 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisparate Impact in Synthetic Data Generation
Jun 11, 2026We revisit the fairness notion of disparate impact for synthetic data generation (SDG), that assesses whether the utility of generated records is the same across sensitive groups. Our approach departs from existing work on fair SDG, that address the problem of correcting for undue biases in the observed distribution, hence redefining SDG as learning a distribution that is not that of the real data. By contrast, non-disparate impact is notably achieved when the synthetic and real distributions are the same. We expose reasons why SDG may fail to reach that solution and discuss why approximation and estimation errors occur and can be disparate across groups. We notably look into the expressive power of SDG methods relative to distribution complexity, sampling errors due to group proportions, and estimation errors induced by differential privacy mechanisms. We illustrate cases of disparate impact on both artificial and real-world data, focusing on SDG methods that rely on probabilistic graphical models. We also introduce a strategy of learning group-wise SDG models and illustrate how it can improve both the overall utility and its parity in many settings.
Distilling Human-Aligned Privacy Sensitivity Assessment from Large Language Models
Mar 31, 2026Accurate privacy evaluation of textual data remains a critical challenge in privacy-preserving natural language processing. Recent work has shown that large language models (LLMs) can serve as reliable privacy evaluators, achieving strong agreement with human judgments; however, their computational cost and impracticality for processing sensitive data at scale limit real-world deployment. We address this gap by distilling the privacy assessment capabilities of Mistral Large 3 (675B) into lightweight encoder models with as few as 150M parameters. Leveraging a large-scale dataset of privacy-annotated texts spanning 10 diverse domains, we train efficient classifiers that preserve strong agreement with human annotations while dramatically reducing computational requirements. We validate our approach on human-annotated test data and demonstrate its practical utility as an evaluation metric for de-identification systems.
Adaptive Text Anonymization: Learning Privacy-Utility Trade-offs via Prompt Optimization
Feb 24, 2026Anonymizing textual documents is a highly context-sensitive problem: the appropriate balance between privacy protection and utility preservation varies with the data domain, privacy objectives, and downstream application. However, existing anonymization methods rely on static, manually designed strategies that lack the flexibility to adjust to diverse requirements and often fail to generalize across domains. We introduce adaptive text anonymization, a new task formulation in which anonymization strategies are automatically adapted to specific privacy-utility requirements. We propose a framework for task-specific prompt optimization that automatically constructs anonymization instructions for language models, enabling adaptation to different privacy goals, domains, and downstream usage patterns. To evaluate our approach, we present a benchmark spanning five datasets with diverse domains, privacy constraints, and utility objectives. Across all evaluated settings, our framework consistently achieves a better privacy-utility trade-off than existing baselines, while remaining computationally efficient and effective on open-source language models, with performance comparable to larger closed-source models. Additionally, we show that our method can discover novel anonymization strategies that explore different points along the privacy-utility trade-off frontier.
Learning with Locally Private Examples by Inverse Weierstrass Private Stochastic Gradient Descent
Feb 18, 2026Releasing data once and for all under noninteractive Local Differential Privacy (LDP) enables complete data reusability, but the resulting noise may create bias in subsequent analyses. In this work, we leverage the Weierstrass transform to characterize this bias in binary classification. We prove that inverting this transform leads to a bias-correction method to compute unbiased estimates of nonlinear functions on examples released under LDP. We then build a novel stochastic gradient descent algorithm called Inverse Weierstrass Private SGD (IWP-SGD). It converges to the true population risk minimizer at a rate of $\mathcal{O}(1/n)$, with $n$ the number of examples. We empirically validate IWP-SGD on binary classification tasks using synthetic and real-world datasets.
Privacy Amplification Persists under Unlimited Synthetic Data Release
Feb 03, 2026We study privacy amplification by synthetic data release, a phenomenon in which differential privacy guarantees are improved by releasing only synthetic data rather than the private generative model itself. Recent work by Pierquin et al. (2025) established the first formal amplification guarantees for a linear generator, but they apply only in asymptotic regimes where the model dimension far exceeds the number of released synthetic records, limiting their practical relevance. In this work, we show a surprising result: under a bounded-parameter assumption, privacy amplification persists even when releasing an unbounded number of synthetic records, thereby improving upon the bounds of Pierquin et al. (2025). Our analysis provides structural insights that may guide the development of tighter privacy guarantees for more complex release mechanisms.
Federated Learning for MRI-based BrainAGE: a multicenter study on post-stroke functional outcome prediction
Jun 18, 2025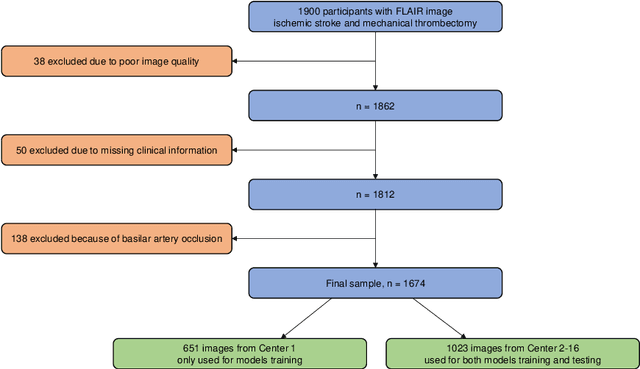
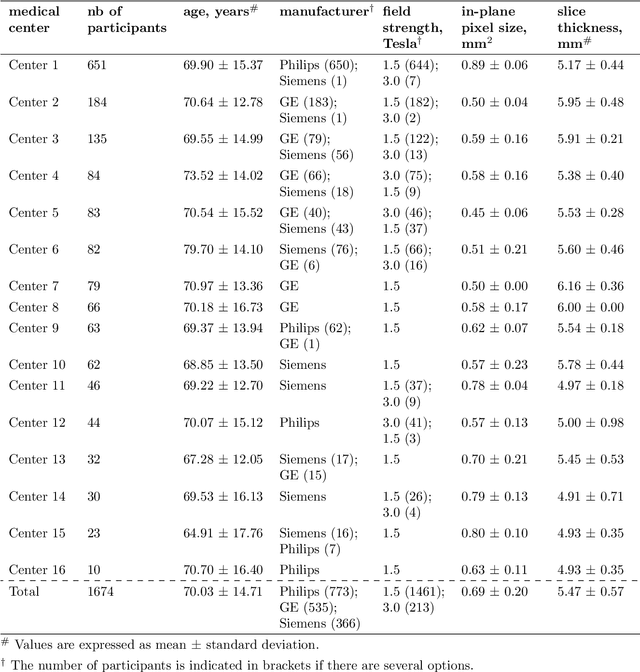
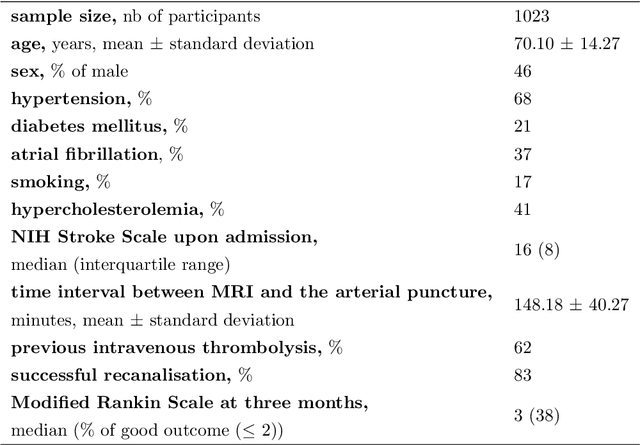
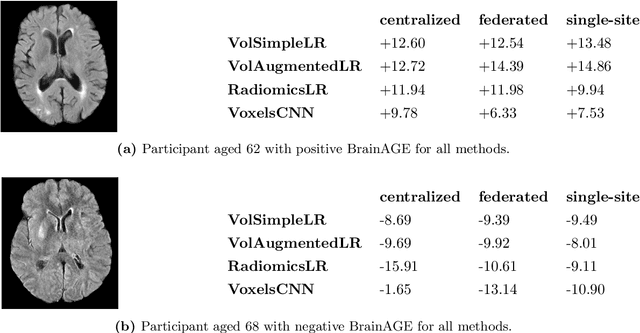
$\textbf{Objective:}$ Brain-predicted age difference (BrainAGE) is a neuroimaging biomarker reflecting brain health. However, training robust BrainAGE models requires large datasets, often restricted by privacy concerns. This study evaluates the performance of federated learning (FL) for BrainAGE estimation in ischemic stroke patients treated with mechanical thrombectomy, and investigates its association with clinical phenotypes and functional outcomes. $\textbf{Methods:}$ We used FLAIR brain images from 1674 stroke patients across 16 hospital centers. We implemented standard machine learning and deep learning models for BrainAGE estimates under three data management strategies: centralized learning (pooled data), FL (local training at each site), and single-site learning. We reported prediction errors and examined associations between BrainAGE and vascular risk factors (e.g., diabetes mellitus, hypertension, smoking), as well as functional outcomes at three months post-stroke. Logistic regression evaluated BrainAGE's predictive value for these outcomes, adjusting for age, sex, vascular risk factors, stroke severity, time between MRI and arterial puncture, prior intravenous thrombolysis, and recanalisation outcome. $\textbf{Results:}$ While centralized learning yielded the most accurate predictions, FL consistently outperformed single-site models. BrainAGE was significantly higher in patients with diabetes mellitus across all models. Comparisons between patients with good and poor functional outcomes, and multivariate predictions of these outcomes showed the significance of the association between BrainAGE and post-stroke recovery. $\textbf{Conclusion:}$ FL enables accurate age predictions without data centralization. The strong association between BrainAGE, vascular risk factors, and post-stroke recovery highlights its potential for prognostic modeling in stroke care.
Tau-Eval: A Unified Evaluation Framework for Useful and Private Text Anonymization
Jun 06, 2025Text anonymization is the process of removing or obfuscating information from textual data to protect the privacy of individuals. This process inherently involves a complex trade-off between privacy protection and information preservation, where stringent anonymization methods can significantly impact the text's utility for downstream applications. Evaluating the effectiveness of text anonymization proves challenging from both privacy and utility perspectives, as there is no universal benchmark that can comprehensively assess anonymization techniques across diverse, and sometimes contradictory contexts. We present Tau-Eval, an open-source framework for benchmarking text anonymization methods through the lens of privacy and utility task sensitivity. A Python library, code, documentation and tutorials are publicly available.
Privacy Amplification Through Synthetic Data: Insights from Linear Regression
Jun 05, 2025


Synthetic data inherits the differential privacy guarantees of the model used to generate it. Additionally, synthetic data may benefit from privacy amplification when the generative model is kept hidden. While empirical studies suggest this phenomenon, a rigorous theoretical understanding is still lacking. In this paper, we investigate this question through the well-understood framework of linear regression. First, we establish negative results showing that if an adversary controls the seed of the generative model, a single synthetic data point can leak as much information as releasing the model itself. Conversely, we show that when synthetic data is generated from random inputs, releasing a limited number of synthetic data points amplifies privacy beyond the model's inherent guarantees. We believe our findings in linear regression can serve as a foundation for deriving more general bounds in the future.
TAMIS: Tailored Membership Inference Attacks on Synthetic Data
Apr 01, 2025Membership Inference Attacks (MIA) enable to empirically assess the privacy of a machine learning algorithm. In this paper, we propose TAMIS, a novel MIA against differentially-private synthetic data generation methods that rely on graphical models. This attack builds upon MAMA-MIA, a recently-published state-of-the-art method. It lowers its computational cost and requires less attacker knowledge. Our attack is the product of a two-fold improvement. First, we recover the graphical model having generated a synthetic dataset by using solely that dataset, rather than shadow-modeling over an auxiliary one. This proves less costly and more performant. Second, we introduce a more mathematically-grounded attack score, that provides a natural threshold for binary predictions. In our experiments, TAMIS achieves better or similar performance as MAMA-MIA on replicas of the SNAKE challenge.
Analysis of Speech Temporal Dynamics in the Context of Speaker Verification and Voice Anonymization
Dec 22, 2024



In this paper, we investigate the impact of speech temporal dynamics in application to automatic speaker verification and speaker voice anonymization tasks. We propose several metrics to perform automatic speaker verification based only on phoneme durations. Experimental results demonstrate that phoneme durations leak some speaker information and can reveal speaker identity from both original and anonymized speech. Thus, this work emphasizes the importance of taking into account the speaker's speech rate and, more importantly, the speaker's phonetic duration characteristics, as well as the need to modify them in order to develop anonymization systems with strong privacy protection capacity.