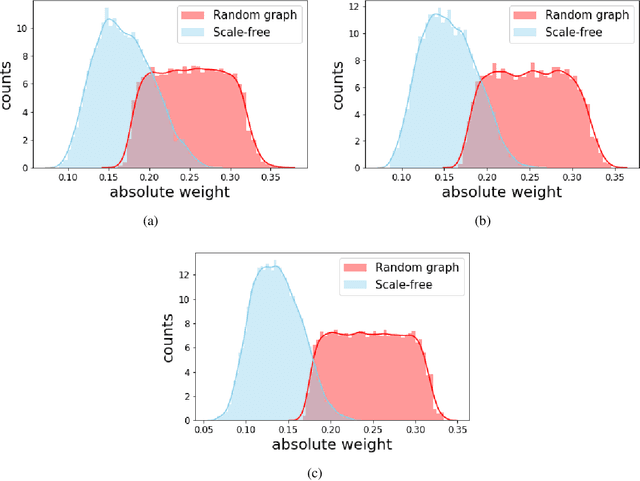
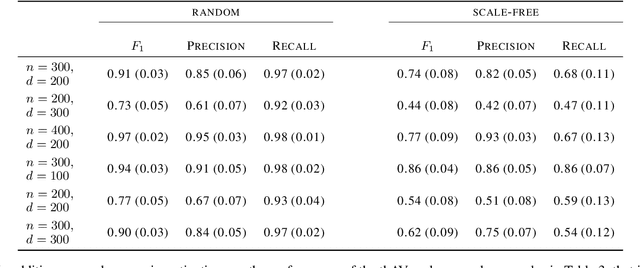
The graphical lasso is the most popular estimator in Gaussian graphical models, but its performance hinges on a regularization parameter that needs to be calibrated to each application at hand. In this paper, we propose a novel calibration scheme for this parameter. The scheme is equipped with theoretical guarantees and motivates a thresholding pipeline that can improve graph recovery. Moreover, requiring at most one line search over the regularization path of the graphical lasso, the calibration scheme is computationally more efficient than competing schemes that are based on resampling. Finally, we show in simulations that our approach can improve on the graph recovery of other approaches considerably.