 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBIAS-ID: A Framework for Analyzing Transformation Biases in AI-Generated Image Detectors
May 29, 2026Given the surge of harmful AI-generated imagery online, reliably distinguishing authentic images from generated ones has become an urgent research topic. While many proposed detection methods perform well under controlled settings, they often collapse when tested on real-world data. A potential root cause are subtle biases in the detectors' training data. As a result, detectors may rely on spurious correlations instead of learning true forensic artifacts. While a recent line of work has identified the problem, there is not yet an established protocol to evaluate how biased a detector actually is. In this work, we therefore take a step back: First, we discuss what it means for a detector to be biased, and how this differs from a lack of robustness. Second, we propose BIAS-ID, a transparent framework for analyzing and quantifying the presence of transformation biases in AI-generated image detectors. We validate our framework by performing an evaluation of six detectors across two datasets, revealing that several state-of-the-art detection methods are strongly affected by biases. Our results highlight the importance of bias-aware evaluation for developing reliable AI-generated image detectors.
DepthKV: Layer-Dependent KV Cache Pruning for Long-Context LLM Inference
Apr 27, 2026Long-context reasoning is a critical capability of large language models (LLMs), enabling applications such as long-document understanding, summarization, and code generation. However, efficient autoregressive inference relies on the key-value (KV) cache, whose memory footprint grows linearly with sequence length, leading to a major memory bottleneck. To mitigate this overhead, KV cache pruning methods discard cached tokens with low attention scores during inference. Most existing methods apply a uniform pruning ratio across layers, implicitly assuming that all layers contribute equally to overall model performance. We show that this assumption is suboptimal, as layers differ significantly in their sensitivity to pruning. We propose DepthKV, a layer-dependent pruning framework that allocates a fixed global KV budget across layers based on their sensitivity, rather than using a uniform allocation. Across multiple models and tasks, DepthKV consistently outperforms uniform pruning at the same global pruning ratio, demonstrating more effective utilization of the KV cache budget through layer-dependent allocation.
Revisiting Neural Activation Coverage for Uncertainty Estimation
Apr 24, 2026Neural activation coverage (NAC) is a recently-proposed technique for out-of-distribution detection and generalization. We build upon this promising foundation and extend the method to work as an uncertainty estimation technique for already-trained artificial neural networks in the domain of regression. Our experiments confirm NAC uncertainty scores to be more meaningful than other techniques, e.g. Monte-Carlo Dropout.
On the Robustness of Watermarking for Autoregressive Image Generation
Apr 13, 2026The proliferation of autoregressive (AR) image generators demands reliable detection and attribution of their outputs to mitigate misinformation, and to filter synthetic images from training data to prevent model collapse. To address this need, watermarking techniques, specifically designed for AR models, embed a subtle signal at generation time, enabling downstream verification through a corresponding watermark detector. In this work, we study these schemes and demonstrate their vulnerability to both watermark removal and forgery attacks. We assess existing attacks and further introduce three new attacks: (i) a vector-quantized regeneration removal attack, (ii) adversarial optimization-based attack, and (iii) a frequency injection attack. Our evaluation reveals that removal and forgery attacks can be effective with access to a single watermarked reference image and without access to original model parameters or watermarking secrets. Our findings indicate that existing watermarking schemes for AR image generation do not reliably support synthetic content detection for dataset filtering. Moreover, they enable Watermark Mimicry, whereby authentic images can be manipulated to imitate a generator's watermark and trigger false detection to prevent their inclusion in future model training.
Precision-Varying Prediction (PVP): Robustifying ASR systems against adversarial attacks
Mar 23, 2026With the increasing deployment of automated and agentic systems, ensuring the adversarial robustness of automatic speech recognition (ASR) models has become critical. We observe that changing the precision of an ASR model during inference reduces the likelihood of adversarial attacks succeeding. We take advantage of this fact to make the models more robust by simple random sampling of the precision during prediction. Moreover, the insight can be turned into an adversarial example detection strategy by comparing outputs resulting from different precisions and leveraging a simple Gaussian classifier. An experimental analysis demonstrates a significant increase in robustness and competitive detection performance for various ASR models and attack types.
SAMSEM -- A Generic and Scalable Approach for IC Metal Line Segmentation
Mar 17, 2026In light of globalized hardware supply chains, the assurance of hardware components has gained significant interest, particularly in cryptographic applications and high-stakes scenarios. Identifying metal lines on scanning electron microscope (SEM) images of integrated circuits (ICs) is one essential step in verifying the absence of malicious circuitry in chips manufactured in untrusted environments. Due to varying manufacturing processes and technologies, such verification usually requires tuning parameters and algorithms for each target IC. Often, a machine learning model trained on images of one IC fails to accurately detect metal lines on other ICs. To address this challenge, we create SAMSEM by adapting Meta's Segment Anything Model 2 (SAM2) to the domain of IC metal line segmentation. Specifically, we develop a multi-scale segmentation approach that can handle SEM images of varying sizes, resolutions, and magnifications. Furthermore, we deploy a topology-based loss alongside pixel-based losses to focus our segmentation on electrical connectivity rather than pixel-level accuracy. Based on a hyperparameter optimization, we then fine-tune the SAM2 model to obtain a model that generalizes across different technology nodes, manufacturing materials, sample preparation methods, and SEM imaging technologies. To this end, we leverage an unprecedented dataset of SEM images obtained from 48 metal layers across 14 different ICs. When fine-tuned on seven ICs, SAMSEM achieves an error rate as low as 0.72% when evaluated on other images from the same ICs. For the remaining seven unseen ICs, it still achieves error rates as low as 5.53%. Finally, when fine-tuned on all 14 ICs, we observe an error rate of 0.62%. Hence, SAMSEM proves to be a reliable tool that significantly advances the frontier in metal line segmentation, a key challenge in post-manufacturing IC verification.
Towards an Optimal Control Perspective of ResNet Training
Jun 26, 2025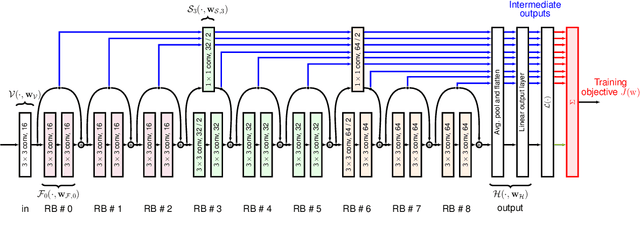
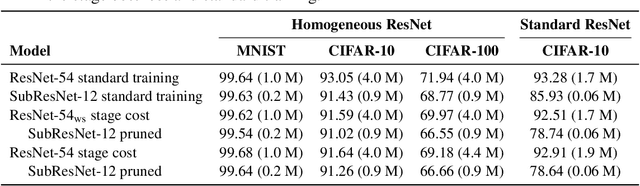
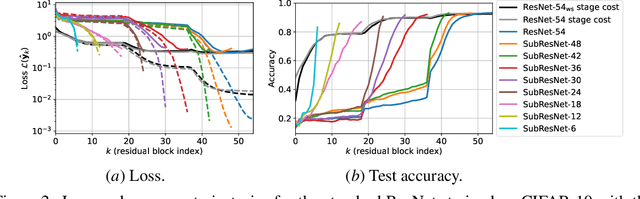
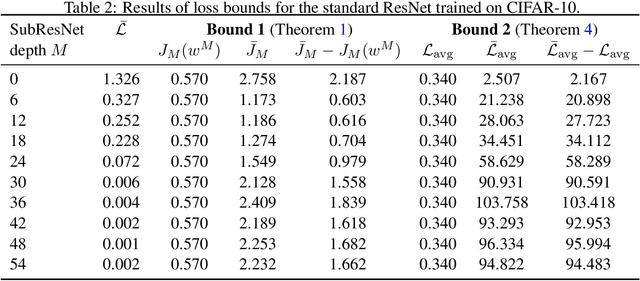
We propose a training formulation for ResNets reflecting an optimal control problem that is applicable for standard architectures and general loss functions. We suggest bridging both worlds via penalizing intermediate outputs of hidden states corresponding to stage cost terms in optimal control. For standard ResNets, we obtain intermediate outputs by propagating the state through the subsequent skip connections and the output layer. We demonstrate that our training dynamic biases the weights of the unnecessary deeper residual layers to vanish. This indicates the potential for a theory-grounded layer pruning strategy.
RAID: A Dataset for Testing the Adversarial Robustness of AI-Generated Image Detectors
Jun 09, 2025AI-generated images have reached a quality level at which humans are incapable of reliably distinguishing them from real images. To counteract the inherent risk of fraud and disinformation, the detection of AI-generated images is a pressing challenge and an active research topic. While many of the presented methods claim to achieve high detection accuracy, they are usually evaluated under idealized conditions. In particular, the adversarial robustness is often neglected, potentially due to a lack of awareness or the substantial effort required to conduct a comprehensive robustness analysis. In this work, we tackle this problem by providing a simpler means to assess the robustness of AI-generated image detectors. We present RAID (Robust evaluation of AI-generated image Detectors), a dataset of 72k diverse and highly transferable adversarial examples. The dataset is created by running attacks against an ensemble of seven state-of-the-art detectors and images generated by four different text-to-image models. Extensive experiments show that our methodology generates adversarial images that transfer with a high success rate to unseen detectors, which can be used to quickly provide an approximate yet still reliable estimate of a detector's adversarial robustness. Our findings indicate that current state-of-the-art AI-generated image detectors can be easily deceived by adversarial examples, highlighting the critical need for the development of more robust methods. We release our dataset at https://huggingface.co/datasets/aimagelab/RAID and evaluation code at https://github.com/pralab/RAID.
Security Benefits and Side Effects of Labeling AI-Generated Images
May 28, 2025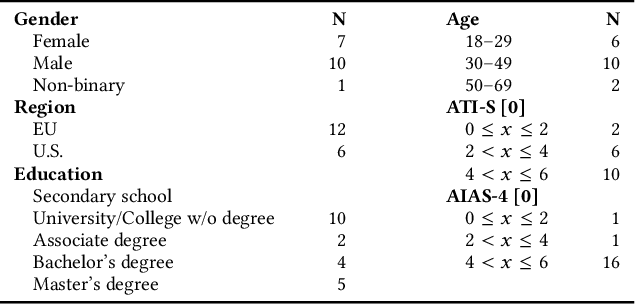

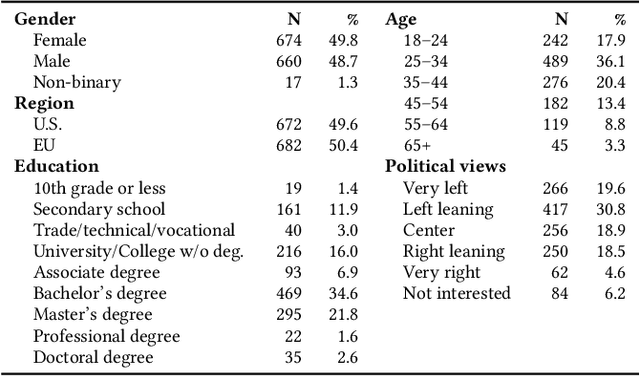
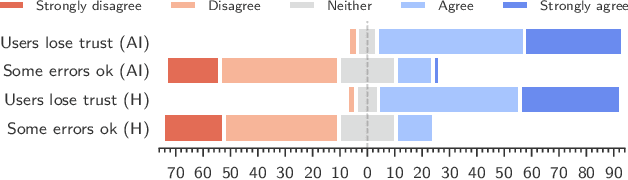
Generative artificial intelligence is developing rapidly, impacting humans' interaction with information and digital media. It is increasingly used to create deceptively realistic misinformation, so lawmakers have imposed regulations requiring the disclosure of AI-generated content. However, only little is known about whether these labels reduce the risks of AI-generated misinformation. Our work addresses this research gap. Focusing on AI-generated images, we study the implications of labels, including the possibility of mislabeling. Assuming that simplicity, transparency, and trust are likely to impact the successful adoption of such labels, we first qualitatively explore users' opinions and expectations of AI labeling using five focus groups. Second, we conduct a pre-registered online survey with over 1300 U.S. and EU participants to quantitatively assess the effect of AI labels on users' ability to recognize misinformation containing either human-made or AI-generated images. Our focus groups illustrate that, while participants have concerns about the practical implementation of labeling, they consider it helpful in identifying AI-generated images and avoiding deception. However, considering security benefits, our survey revealed an ambiguous picture, suggesting that users might over-rely on labels. While inaccurate claims supported by labeled AI-generated images were rated less credible than those with unlabeled AI-images, the belief in accurate claims also decreased when accompanied by a labeled AI-generated image. Moreover, we find the undesired side effect that human-made images conveying inaccurate claims were perceived as more credible in the presence of labels.
Towards A Correct Usage of Cryptography in Semantic Watermarks for Diffusion Models
Mar 14, 2025Semantic watermarking methods enable the direct integration of watermarks into the generation process of latent diffusion models by only modifying the initial latent noise. One line of approaches building on Gaussian Shading relies on cryptographic primitives to steer the sampling process of the latent noise. However, we identify several issues in the usage of cryptographic techniques in Gaussian Shading, particularly in its proof of lossless performance and key management, causing ambiguity in follow-up works, too. In this work, we therefore revisit the cryptographic primitives for semantic watermarking. We introduce a novel, general proof of lossless performance based on IND\$-CPA security for semantic watermarks. We then discuss the configuration of the cryptographic primitives in semantic watermarks with respect to security, efficiency, and generation quality.