 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Interval-based Tokenization for Pitch Representation in Symbolic Music Analysis
Jan 08, 2025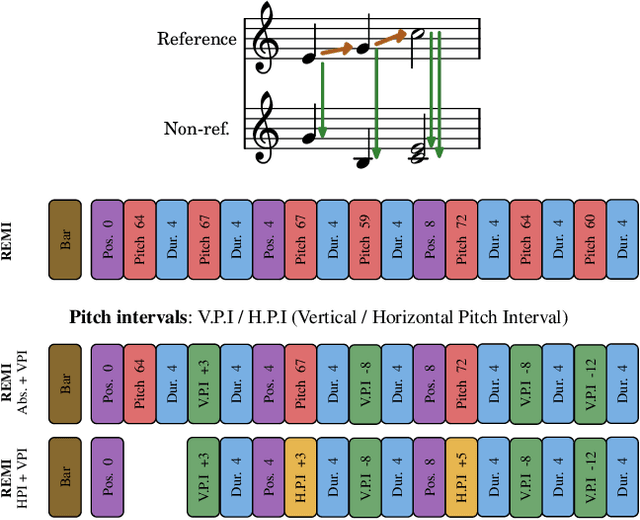
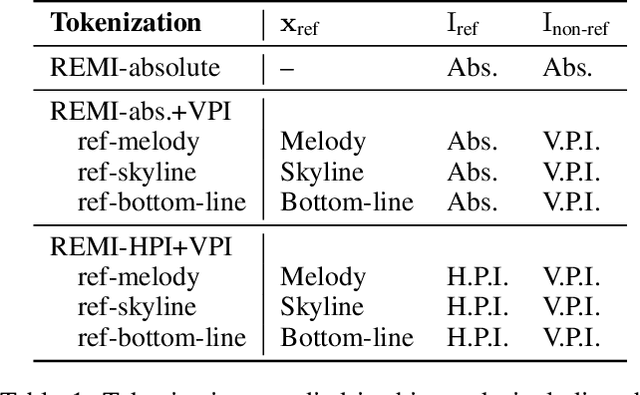
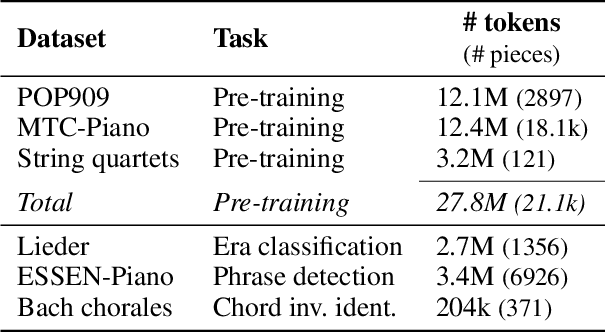
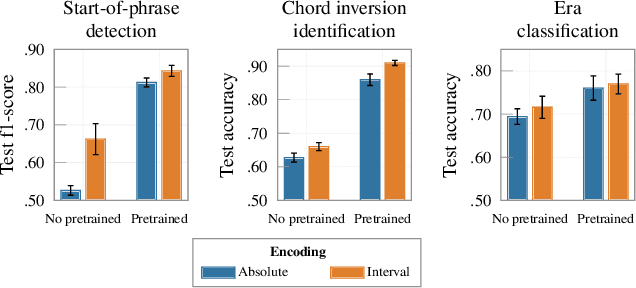
Symbolic music analysis tasks are often performed by models originally developed for Natural Language Processing, such as Transformers. Such models require the input data to be represented as sequences, which is achieved through a process of tokenization. Tokenization strategies for symbolic music often rely on absolute MIDI values to represent pitch information. However, music research largely promotes the benefit of higher-level representations such as melodic contour and harmonic relations for which pitch intervals turn out to be more expressive than absolute pitches. In this work, we introduce a general framework for building interval-based tokenizations. By evaluating these tokenizations on three music analysis tasks, we show that such interval-based tokenizations improve model performances and facilitate their explainability.
Recipient Profiling: Predicting Characteristics from Messages
Dec 17, 2024



It has been shown in the field of Author Profiling that texts may inadvertently reveal sensitive information about their authors, such as gender or age. This raises important privacy concerns that have been extensively addressed in the literature, in particular with the development of methods to hide such information. We argue that, when these texts are in fact messages exchanged between individuals, this is not the end of the story. Indeed, in this case, a second party, the intended recipient, is also involved and should be considered. In this work, we investigate the potential privacy leaks affecting them, that is we propose and address the problem of Recipient Profiling. We provide empirical evidence that such a task is feasible on several publicly accessible datasets (https://huggingface.co/datasets/sileod/recipient_profiling). Furthermore, we show that the learned models can be transferred to other datasets, albeit with a loss in accuracy.
Analyzing Byte-Pair Encoding on Monophonic and Polyphonic Symbolic Music: A Focus on Musical Phrase Segmentation
Oct 02, 2024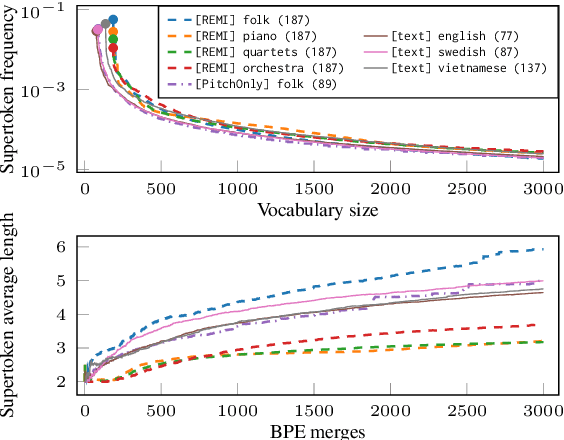

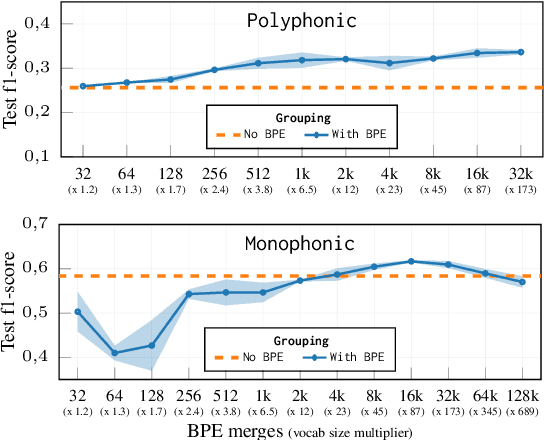
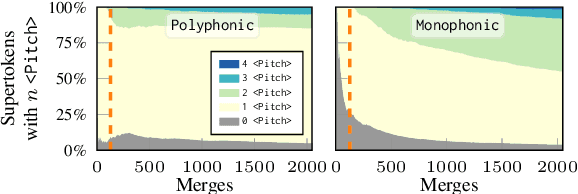
Byte-Pair Encoding (BPE) is an algorithm commonly used in Natural Language Processing to build a vocabulary of subwords, which has been recently applied to symbolic music. Given that symbolic music can differ significantly from text, particularly with polyphony, we investigate how BPE behaves with different types of musical content. This study provides a qualitative analysis of BPE's behavior across various instrumentations and evaluates its impact on a musical phrase segmentation task for both monophonic and polyphonic music. Our findings show that the BPE training process is highly dependent on the instrumentation and that BPE "supertokens" succeed in capturing abstract musical content. In a musical phrase segmentation task, BPE notably improves performance in a polyphonic setting, but enhances performance in monophonic tunes only within a specific range of BPE merges.
Synthetic Data Generation for Intersectional Fairness by Leveraging Hierarchical Group Structure
May 23, 2024In this paper, we introduce a data augmentation approach specifically tailored to enhance intersectional fairness in classification tasks. Our method capitalizes on the hierarchical structure inherent to intersectionality, by viewing groups as intersections of their parent categories. This perspective allows us to augment data for smaller groups by learning a transformation function that combines data from these parent groups. Our empirical analysis, conducted on four diverse datasets including both text and images, reveals that classifiers trained with this data augmentation approach achieve superior intersectional fairness and are more robust to ``leveling down'' when compared to methods optimizing traditional group fairness metrics.
Natural Language Processing Methods for Symbolic Music Generation and Information Retrieval: a Survey
Feb 27, 2024Several adaptations of Transformers models have been developed in various domains since its breakthrough in Natural Language Processing (NLP). This trend has spread into the field of Music Information Retrieval (MIR), including studies processing music data. However, the practice of leveraging NLP tools for symbolic music data is not novel in MIR. Music has been frequently compared to language, as they share several similarities, including sequential representations of text and music. These analogies are also reflected through similar tasks in MIR and NLP. This survey reviews NLP methods applied to symbolic music generation and information retrieval studies following two axes. We first propose an overview of representations of symbolic music adapted from natural language sequential representations. Such representations are designed by considering the specificities of symbolic music. These representations are then processed by models. Such models, possibly originally developed for text and adapted for symbolic music, are trained on various tasks. We describe these models, in particular deep learning models, through different prisms, highlighting music-specialized mechanisms. We finally present a discussion surrounding the effective use of NLP tools for symbolic music data. This includes technical issues regarding NLP methods and fundamental differences between text and music, which may open several doors for further research into more effectively adapting NLP tools to symbolic MIR.
A Tale of Two Laws of Semantic Change: Predicting Synonym Changes with Distributional Semantic Models
May 30, 2023



Lexical Semantic Change is the study of how the meaning of words evolves through time. Another related question is whether and how lexical relations over pairs of words, such as synonymy, change over time. There are currently two competing, apparently opposite hypotheses in the historical linguistic literature regarding how synonymous words evolve: the Law of Differentiation (LD) argues that synonyms tend to take on different meanings over time, whereas the Law of Parallel Change (LPC) claims that synonyms tend to undergo the same semantic change and therefore remain synonyms. So far, there has been little research using distributional models to assess to what extent these laws apply on historical corpora. In this work, we take a first step toward detecting whether LD or LPC operates for given word pairs. After recasting the problem into a more tractable task, we combine two linguistic resources to propose the first complete evaluation framework on this problem and provide empirical evidence in favor of a dominance of LD. We then propose various computational approaches to the problem using Distributional Semantic Models and grounded in recent literature on Lexical Semantic Change detection. Our best approaches achieve a balanced accuracy above 0.6 on our dataset. We discuss challenges still faced by these approaches, such as polysemy or the potential confusion between synonymy and hypernymy.
How to Capture Intersectional Fairness
May 21, 2023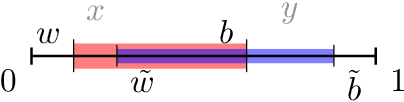
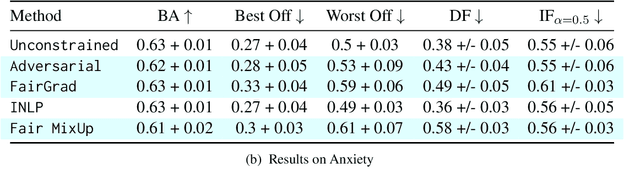
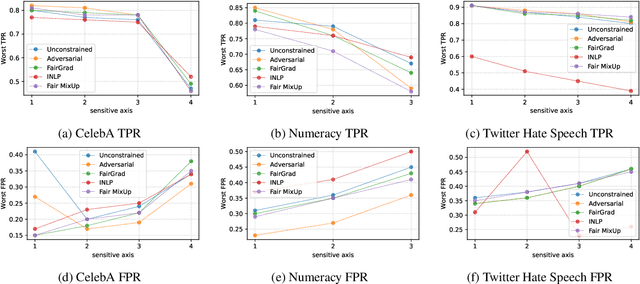
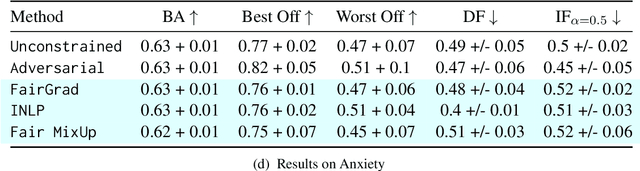
In this work, we tackle the problem of intersectional group fairness in the classification setting, where the objective is to learn discrimination-free models in the presence of several intersecting sensitive groups. First, we illustrate various shortcomings of existing fairness measures commonly used to capture intersectional fairness. Then, we propose a new framework called the $\alpha$ Intersectional Fairness framework, which combines the absolute and the relative performances between sensitive groups. Finally, we provide various analyses of our proposed framework, including the min-max and efficiency analysis. Our experiments using the proposed framework show that several in-processing fairness approaches show no improvement over a simple unconstrained approach. Moreover, we show that these approaches minimize existing fairness measures by degrading the performance of the best of the group instead of improving the worst.
Fair NLP Models with Differentially Private Text Encoders
May 12, 2022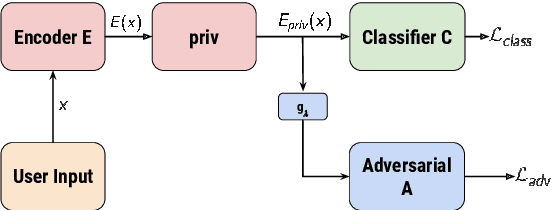
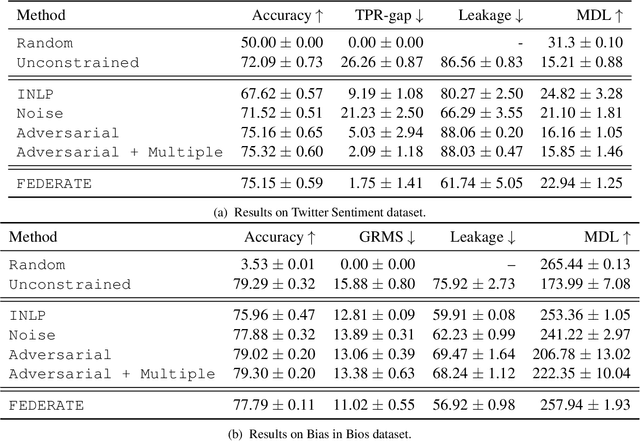
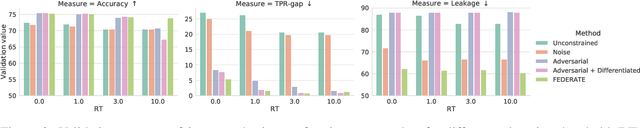
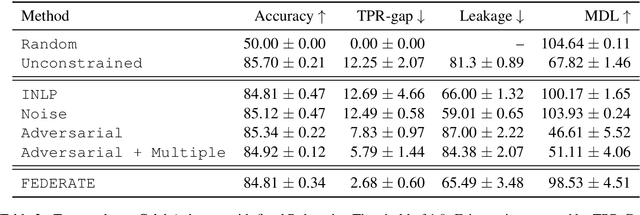
Encoded text representations often capture sensitive attributes about individuals (e.g., race or gender), which raise privacy concerns and can make downstream models unfair to certain groups. In this work, we propose FEDERATE, an approach that combines ideas from differential privacy and adversarial training to learn private text representations which also induces fairer models. We empirically evaluate the trade-off between the privacy of the representations and the fairness and accuracy of the downstream model on four NLP datasets. Our results show that FEDERATE consistently improves upon previous methods, and thus suggest that privacy and fairness can positively reinforce each other.
Metric learning approach for graph-based label propagation
Feb 18, 2016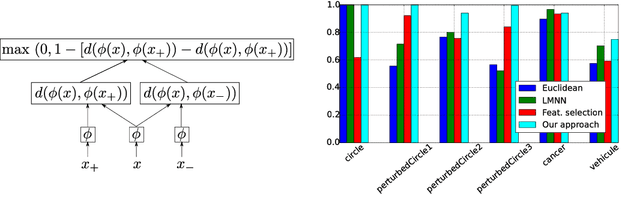
The efficiency of graph-based semi-supervised algorithms depends on the graph of instances on which they are applied. The instances are often in a vectorial form before a graph linking them is built. The construction of the graph relies on a metric over the vectorial space that help define the weight of the connection between entities. The classic choice for this metric is usually a distance measure or a similarity measure based on the euclidean norm. We claim that in some cases the euclidean norm on the initial vectorial space might not be the more appropriate to solve the task efficiently. We propose an algorithm that aims at learning the most appropriate vectorial representation for building a graph on which the task at hand is solved efficiently.
Spectral Estimation of Conditional Random Graph Models for Large-Scale Network Data
Oct 16, 2012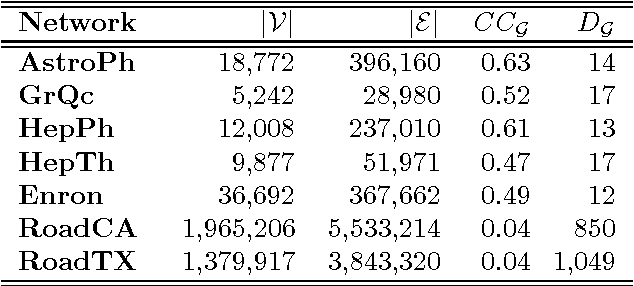
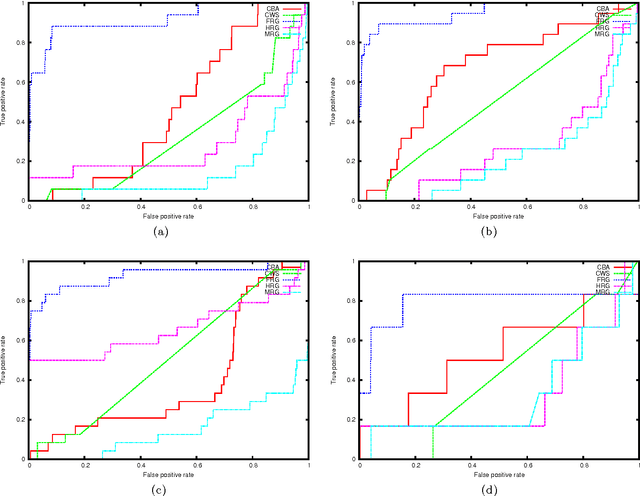
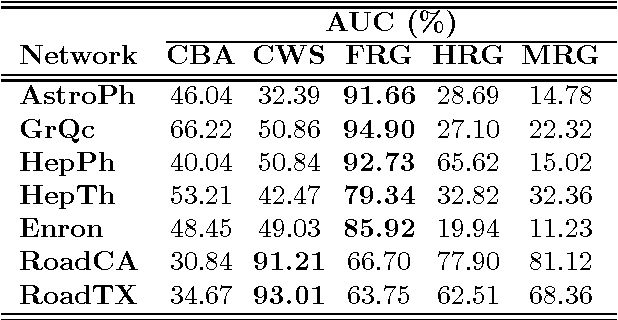
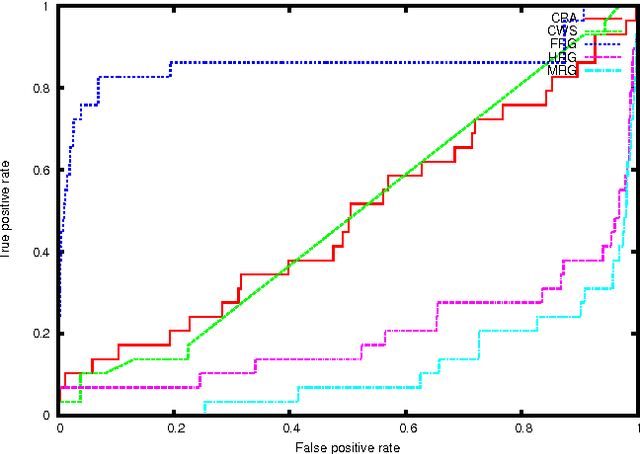
Generative models for graphs have been typically committed to strong prior assumptions concerning the form of the modeled distributions. Moreover, the vast majority of currently available models are either only suitable for characterizing some particular network properties (such as degree distribution or clustering coefficient), or they are aimed at estimating joint probability distributions, which is often intractable in large-scale networks. In this paper, we first propose a novel network statistic, based on the Laplacian spectrum of graphs, which allows to dispense with any parametric assumption concerning the modeled network properties. Second, we use the defined statistic to develop the Fiedler random graph model, switching the focus from the estimation of joint probability distributions to a more tractable conditional estimation setting. After analyzing the dependence structure characterizing Fiedler random graphs, we evaluate them experimentally in edge prediction over several real-world networks, showing that they allow to reach a much higher prediction accuracy than various alternative statistical models.