 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards A Correct Usage of Cryptography in Semantic Watermarks for Diffusion Models
Mar 14, 2025Semantic watermarking methods enable the direct integration of watermarks into the generation process of latent diffusion models by only modifying the initial latent noise. One line of approaches building on Gaussian Shading relies on cryptographic primitives to steer the sampling process of the latent noise. However, we identify several issues in the usage of cryptographic techniques in Gaussian Shading, particularly in its proof of lossless performance and key management, causing ambiguity in follow-up works, too. In this work, we therefore revisit the cryptographic primitives for semantic watermarking. We introduce a novel, general proof of lossless performance based on IND\$-CPA security for semantic watermarks. We then discuss the configuration of the cryptographic primitives in semantic watermarks with respect to security, efficiency, and generation quality.
Black-Box Forgery Attacks on Semantic Watermarks for Diffusion Models
Dec 04, 2024



Integrating watermarking into the generation process of latent diffusion models (LDMs) simplifies detection and attribution of generated content. Semantic watermarks, such as Tree-Rings and Gaussian Shading, represent a novel class of watermarking techniques that are easy to implement and highly robust against various perturbations. However, our work demonstrates a fundamental security vulnerability of semantic watermarks. We show that attackers can leverage unrelated models, even with different latent spaces and architectures (UNet vs DiT), to perform powerful and realistic forgery attacks. Specifically, we design two watermark forgery attacks. The first imprints a targeted watermark into real images by manipulating the latent representation of an arbitrary image in an unrelated LDM to get closer to the latent representation of a watermarked image. We also show that this technique can be used for watermark removal. The second attack generates new images with the target watermark by inverting a watermarked image and re-generating it with an arbitrary prompt. Both attacks just need a single reference image with the target watermark. Overall, our findings question the applicability of semantic watermarks by revealing that attackers can easily forge or remove these watermarks under realistic conditions.
Layout-to-Image Generation with Localized Descriptions using ControlNet with Cross-Attention Control
Feb 20, 2024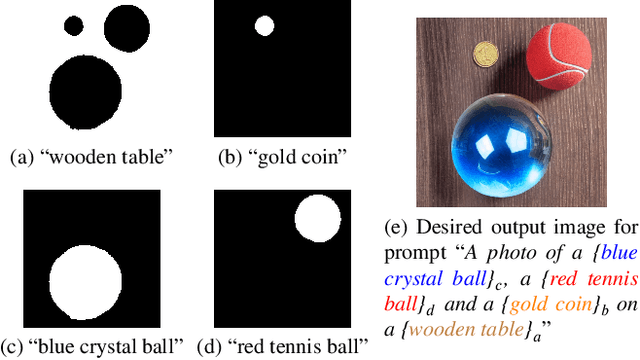
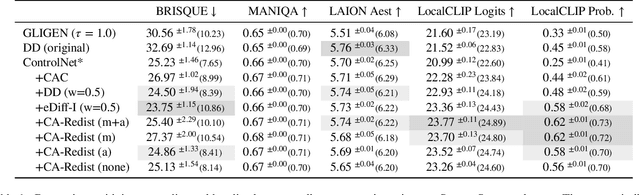
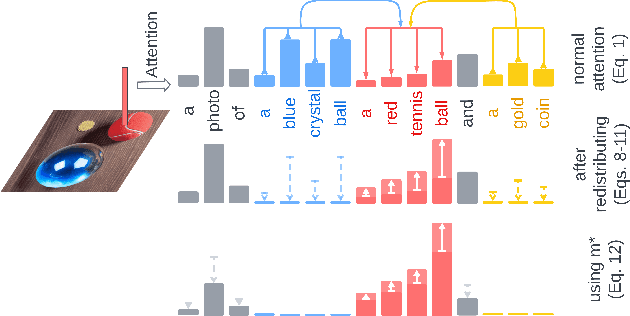
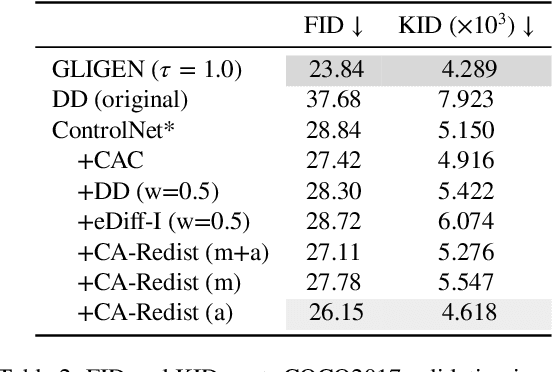
While text-to-image diffusion models can generate highquality images from textual descriptions, they generally lack fine-grained control over the visual composition of the generated images. Some recent works tackle this problem by training the model to condition the generation process on additional input describing the desired image layout. Arguably the most popular among such methods, ControlNet, enables a high degree of control over the generated image using various types of conditioning inputs (e.g. segmentation maps). However, it still lacks the ability to take into account localized textual descriptions that indicate which image region is described by which phrase in the prompt. In this work, we show the limitations of ControlNet for the layout-to-image task and enable it to use localized descriptions using a training-free approach that modifies the crossattention scores during generation. We adapt and investigate several existing cross-attention control methods in the context of ControlNet and identify shortcomings that cause failure (concept bleeding) or image degradation under specific conditions. To address these shortcomings, we develop a novel cross-attention manipulation method in order to maintain image quality while improving control. Qualitative and quantitative experimental studies focusing on challenging cases are presented, demonstrating the effectiveness of the investigated general approach, and showing the improvements obtained by the proposed cross-attention control method.
AEROBLADE: Training-Free Detection of Latent Diffusion Images Using Autoencoder Reconstruction Error
Jan 31, 2024
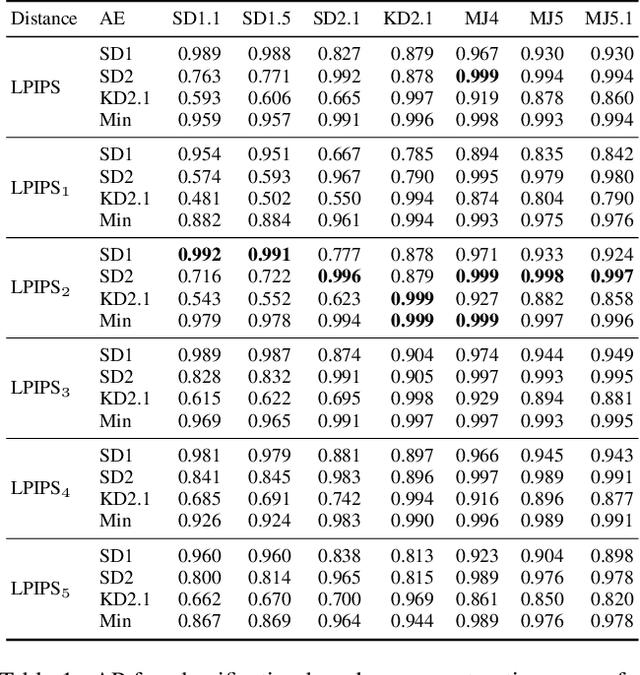
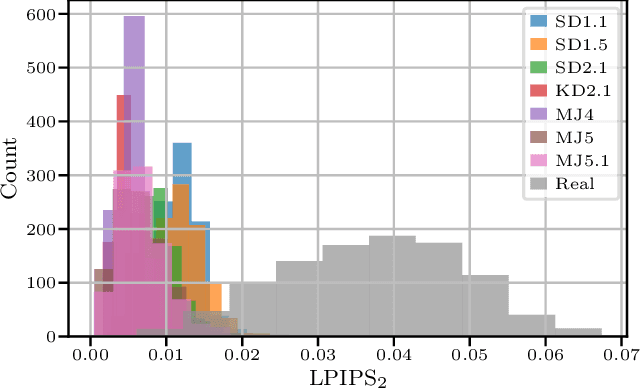

With recent text-to-image models, anyone can generate deceptively realistic images with arbitrary contents, fueling the growing threat of visual disinformation. A key enabler for generating high-resolution images with low computational cost has been the development of latent diffusion models (LDMs). In contrast to conventional diffusion models, LDMs perform the denoising process in the low-dimensional latent space of a pre-trained autoencoder (AE) instead of the high-dimensional image space. Despite their relevance, the forensic analysis of LDMs is still in its infancy. In this work we propose AEROBLADE, a novel detection method which exploits an inherent component of LDMs: the AE used to transform images between image and latent space. We find that generated images can be more accurately reconstructed by the AE than real images, allowing for a simple detection approach based on the reconstruction error. Most importantly, our method is easy to implement and does not require any training, yet nearly matches the performance of detectors that rely on extensive training. We empirically demonstrate that AEROBLADE is effective against state-of-the-art LDMs including Stable Diffusion and Midjourney. Beyond detection, our approach allows for the qualitative analysis of images, which can be leveraged for identifying inpainted regions.
Improving the Long-Range Performance of Gated Graph Neural Networks
Jul 19, 2020
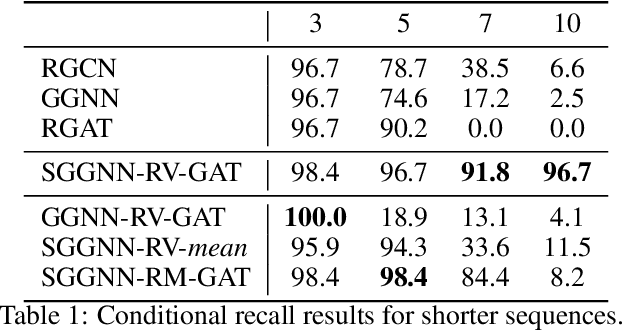
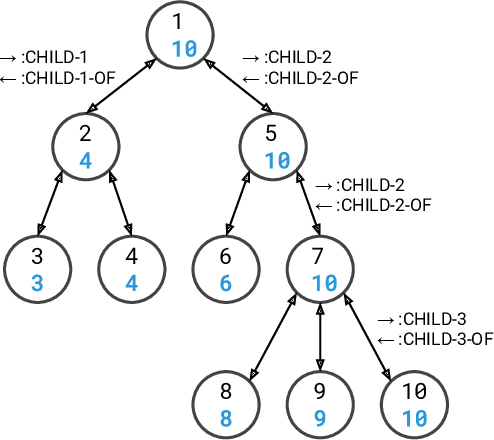
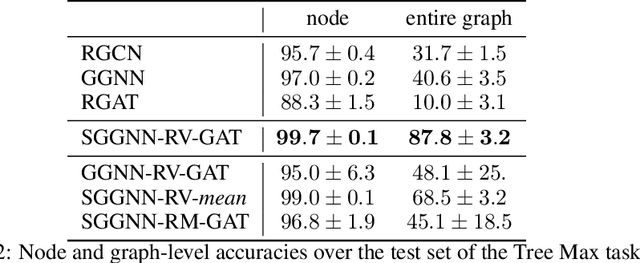
Many popular variants of graph neural networks (GNNs) that are capable of handling multi-relational graphs may suffer from vanishing gradients. In this work, we propose a novel GNN architecture based on the Gated Graph Neural Network with an improved ability to handle long-range dependencies in multi-relational graphs. An experimental analysis on different synthetic tasks demonstrates that the proposed architecture outperforms several popular GNN models.
Introduction to Neural Network based Approaches for Question Answering over Knowledge Graphs
Jul 22, 2019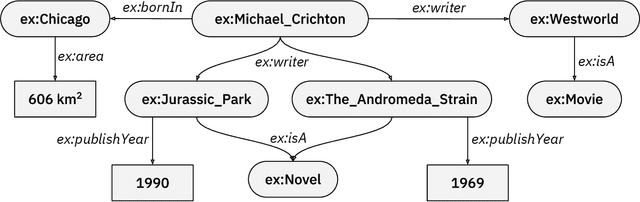
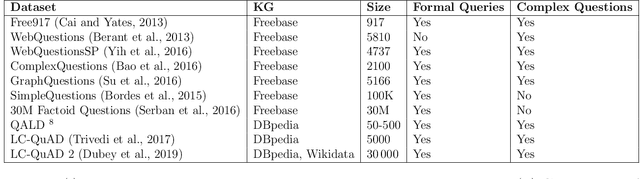
Question answering has emerged as an intuitive way of querying structured data sources, and has attracted significant advancements over the years. In this article, we provide an overview over these recent advancements, focusing on neural network based question answering systems over knowledge graphs. We introduce readers to the challenges in the tasks, current paradigms of approaches, discuss notable advancements, and outline the emerging trends in the field. Through this article, we aim to provide newcomers to the field with a suitable entry point, and ease their process of making informed decisions while creating their own QA system.
Translating Natural Language to SQL using Pointer-Generator Networks and How Decoding Order Matters
Nov 13, 2018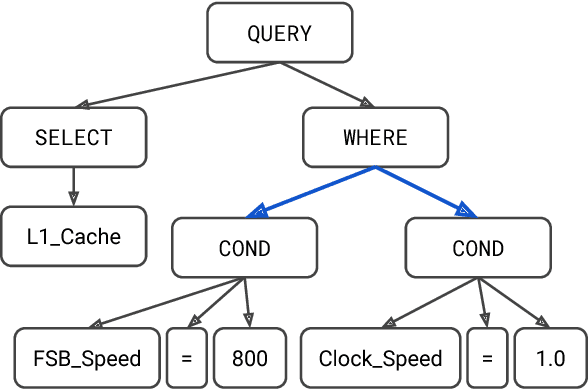
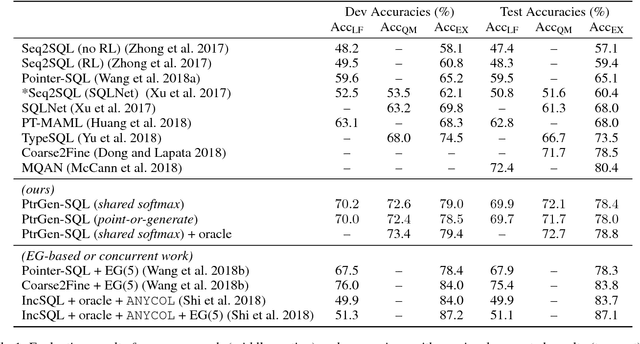
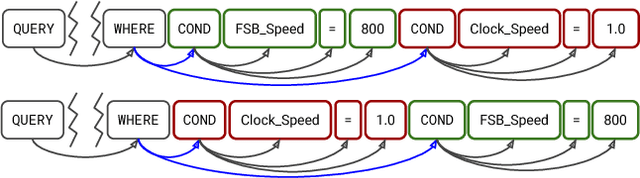
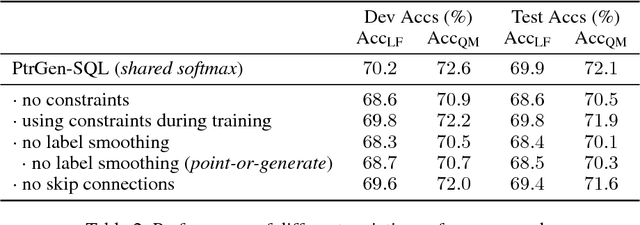
Translating natural language to SQL queries for table-based question answering is a challenging problem and has received significant attention from the research community. In this work, we extend a pointer-generator and investigate the order-matters problem in semantic parsing for SQL. Even though our model is a straightforward extension of a general-purpose pointer-generator, it outperforms early works for WikiSQL and remains competitive to concurrently introduced, more complex models. Moreover, we provide a deeper investigation of the potential order-matters problem that could arise due to having multiple correct decoding paths, and investigate the use of REINFORCE as well as a dynamic oracle in this context.
Learning to Rank Query Graphs for Complex Question Answering over Knowledge Graphs
Nov 02, 2018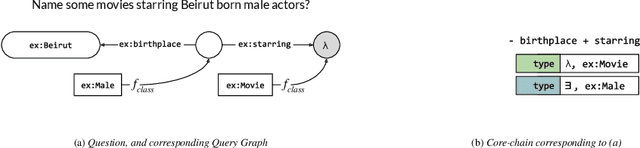
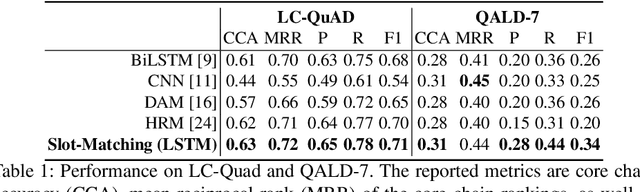
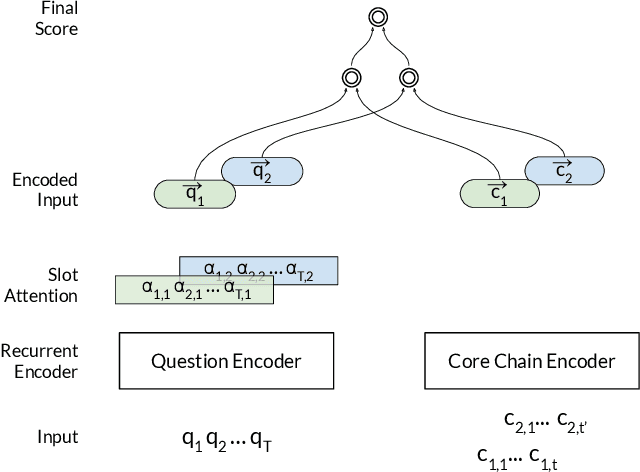
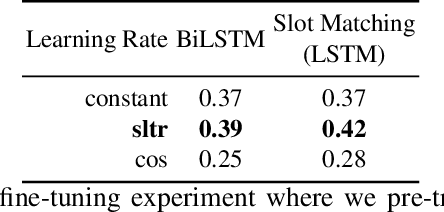
In this paper, we conduct an empirical investigation of neural query graph ranking approaches for the task of complex question answering over knowledge graphs. We experiment with six different ranking models and propose a novel self-attention based slot matching model which exploits the inherent structure of query graphs, our logical form of choice. Our proposed model generally outperforms the other models on two QA datasets over the DBpedia knowledge graph, evaluated in different settings. In addition, we show that transfer learning from the larger of those QA datasets to the smaller dataset yields substantial improvements, effectively offsetting the general lack of training data.
Incorporating Literals into Knowledge Graph Embeddings
May 25, 2018
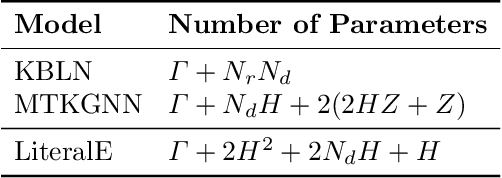
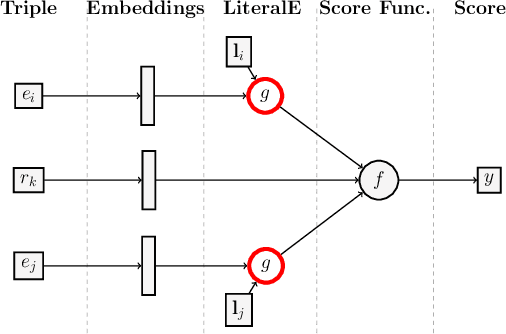
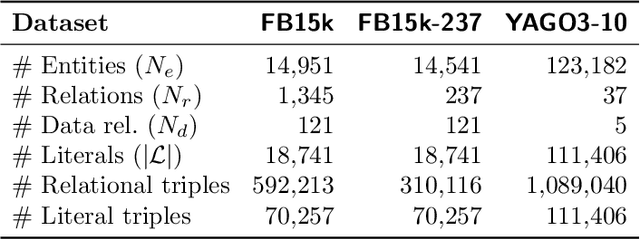
Knowledge graphs, on top of entities and their relationships, contain other important elements: literals. Literals encode interesting properties (e.g. the height) of entities that are not captured by links between entities alone. Most of the existing work on embedding (or latent feature) based knowledge graph analysis focuses mainly on the relations between entities. In this work, we study the effect of incorporating literal information into existing link prediction methods. Our approach, which we name LiteralE, is an extension that can be plugged into existing latent feature methods. LiteralE merges entity embeddings with their literal information using a learnable, parametrized function, such as a simple linear or nonlinear transformation, or a multilayer neural network. We extend several popular embedding models based on LiteralE and evaluate their performance on the task of link prediction. Despite its simplicity, LiteralE proves to be an effective way to incorporate literal information into existing embedding based methods, improving their performance on different standard datasets, which we augmented with their literals and provide as testbed for further research.