 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTo Word Senses and Beyond: Inducing Concepts with Contextualized Language Models
Jun 28, 2024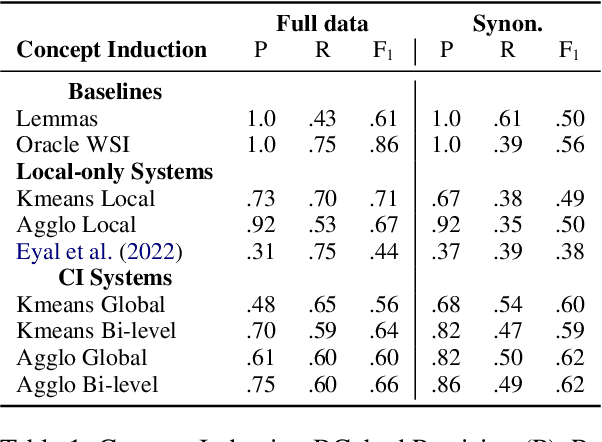
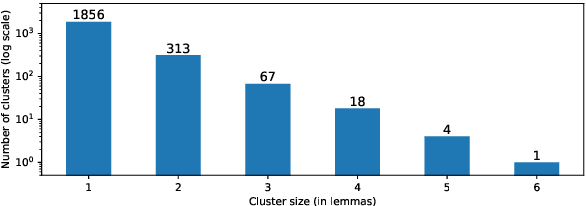
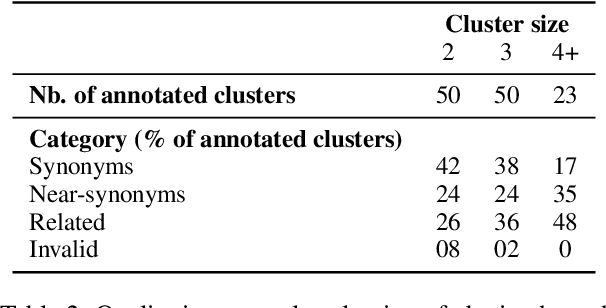
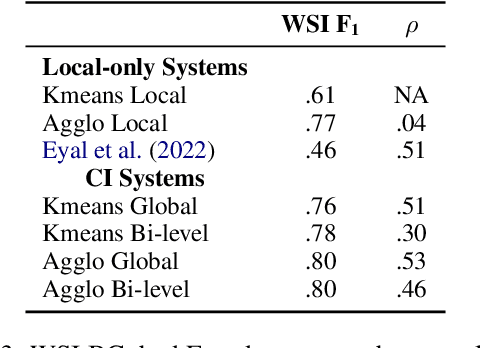
Polysemy and synonymy are two crucial interrelated facets of lexical ambiguity. While both phenomena have been studied extensively in NLP, leading to dedicated systems, they are often been considered independently. While many tasks dealing with polysemy (e.g. Word Sense Disambiguiation or Induction) highlight the role of a word's senses, the study of synonymy is rooted in the study of concepts, i.e. meaning shared across the lexicon. In this paper, we introduce Concept Induction, the unsupervised task of learning a soft clustering among words that defines a set of concepts directly from data. This task generalizes that of Word Sense Induction. We propose a bi-level approach to Concept Induction that leverages both a local lemma-centric view and a global cross-lexicon perspective to induce concepts. We evaluate the obtained clustering on SemCor's annotated data and obtain good performances (BCubed F1 above 0.60). We find that the local and the global levels are mutually beneficial to induce concepts and also senses in our setting. Finally, we create static embeddings representing our induced concepts and use them on the Word-in-Context task, obtaining competitive performances with the State-of-the-Art.
Synthetic Data Generation for Intersectional Fairness by Leveraging Hierarchical Group Structure
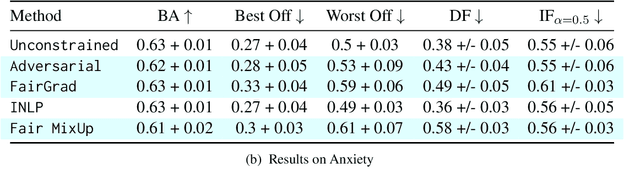
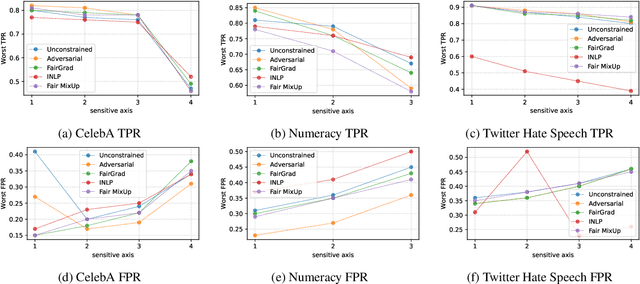
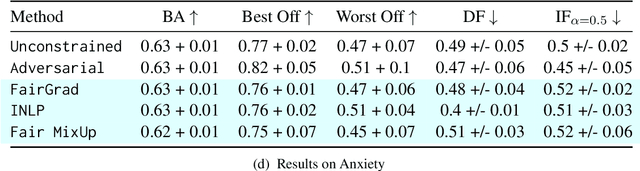
May 23, 2024In this paper, we introduce a data augmentation approach specifically tailored to enhance intersectional fairness in classification tasks. Our method capitalizes on the hierarchical structure inherent to intersectionality, by viewing groups as intersections of their parent categories. This perspective allows us to augment data for smaller groups by learning a transformation function that combines data from these parent groups. Our empirical analysis, conducted on four diverse datasets including both text and images, reveals that classifiers trained with this data augmentation approach achieve superior intersectional fairness and are more robust to ``leveling down'' when compared to methods optimizing traditional group fairness metrics.
A Tale of Two Laws of Semantic Change: Predicting Synonym Changes with Distributional Semantic Models
May 30, 2023



Lexical Semantic Change is the study of how the meaning of words evolves through time. Another related question is whether and how lexical relations over pairs of words, such as synonymy, change over time. There are currently two competing, apparently opposite hypotheses in the historical linguistic literature regarding how synonymous words evolve: the Law of Differentiation (LD) argues that synonyms tend to take on different meanings over time, whereas the Law of Parallel Change (LPC) claims that synonyms tend to undergo the same semantic change and therefore remain synonyms. So far, there has been little research using distributional models to assess to what extent these laws apply on historical corpora. In this work, we take a first step toward detecting whether LD or LPC operates for given word pairs. After recasting the problem into a more tractable task, we combine two linguistic resources to propose the first complete evaluation framework on this problem and provide empirical evidence in favor of a dominance of LD. We then propose various computational approaches to the problem using Distributional Semantic Models and grounded in recent literature on Lexical Semantic Change detection. Our best approaches achieve a balanced accuracy above 0.6 on our dataset. We discuss challenges still faced by these approaches, such as polysemy or the potential confusion between synonymy and hypernymy.
How to Capture Intersectional Fairness
May 21, 2023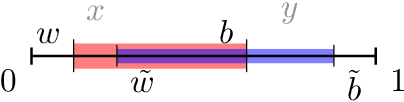
In this work, we tackle the problem of intersectional group fairness in the classification setting, where the objective is to learn discrimination-free models in the presence of several intersecting sensitive groups. First, we illustrate various shortcomings of existing fairness measures commonly used to capture intersectional fairness. Then, we propose a new framework called the $\alpha$ Intersectional Fairness framework, which combines the absolute and the relative performances between sensitive groups. Finally, we provide various analyses of our proposed framework, including the min-max and efficiency analysis. Our experiments using the proposed framework show that several in-processing fairness approaches show no improvement over a simple unconstrained approach. Moreover, we show that these approaches minimize existing fairness measures by degrading the performance of the best of the group instead of improving the worst.
Exploring Category Structure with Contextual Language Models and Lexical Semantic Networks
Feb 14, 2023Recent work on predicting category structure with distributional models, using either static word embeddings (Heyman and Heyman, 2019) or contextualized language models (CLMs) (Misra et al., 2021), report low correlations with human ratings, thus calling into question their plausibility as models of human semantic memory. In this work, we revisit this question testing a wider array of methods for probing CLMs for predicting typicality scores. Our experiments, using BERT (Devlin et al., 2018), show the importance of using the right type of CLM probes, as our best BERT-based typicality prediction methods substantially improve over previous works. Second, our results highlight the importance of polysemy in this task: our best results are obtained when using a disambiguation mechanism. Finally, additional experiments reveal that Information Contentbased WordNet (Miller, 1995), also endowed with disambiguation, match the performance of the best BERT-based method, and in fact capture complementary information, which can be combined with BERT to achieve enhanced typicality predictions.
Fair NLP Models with Differentially Private Text Encoders
May 12, 2022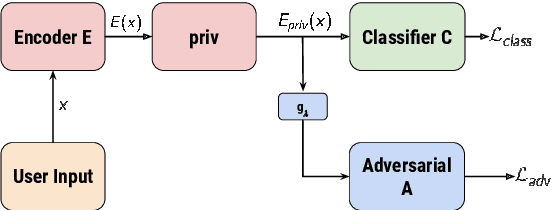
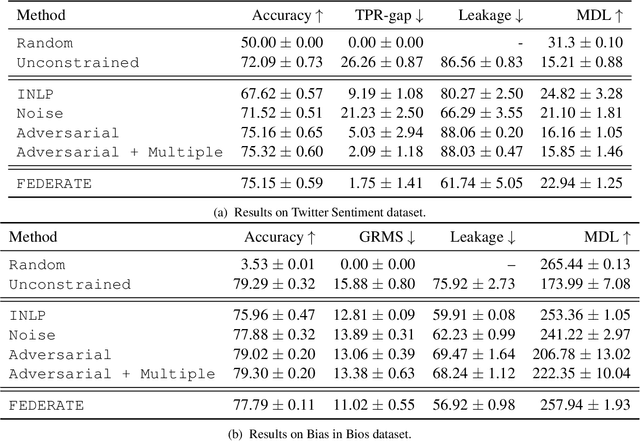
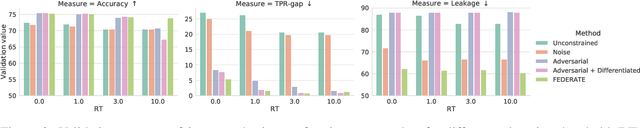
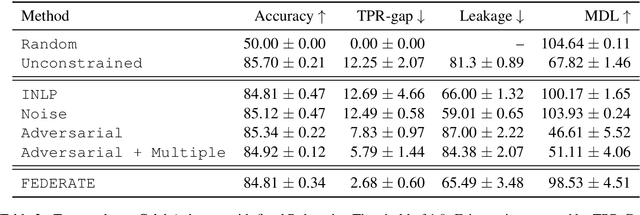
Encoded text representations often capture sensitive attributes about individuals (e.g., race or gender), which raise privacy concerns and can make downstream models unfair to certain groups. In this work, we propose FEDERATE, an approach that combines ideas from differential privacy and adversarial training to learn private text representations which also induces fairer models. We empirically evaluate the trade-off between the privacy of the representations and the fairness and accuracy of the downstream model on four NLP datasets. Our results show that FEDERATE consistently improves upon previous methods, and thus suggest that privacy and fairness can positively reinforce each other.
Learning Recursive Segments for Discourse Parsing
Mar 28, 2010Automatically detecting discourse segments is an important preliminary step towards full discourse parsing. Previous research on discourse segmentation have relied on the assumption that elementary discourse units (EDUs) in a document always form a linear sequence (i.e., they can never be nested). Unfortunately, this assumption turns out to be too strong, for some theories of discourse like SDRT allows for nested discourse units. In this paper, we present a simple approach to discourse segmentation that is able to produce nested EDUs. Our approach builds on standard multi-class classification techniques combined with a simple repairing heuristic that enforces global coherence. Our system was developed and evaluated on the first round of annotations provided by the French Annodis project (an ongoing effort to create a discourse bank for French). Cross-validated on only 47 documents (1,445 EDUs), our system achieves encouraging performance results with an F-score of 73% for finding EDUs.