 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Role of Reversible Instance Normalization
Mar 12, 2026Data normalization is a crucial component of deep learning models, yet its role in time series forecasting remains insufficiently understood. In this paper, we identify three central challenges for normalization in time series forecasting: temporal input distribution shift, spatial input distribution shift, and conditional output distribution shift. In this context, we revisit the widely used Reversible Instance Normalization (RevIN), by showing through ablation studies that several of its components are redundant or even detrimental. Based on these observations, we draw new perspectives to improve RevIN's robustness and generalization.
Variance-Reduced $(\varepsilon,δ)-$Unlearning using Forget Set Gradients
Feb 16, 2026In machine unlearning, $(\varepsilon,δ)-$unlearning is a popular framework that provides formal guarantees on the effectiveness of the removal of a subset of training data, the forget set, from a trained model. For strongly convex objectives, existing first-order methods achieve $(\varepsilon,δ)-$unlearning, but they only use the forget set to calibrate injected noise, never as a direct optimization signal. In contrast, efficient empirical heuristics often exploit the forget samples (e.g., via gradient ascent) but come with no formal unlearning guarantees. We bridge this gap by presenting the Variance-Reduced Unlearning (VRU) algorithm. To the best of our knowledge, VRU is the first first-order algorithm that directly includes forget set gradients in its update rule, while provably satisfying ($(\varepsilon,δ)-$unlearning. We establish the convergence of VRU and show that incorporating the forget set yields strictly improved rates, i.e. a better dependence on the achieved error compared to existing first-order $(\varepsilon,δ)-$unlearning methods. Moreover, we prove that, in a low-error regime, VRU asymptotically outperforms any first-order method that ignores the forget set.Experiments corroborate our theory, showing consistent gains over both state-of-the-art certified unlearning methods and over empirical baselines that explicitly leverage the forget set.
A Unified Convergence Analysis for Semi-Decentralized Learning: Sampled-to-Sampled vs. Sampled-to-All Communication
Nov 17, 2025In semi-decentralized federated learning, devices primarily rely on device-to-device communication but occasionally interact with a central server. Periodically, a sampled subset of devices uploads their local models to the server, which computes an aggregate model. The server can then either (i) share this aggregate model only with the sampled clients (sampled-to-sampled, S2S) or (ii) broadcast it to all clients (sampled-to-all, S2A). Despite their practical significance, a rigorous theoretical and empirical comparison of these two strategies remains absent. We address this gap by analyzing S2S and S2A within a unified convergence framework that accounts for key system parameters: sampling rate, server aggregation frequency, and network connectivity. Our results, both analytical and experimental, reveal distinct regimes where one strategy outperforms the other, depending primarily on the degree of data heterogeneity across devices. These insights lead to concrete design guidelines for practical semi-decentralized FL deployments.
Green Federated Learning via Carbon-Aware Client and Time Slot Scheduling
Sep 10, 2025Training large-scale machine learning models incurs substantial carbon emissions. Federated Learning (FL), by distributing computation across geographically dispersed clients, offers a natural framework to leverage regional and temporal variations in Carbon Intensity (CI). This paper investigates how to reduce emissions in FL through carbon-aware client selection and training scheduling. We first quantify the emission savings of a carbon-aware scheduling policy that leverages slack time -- permitting a modest extension of the training duration so that clients can defer local training rounds to lower-carbon periods. We then examine the performance trade-offs of such scheduling which stem from statistical heterogeneity among clients, selection bias in participation, and temporal correlation in model updates. To leverage these trade-offs, we construct a carbon-aware scheduler that integrates slack time, $\alpha$-fair carbon allocation, and a global fine-tuning phase. Experiments on real-world CI data show that our scheduler outperforms slack-agnostic baselines, achieving higher model accuracy across a wide range of carbon budgets, with especially strong gains under tight carbon constraints.
Reconciling Communication Compression and Byzantine-Robustness in Distributed Learning
Aug 23, 2025Distributed learning (DL) enables scalable model training over decentralized data, but remains challenged by Byzantine faults and high communication costs. While both issues have been studied extensively in isolation, their interaction is less explored. Prior work shows that naively combining communication compression with Byzantine-robust aggregation degrades resilience to faulty nodes (or workers). The state-of-the-art algorithm, namely Byz-DASHA-PAGE [29], makes use of the momentum variance reduction scheme to mitigate the detrimental impact of compression noise on Byzantine-robustness. We propose a new algorithm, named RoSDHB, that integrates the classic Polyak's momentum with a new coordinated compression mechanism. We show that RoSDHB performs comparably to Byz-DASHA-PAGE under the standard (G, B)-gradient dissimilarity heterogeneity model, while it relies on fewer assumptions. In particular, we only assume Lipschitz smoothness of the average loss function of the honest workers, in contrast to [29]that additionally assumes a special smoothness of bounded global Hessian variance. Empirical results on benchmark image classification task show that RoSDHB achieves strong robustness with significant communication savings.
Cutting Through Privacy: A Hyperplane-Based Data Reconstruction Attack in Federated Learning
May 15, 2025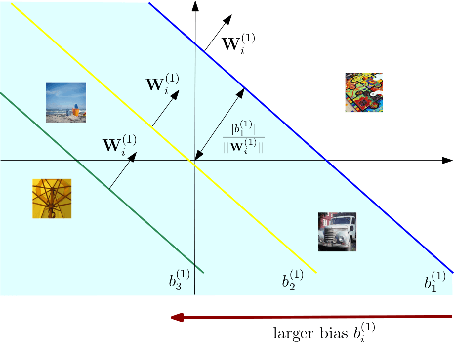
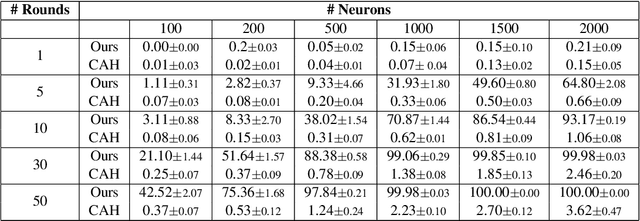
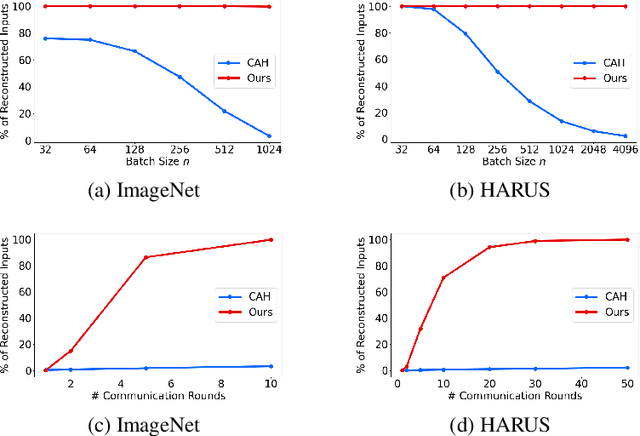
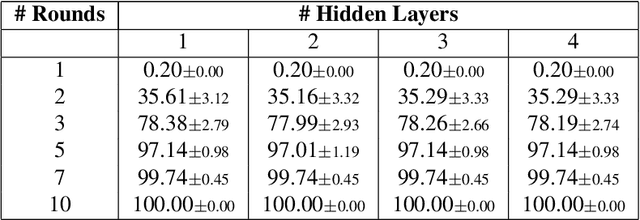
Federated Learning (FL) enables collaborative training of machine learning models across distributed clients without sharing raw data, ostensibly preserving data privacy. Nevertheless, recent studies have revealed critical vulnerabilities in FL, showing that a malicious central server can manipulate model updates to reconstruct clients' private training data. Existing data reconstruction attacks have important limitations: they often rely on assumptions about the clients' data distribution or their efficiency significantly degrades when batch sizes exceed just a few tens of samples. In this work, we introduce a novel data reconstruction attack that overcomes these limitations. Our method leverages a new geometric perspective on fully connected layers to craft malicious model parameters, enabling the perfect recovery of arbitrarily large data batches in classification tasks without any prior knowledge of clients' data. Through extensive experiments on both image and tabular datasets, we demonstrate that our attack outperforms existing methods and achieves perfect reconstruction of data batches two orders of magnitude larger than the state of the art.
Streaming Federated Learning with Markovian Data
Mar 24, 2025Federated learning (FL) is now recognized as a key framework for communication-efficient collaborative learning. Most theoretical and empirical studies, however, rely on the assumption that clients have access to pre-collected data sets, with limited investigation into scenarios where clients continuously collect data. In many real-world applications, particularly when data is generated by physical or biological processes, client data streams are often modeled by non-stationary Markov processes. Unlike standard i.i.d. sampling, the performance of FL with Markovian data streams remains poorly understood due to the statistical dependencies between client samples over time. In this paper, we investigate whether FL can still support collaborative learning with Markovian data streams. Specifically, we analyze the performance of Minibatch SGD, Local SGD, and a variant of Local SGD with momentum. We answer affirmatively under standard assumptions and smooth non-convex client objectives: the sample complexity is proportional to the inverse of the number of clients with a communication complexity comparable to the i.i.d. scenario. However, the sample complexity for Markovian data streams remains higher than for i.i.d. sampling.
FedBEns: One-Shot Federated Learning based on Bayesian Ensemble
Mar 19, 2025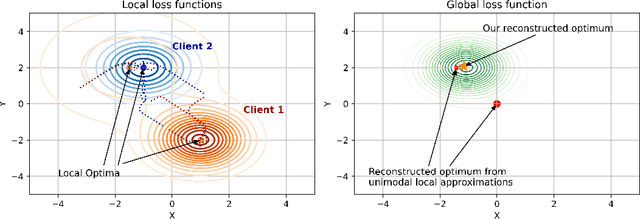
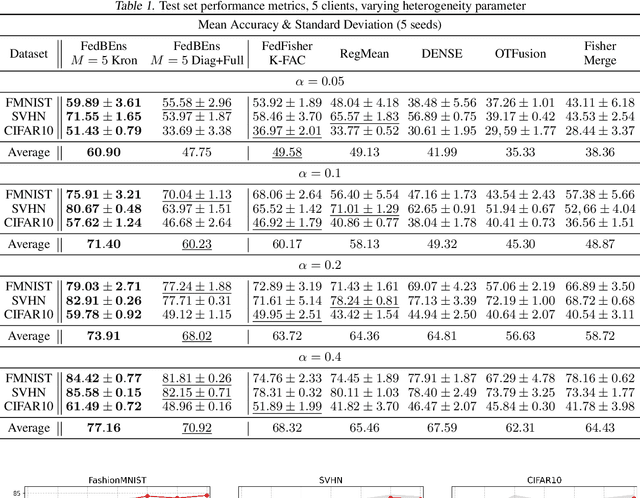
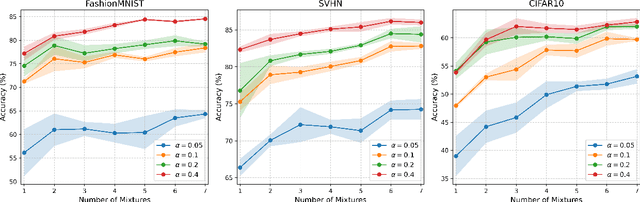
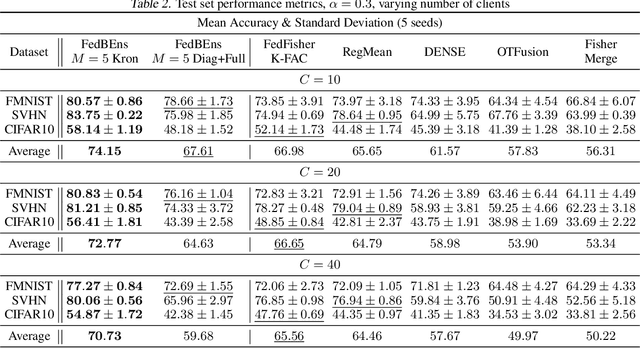
One-Shot Federated Learning (FL) is a recent paradigm that enables multiple clients to cooperatively learn a global model in a single round of communication with a central server. In this paper, we analyze the One-Shot FL problem through the lens of Bayesian inference and propose FedBEns, an algorithm that leverages the inherent multimodality of local loss functions to find better global models. Our algorithm leverages a mixture of Laplace approximations for the clients' local posteriors, which the server then aggregates to infer the global model. We conduct extensive experiments on various datasets, demonstrating that the proposed method outperforms competing baselines that typically rely on unimodal approximations of the local losses.
Efficient and Optimal No-Regret Caching under Partial Observation
Mar 04, 2025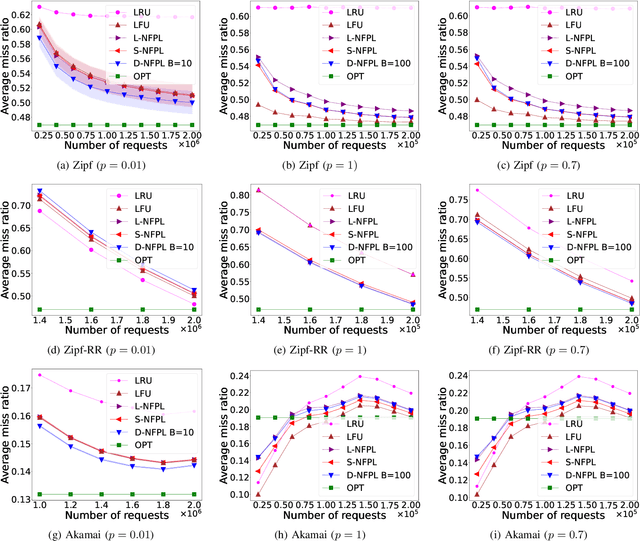
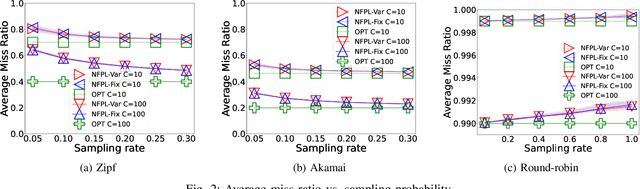


Online learning algorithms have been successfully used to design caching policies with sublinear regret in the total number of requests, with no statistical assumption about the request sequence. Most existing algorithms involve computationally expensive operations and require knowledge of all past requests. However, this may not be feasible in practical scenarios like caching at a cellular base station. Therefore, we study the caching problem in a more restrictive setting where only a fraction of past requests are observed, and we propose a randomized caching policy with sublinear regret based on the classic online learning algorithm Follow-the-Perturbed-Leader (FPL). Our caching policy is the first to attain the asymptotically optimal regret bound while ensuring asymptotically constant amortized time complexity in the partial observability setting of requests. The experimental evaluation compares the proposed solution against classic caching policies and validates the proposed approach under synthetic and real-world request traces.
When to Forget? Complexity Trade-offs in Machine Unlearning
Feb 24, 2025Machine Unlearning (MU) aims at removing the influence of specific data points from a trained model, striving to achieve this at a fraction of the cost of full model retraining. In this paper, we analyze the efficiency of unlearning methods and establish the first upper and lower bounds on minimax computation times for this problem, characterizing the performance of the most efficient algorithm against the most difficult objective function. Specifically, for strongly convex objective functions and under the assumption that the forget data is inaccessible to the unlearning method, we provide a phase diagram for the unlearning complexity ratio -- a novel metric that compares the computational cost of the best unlearning method to full model retraining. The phase diagram reveals three distinct regimes: one where unlearning at a reduced cost is infeasible, another where unlearning is trivial because adding noise suffices, and a third where unlearning achieves significant computational advantages over retraining. These findings highlight the critical role of factors such as data dimensionality, the number of samples to forget, and privacy constraints in determining the practical feasibility of unlearning.