 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCurate-Train-Refine: A Closed-Loop Agentic Framework for Zero Shot Classification
Jan 23, 2026Large language models (LLMs) and high-capacity encoders have advanced zero and few-shot classification, but their inference cost and latency limit practical deployment. We propose training lightweight text classifiers using dynamically generated supervision from an LLM. Our method employs an iterative, agentic loop in which the LLM curates training data, analyzes model successes and failures, and synthesizes targeted examples to address observed errors. This closed-loop generation and evaluation process progressively improves data quality and adapts it to the downstream classifier and task. Across four widely used benchmarks, our approach consistently outperforms standard zero and few-shot baselines. These results indicate that LLMs can serve effectively as data curators, enabling accurate and efficient classification without the operational cost of large-model deployment.
Efficacy of Synthetic Data as a Benchmark
Sep 18, 2024Large language models (LLMs) have enabled a range of applications in zero-shot and few-shot learning settings, including the generation of synthetic datasets for training and testing. However, to reliably use these synthetic datasets, it is essential to understand how representative they are of real-world data. We investigate this by assessing the effectiveness of generating synthetic data through LLM and using it as a benchmark for various NLP tasks. Our experiments across six datasets, and three different tasks, show that while synthetic data can effectively capture performance of various methods for simpler tasks, such as intent classification, it falls short for more complex tasks like named entity recognition. Additionally, we propose a new metric called the bias factor, which evaluates the biases introduced when the same LLM is used to both generate benchmarking data and to perform the tasks. We find that smaller LLMs exhibit biases towards their own generated data, whereas larger models do not. Overall, our findings suggest that the effectiveness of synthetic data as a benchmark varies depending on the task, and that practitioners should rely on data generated from multiple larger models whenever possible.
ASR Benchmarking: Need for a More Representative Conversational Dataset
Sep 18, 2024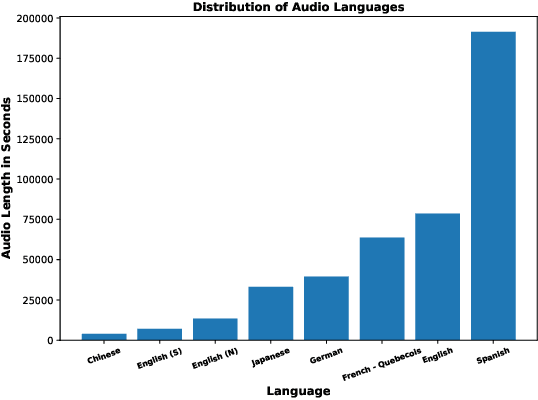

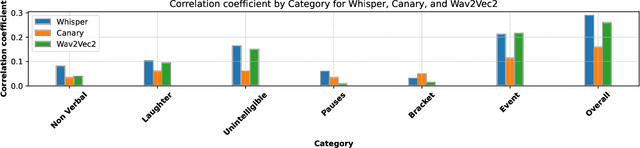
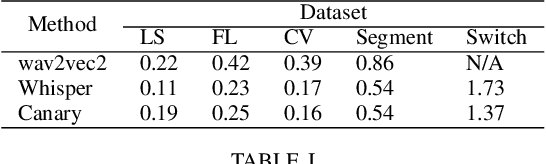
Automatic Speech Recognition (ASR) systems have achieved remarkable performance on widely used benchmarks such as LibriSpeech and Fleurs. However, these benchmarks do not adequately reflect the complexities of real-world conversational environments, where speech is often unstructured and contains disfluencies such as pauses, interruptions, and diverse accents. In this study, we introduce a multilingual conversational dataset, derived from TalkBank, consisting of unstructured phone conversation between adults. Our results show a significant performance drop across various state-of-the-art ASR models when tested in conversational settings. Furthermore, we observe a correlation between Word Error Rate and the presence of speech disfluencies, highlighting the critical need for more realistic, conversational ASR benchmarks.
Synthetic Data Generation for Intersectional Fairness by Leveraging Hierarchical Group Structure
May 23, 2024In this paper, we introduce a data augmentation approach specifically tailored to enhance intersectional fairness in classification tasks. Our method capitalizes on the hierarchical structure inherent to intersectionality, by viewing groups as intersections of their parent categories. This perspective allows us to augment data for smaller groups by learning a transformation function that combines data from these parent groups. Our empirical analysis, conducted on four diverse datasets including both text and images, reveals that classifiers trained with this data augmentation approach achieve superior intersectional fairness and are more robust to ``leveling down'' when compared to methods optimizing traditional group fairness metrics.
How to Capture Intersectional Fairness
May 21, 2023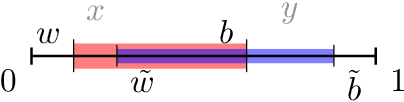
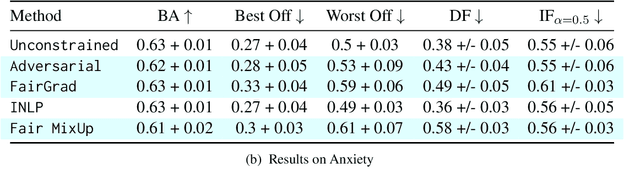
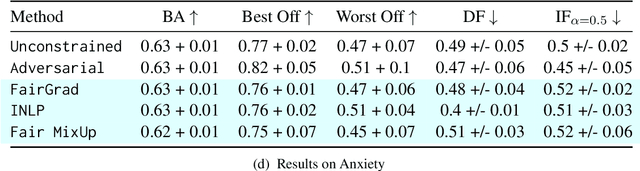
In this work, we tackle the problem of intersectional group fairness in the classification setting, where the objective is to learn discrimination-free models in the presence of several intersecting sensitive groups. First, we illustrate various shortcomings of existing fairness measures commonly used to capture intersectional fairness. Then, we propose a new framework called the $\alpha$ Intersectional Fairness framework, which combines the absolute and the relative performances between sensitive groups. Finally, we provide various analyses of our proposed framework, including the min-max and efficiency analysis. Our experiments using the proposed framework show that several in-processing fairness approaches show no improvement over a simple unconstrained approach. Moreover, we show that these approaches minimize existing fairness measures by degrading the performance of the best of the group instead of improving the worst.
FairGrad: Fairness Aware Gradient Descent
Jun 22, 2022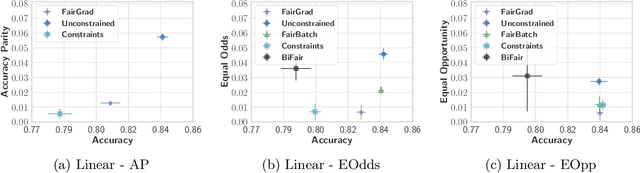

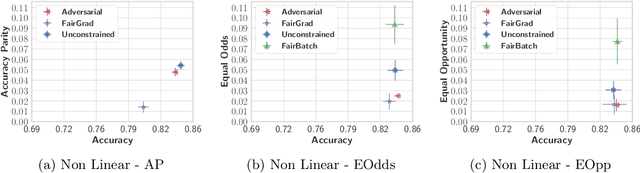
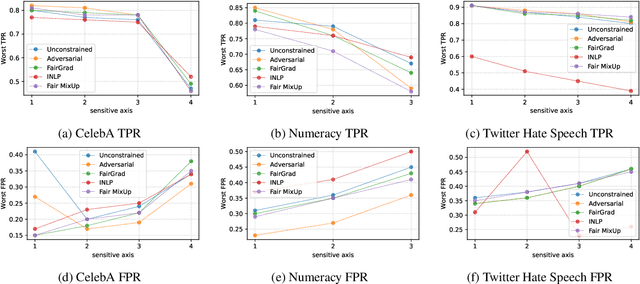
We tackle the problem of group fairness in classification, where the objective is to learn models that do not unjustly discriminate against subgroups of the population. Most existing approaches are limited to simple binary tasks or involve difficult to implement training mechanisms. This reduces their practical applicability. In this paper, we propose FairGrad, a method to enforce fairness based on a reweighting scheme that iteratively learns group specific weights based on whether they are advantaged or not. FairGrad is easy to implement and can accommodate various standard fairness definitions. Furthermore, we show that it is comparable to standard baselines over various datasets including ones used in natural language processing and computer vision.
Fair NLP Models with Differentially Private Text Encoders
May 12, 2022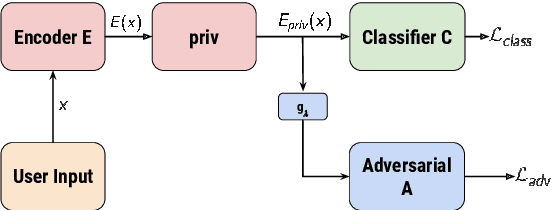
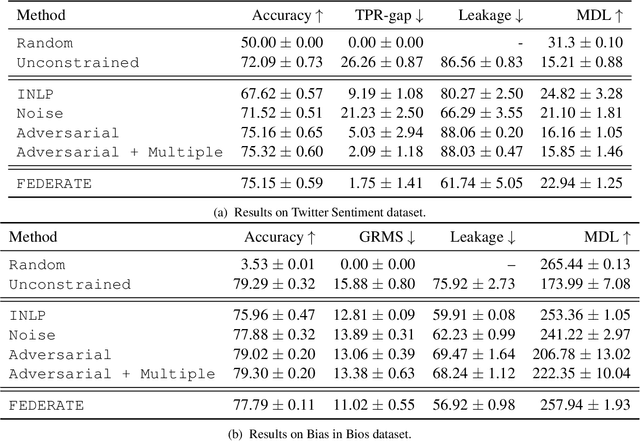
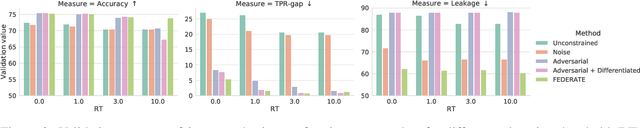
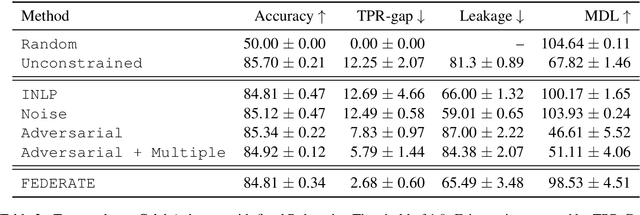
Encoded text representations often capture sensitive attributes about individuals (e.g., race or gender), which raise privacy concerns and can make downstream models unfair to certain groups. In this work, we propose FEDERATE, an approach that combines ideas from differential privacy and adversarial training to learn private text representations which also induces fairer models. We empirically evaluate the trade-off between the privacy of the representations and the fairness and accuracy of the downstream model on four NLP datasets. Our results show that FEDERATE consistently improves upon previous methods, and thus suggest that privacy and fairness can positively reinforce each other.
Message Passing for Hyper-Relational Knowledge Graphs
Sep 22, 2020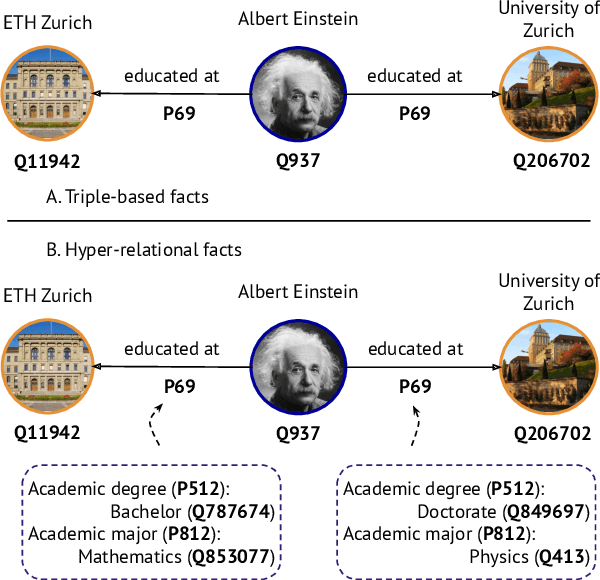
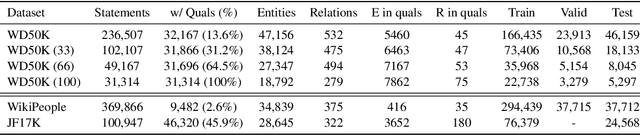
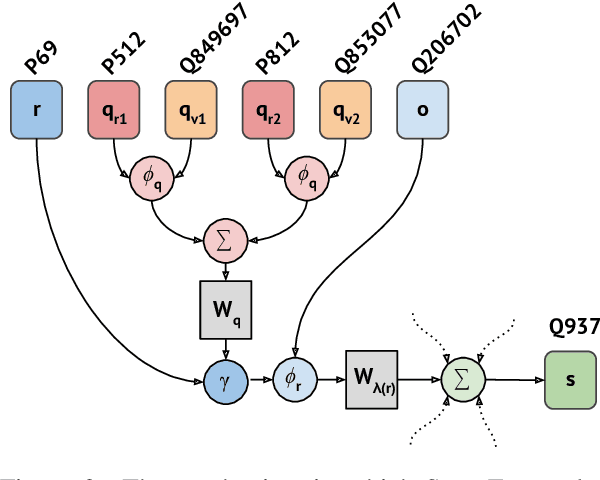
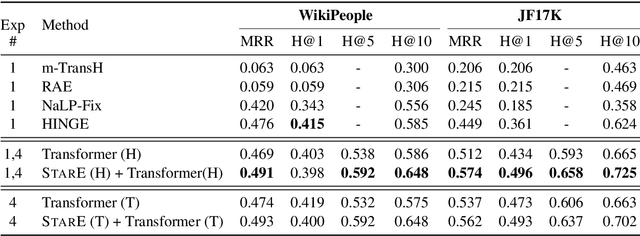
Hyper-relational knowledge graphs (KGs) (e.g., Wikidata) enable associating additional key-value pairs along with the main triple to disambiguate, or restrict the validity of a fact. In this work, we propose a message passing based graph encoder - StarE capable of modeling such hyper-relational KGs. Unlike existing approaches, StarE can encode an arbitrary number of additional information (qualifiers) along with the main triple while keeping the semantic roles of qualifiers and triples intact. We also demonstrate that existing benchmarks for evaluating link prediction (LP) performance on hyper-relational KGs suffer from fundamental flaws and thus develop a new Wikidata-based dataset - WD50K. Our experiments demonstrate that StarE based LP model outperforms existing approaches across multiple benchmarks. We also confirm that leveraging qualifiers is vital for link prediction with gains up to 25 MRR points compared to triple-based representations.
Introduction to Neural Network based Approaches for Question Answering over Knowledge Graphs
Jul 22, 2019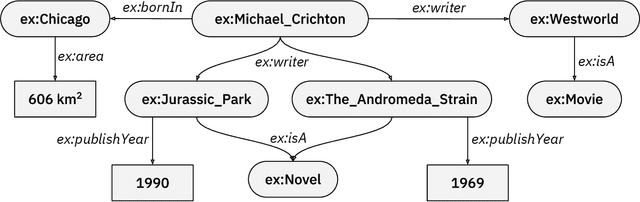
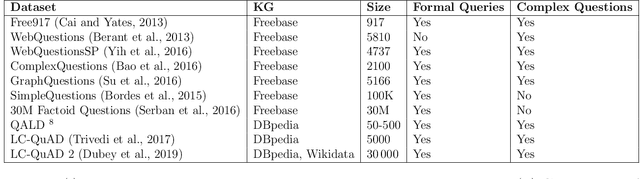
Question answering has emerged as an intuitive way of querying structured data sources, and has attracted significant advancements over the years. In this article, we provide an overview over these recent advancements, focusing on neural network based question answering systems over knowledge graphs. We introduce readers to the challenges in the tasks, current paradigms of approaches, discuss notable advancements, and outline the emerging trends in the field. Through this article, we aim to provide newcomers to the field with a suitable entry point, and ease their process of making informed decisions while creating their own QA system.
Learning to Rank Query Graphs for Complex Question Answering over Knowledge Graphs
Nov 02, 2018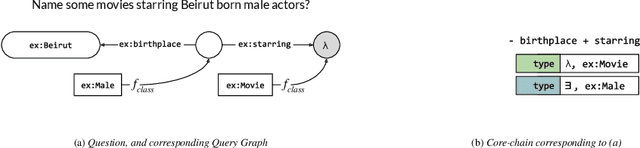
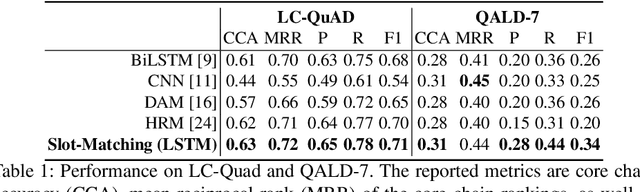
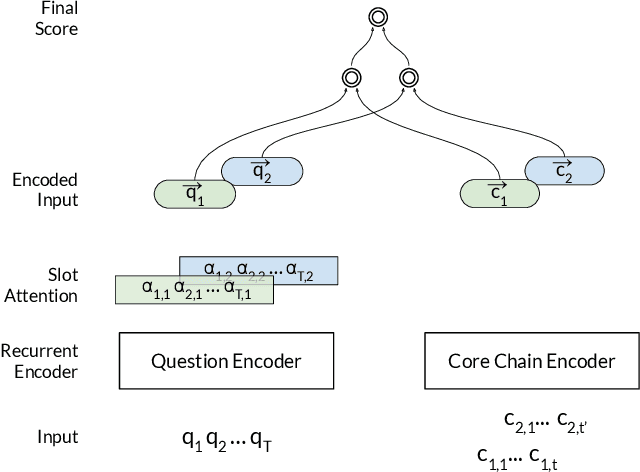
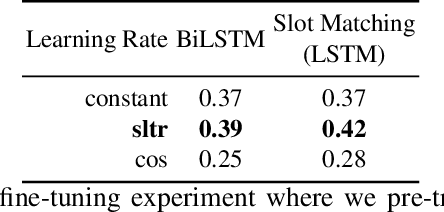
In this paper, we conduct an empirical investigation of neural query graph ranking approaches for the task of complex question answering over knowledge graphs. We experiment with six different ranking models and propose a novel self-attention based slot matching model which exploits the inherent structure of query graphs, our logical form of choice. Our proposed model generally outperforms the other models on two QA datasets over the DBpedia knowledge graph, evaluated in different settings. In addition, we show that transfer learning from the larger of those QA datasets to the smaller dataset yields substantial improvements, effectively offsetting the general lack of training data.