 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttribute Inference Attacks for Federated Regression Tasks
Nov 19, 2024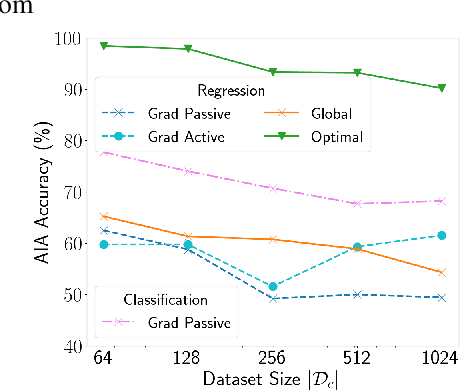
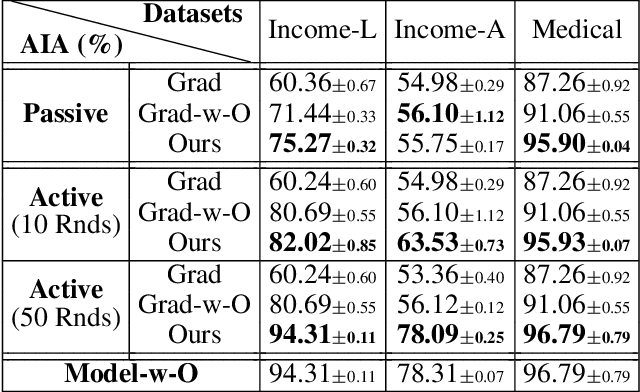
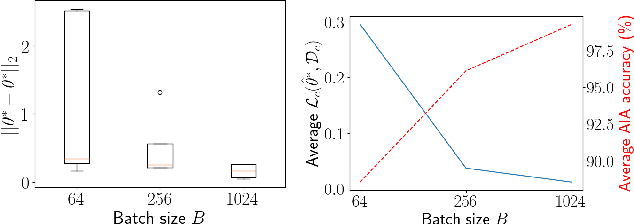
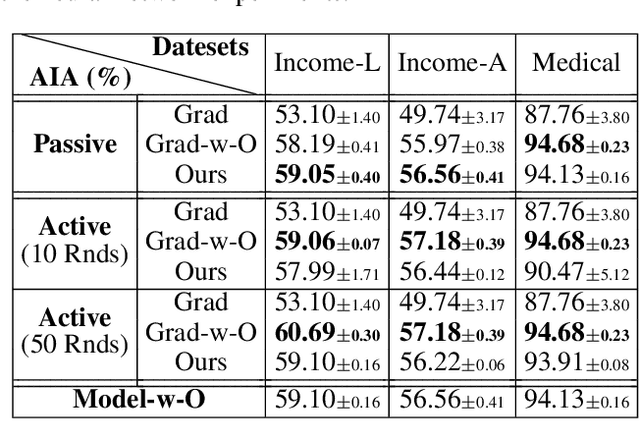
Federated Learning (FL) enables multiple clients, such as mobile phones and IoT devices, to collaboratively train a global machine learning model while keeping their data localized. However, recent studies have revealed that the training phase of FL is vulnerable to reconstruction attacks, such as attribute inference attacks (AIA), where adversaries exploit exchanged messages and auxiliary public information to uncover sensitive attributes of targeted clients. While these attacks have been extensively studied in the context of classification tasks, their impact on regression tasks remains largely unexplored. In this paper, we address this gap by proposing novel model-based AIAs specifically designed for regression tasks in FL environments. Our approach considers scenarios where adversaries can either eavesdrop on exchanged messages or directly interfere with the training process. We benchmark our proposed attacks against state-of-the-art methods using real-world datasets. The results demonstrate a significant increase in reconstruction accuracy, particularly in heterogeneous client datasets, a common scenario in FL. The efficacy of our model-based AIAs makes them better candidates for empirically quantifying privacy leakage for federated regression tasks.
A Cautionary Tale: On the Role of Reference Data in Empirical Privacy Defenses
Oct 18, 2023



Within the realm of privacy-preserving machine learning, empirical privacy defenses have been proposed as a solution to achieve satisfactory levels of training data privacy without a significant drop in model utility. Most existing defenses against membership inference attacks assume access to reference data, defined as an additional dataset coming from the same (or a similar) underlying distribution as training data. Despite the common use of reference data, previous works are notably reticent about defining and evaluating reference data privacy. As gains in model utility and/or training data privacy may come at the expense of reference data privacy, it is essential that all three aspects are duly considered. In this paper, we first examine the availability of reference data and its privacy treatment in previous works and demonstrate its necessity for fairly comparing defenses. Second, we propose a baseline defense that enables the utility-privacy tradeoff with respect to both training and reference data to be easily understood. Our method is formulated as an empirical risk minimization with a constraint on the generalization error, which, in practice, can be evaluated as a weighted empirical risk minimization (WERM) over the training and reference datasets. Although we conceived of WERM as a simple baseline, our experiments show that, surprisingly, it outperforms the most well-studied and current state-of-the-art empirical privacy defenses using reference data for nearly all relative privacy levels of reference and training data. Our investigation also reveals that these existing methods are unable to effectively trade off reference data privacy for model utility and/or training data privacy. Overall, our work highlights the need for a proper evaluation of the triad model utility / training data privacy / reference data privacy when comparing privacy defenses.
Federated Learning under Heterogeneous and Correlated Client Availability
Jan 11, 2023



The enormous amount of data produced by mobile and IoT devices has motivated the development of federated learning (FL), a framework allowing such devices (or clients) to collaboratively train machine learning models without sharing their local data. FL algorithms (like FedAvg) iteratively aggregate model updates computed by clients on their own datasets. Clients may exhibit different levels of participation, often correlated over time and with other clients. This paper presents the first convergence analysis for a FedAvg-like FL algorithm under heterogeneous and correlated client availability. Our analysis highlights how correlation adversely affects the algorithm's convergence rate and how the aggregation strategy can alleviate this effect at the cost of steering training toward a biased model. Guided by the theoretical analysis, we propose CA-Fed, a new FL algorithm that tries to balance the conflicting goals of maximizing convergence speed and minimizing model bias. To this purpose, CA-Fed dynamically adapts the weight given to each client and may ignore clients with low availability and large correlation. Our experimental results show that CA-Fed achieves higher time-average accuracy and a lower standard deviation than state-of-the-art AdaFed and F3AST, both on synthetic and real datasets.
Federated Learning for Data Streams
Jan 04, 2023



Federated learning (FL) is an effective solution to train machine learning models on the increasing amount of data generated by IoT devices and smartphones while keeping such data localized. Most previous work on federated learning assumes that clients operate on static datasets collected before training starts. This approach may be inefficient because 1) it ignores new samples clients collect during training, and 2) it may require a potentially long preparatory phase for clients to collect enough data. Moreover, learning on static datasets may be simply impossible in scenarios with small aggregate storage across devices. It is, therefore, necessary to design federated algorithms able to learn from data streams. In this work, we formulate and study the problem of \emph{federated learning for data streams}. We propose a general FL algorithm to learn from data streams through an opportune weighted empirical risk minimization. Our theoretical analysis provides insights to configure such an algorithm, and we evaluate its performance on a wide range of machine learning tasks.
FLamby: Datasets and Benchmarks for Cross-Silo Federated Learning in Realistic Healthcare Settings
Oct 10, 2022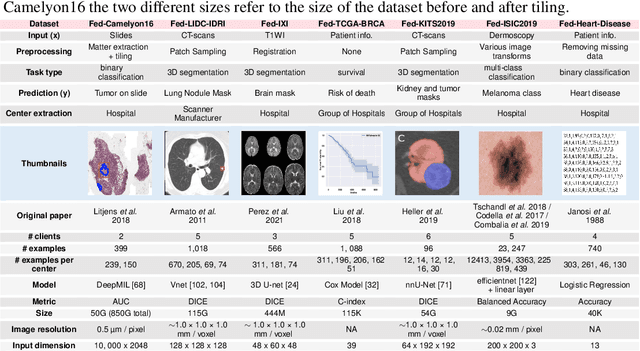
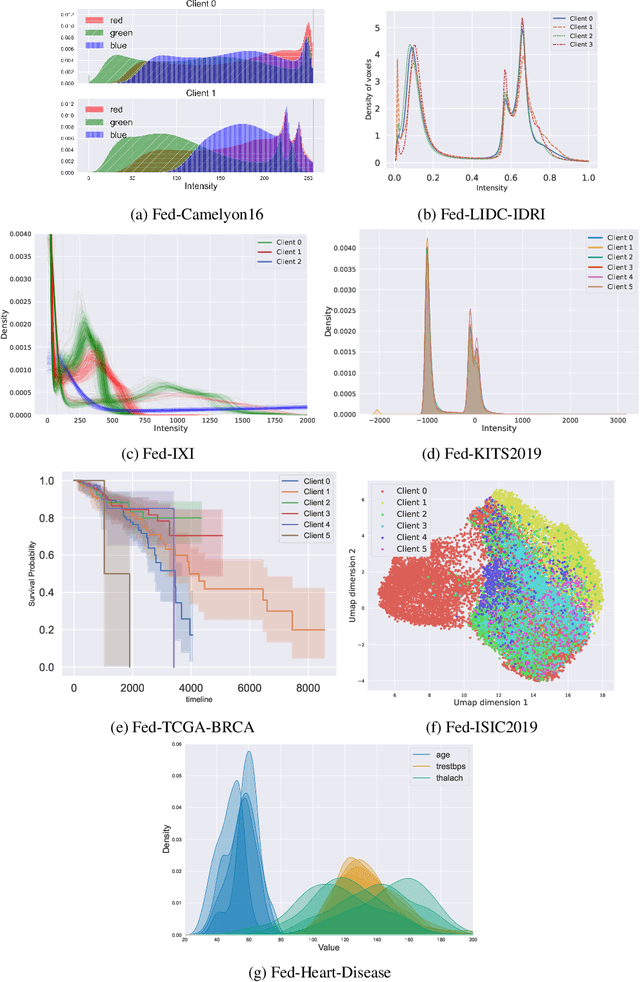
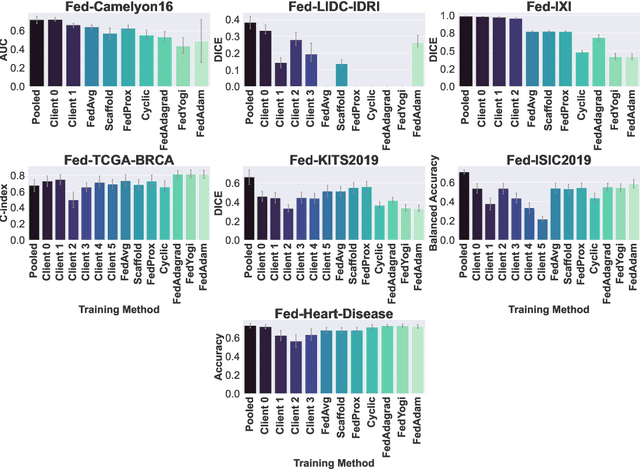

Federated Learning (FL) is a novel approach enabling several clients holding sensitive data to collaboratively train machine learning models, without centralizing data. The cross-silo FL setting corresponds to the case of few ($2$--$50$) reliable clients, each holding medium to large datasets, and is typically found in applications such as healthcare, finance, or industry. While previous works have proposed representative datasets for cross-device FL, few realistic healthcare cross-silo FL datasets exist, thereby slowing algorithmic research in this critical application. In this work, we propose a novel cross-silo dataset suite focused on healthcare, FLamby (Federated Learning AMple Benchmark of Your cross-silo strategies), to bridge the gap between theory and practice of cross-silo FL. FLamby encompasses 7 healthcare datasets with natural splits, covering multiple tasks, modalities, and data volumes, each accompanied with baseline training code. As an illustration, we additionally benchmark standard FL algorithms on all datasets. Our flexible and modular suite allows researchers to easily download datasets, reproduce results and re-use the different components for their research. FLamby is available at~\url{www.github.com/owkin/flamby}.
Personalized Federated Learning through Local Memorization
Nov 17, 2021

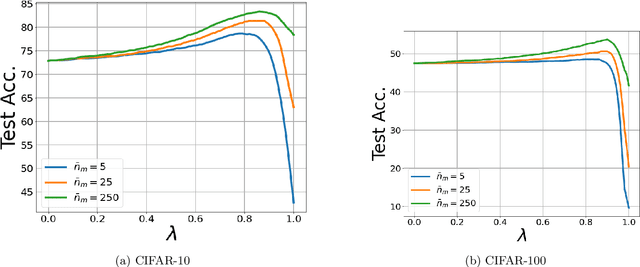
Federated learning allows clients to collaboratively learn statistical models while keeping their data local. Federated learning was originally used to train a unique global model to be served to all clients, but this approach might be sub-optimal when clients' local data distributions are heterogeneous. In order to tackle this limitation, recent personalized federated learning methods train a separate model for each client while still leveraging the knowledge available at other clients. In this work, we exploit the ability of deep neural networks to extract high quality vectorial representations (embeddings) from non-tabular data, e.g., images and text, to propose a personalization mechanism based on local memorization. Personalization is obtained interpolating a pre-trained global model with a $k$-nearest neighbors (kNN) model based on the shared representation provided by the global model. We provide generalization bounds for the proposed approach and we show on a suite of federated datasets that this approach achieves significantly higher accuracy and fairness than state-of-the-art methods.
Federated Multi-Task Learning under a Mixture of Distributions
Aug 23, 2021

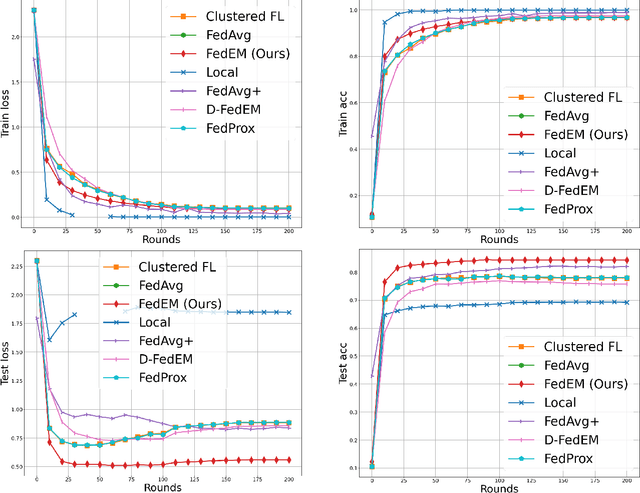

The increasing size of data generated by smartphones and IoT devices motivated the development of Federated Learning (FL), a framework for on-device collaborative training of machine learning models. First efforts in FL focused on learning a single global model with good average performance across clients, but the global model may be arbitrarily bad for a given client, due to the inherent heterogeneity of local data distributions. Federated multi-task learning (MTL) approaches can learn personalized models by formulating an opportune penalized optimization problem. The penalization term can capture complex relations among personalized models, but eschews clear statistical assumptions about local data distributions. In this work, we propose to study federated MTL under the flexible assumption that each local data distribution is a mixture of unknown underlying distributions. This assumption encompasses most of the existing personalized FL approaches and leads to federated EM-like algorithms for both client-server and fully decentralized settings. Moreover, it provides a principled way to serve personalized models to clients not seen at training time. The algorithms' convergence is analyzed through a novel federated surrogate optimization framework, which can be of general interest. Experimental results on FL benchmarks show that in most cases our approach provides models with higher accuracy and fairness than state-of-the-art methods.
Throughput-Optimal Topology Design for Cross-Silo Federated Learning
Oct 23, 2020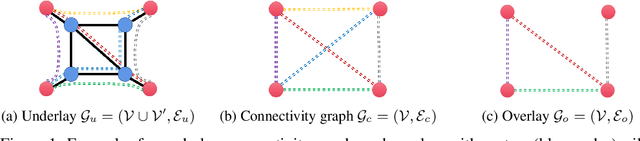


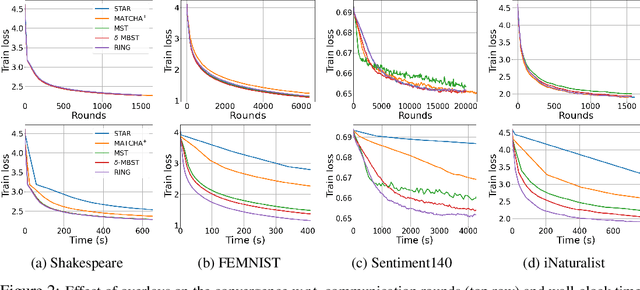
Federated learning usually employs a client-server architecture where an orchestrator iteratively aggregates model updates from remote clients and pushes them back a refined model. This approach may be inefficient in cross-silo settings, as close-by data silos with high-speed access links may exchange information faster than with the orchestrator, and the orchestrator may become a communication bottleneck. In this paper we define the problem of topology design for cross-silo federated learning using the theory of max-plus linear systems to compute the system throughput---number of communication rounds per time unit. We also propose practical algorithms that, under the knowledge of measurable network characteristics, find a topology with the largest throughput or with provable throughput guarantees. In realistic Internet networks with 10 Gbps access links for silos, our algorithms speed up training by a factor 9 and 1.5 in comparison to the master-slave architecture and to state-of-the-art MATCHA, respectively. Speedups are even larger with slower access links.