 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the Energy Consumption of Machine Learning: Systematic Literature Review and Experiments
Aug 27, 2024Monitoring, understanding, and optimizing the energy consumption of Machine Learning (ML) are various reasons why it is necessary to evaluate the energy usage of ML. However, there exists no universal tool that can answer this question for all use cases, and there may even be disagreement on how to evaluate energy consumption for a specific use case. Tools and methods are based on different approaches, each with their own advantages and drawbacks, and they need to be mapped out and explained in order to select the most suitable one for a given situation. We address this challenge through two approaches. First, we conduct a systematic literature review of all tools and methods that permit to evaluate the energy consumption of ML (both at training and at inference), irrespective of whether they were originally designed for machine learning or general software. Second, we develop and use an experimental protocol to compare a selection of these tools and methods. The comparison is both qualitative and quantitative on a range of ML tasks of different nature (vision, language) and computational complexity. The systematic literature review serves as a comprehensive guide for understanding the array of tools and methods used in evaluating energy consumption of ML, for various use cases going from basic energy monitoring to consumption optimization. Two open-source repositories are provided for further exploration. The first one contains tools that can be used to replicate this work or extend the current review. The second repository houses the experimental protocol, allowing users to augment the protocol with new ML computing tasks and additional energy evaluation tools.
Fed-BioMed: Open, Transparent and Trusted Federated Learning for Real-world Healthcare Applications
Apr 24, 2023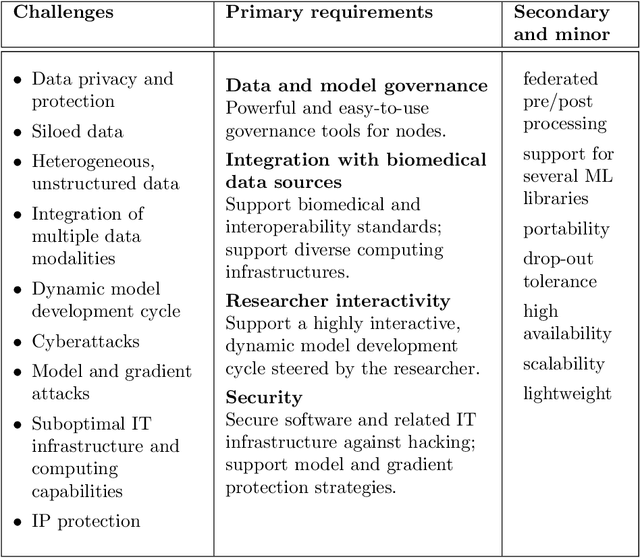
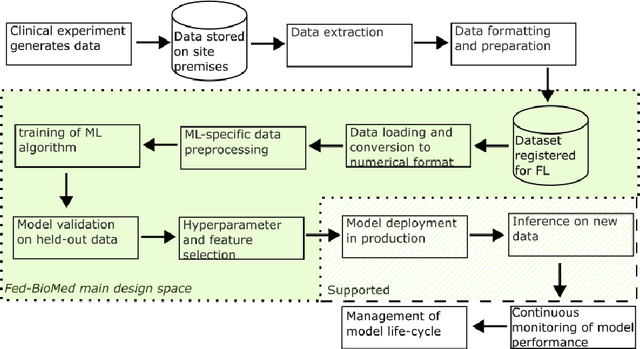
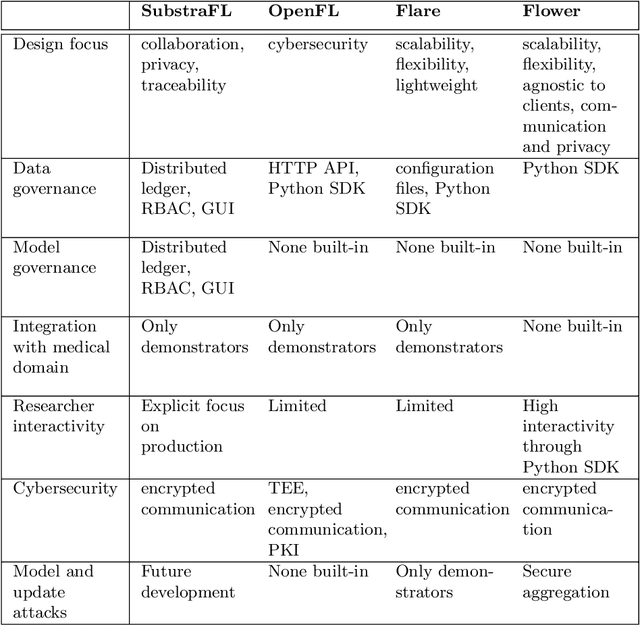
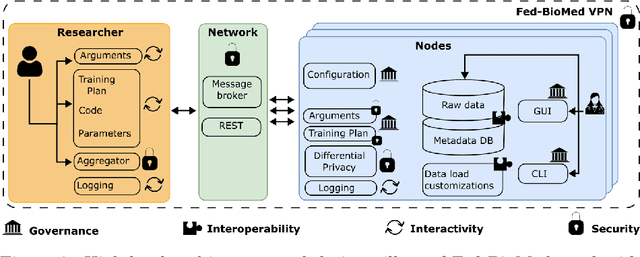
The real-world implementation of federated learning is complex and requires research and development actions at the crossroad between different domains ranging from data science, to software programming, networking, and security. While today several FL libraries are proposed to data scientists and users, most of these frameworks are not designed to find seamless application in medical use-cases, due to the specific challenges and requirements of working with medical data and hospital infrastructures. Moreover, governance, design principles, and security assumptions of these frameworks are generally not clearly illustrated, thus preventing the adoption in sensitive applications. Motivated by the current technological landscape of FL in healthcare, in this document we present Fed-BioMed: a research and development initiative aiming at translating federated learning (FL) into real-world medical research applications. We describe our design space, targeted users, domain constraints, and how these factors affect our current and future software architecture.
Federated Learning for Data Streams
Jan 04, 2023



Federated learning (FL) is an effective solution to train machine learning models on the increasing amount of data generated by IoT devices and smartphones while keeping such data localized. Most previous work on federated learning assumes that clients operate on static datasets collected before training starts. This approach may be inefficient because 1) it ignores new samples clients collect during training, and 2) it may require a potentially long preparatory phase for clients to collect enough data. Moreover, learning on static datasets may be simply impossible in scenarios with small aggregate storage across devices. It is, therefore, necessary to design federated algorithms able to learn from data streams. In this work, we formulate and study the problem of \emph{federated learning for data streams}. We propose a general FL algorithm to learn from data streams through an opportune weighted empirical risk minimization. Our theoretical analysis provides insights to configure such an algorithm, and we evaluate its performance on a wide range of machine learning tasks.
Sequential Informed Federated Unlearning: Efficient and Provable Client Unlearning in Federated Optimization
Nov 21, 2022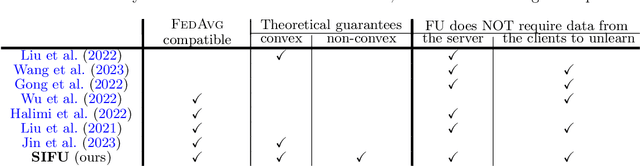
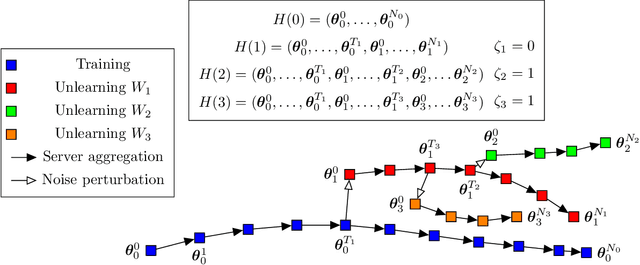
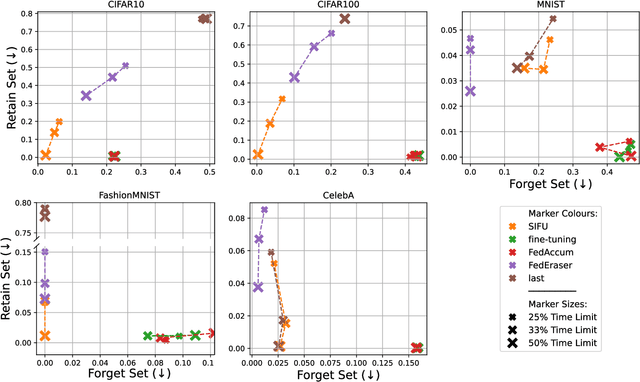
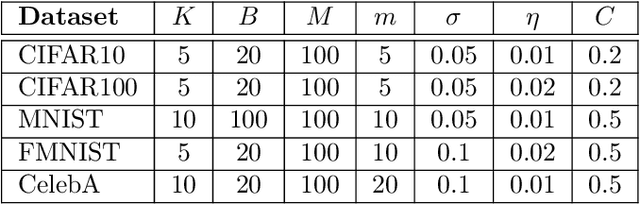
The aim of Machine Unlearning (MU) is to provide theoretical guarantees on the removal of the contribution of a given data point from a training procedure. Federated Unlearning (FU) consists in extending MU to unlearn a given client's contribution from a federated training routine. Current FU approaches are generally not scalable, and do not come with sound theoretical quantification of the effectiveness of unlearning. In this work we present Informed Federated Unlearning (IFU), a novel efficient and quantifiable FU approach. Upon unlearning request from a given client, IFU identifies the optimal FL iteration from which FL has to be reinitialized, with unlearning guarantees obtained through a randomized perturbation mechanism. The theory of IFU is also extended to account for sequential unlearning requests. Experimental results on different tasks and dataset show that IFU leads to more efficient unlearning procedures as compared to basic re-training and state-of-the-art FU approaches.
A General Theory for Federated Optimization with Asynchronous and Heterogeneous Clients Updates
Jun 21, 2022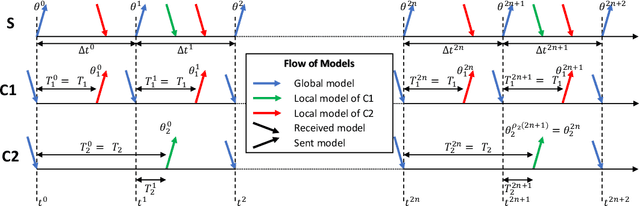


We propose a novel framework to study asynchronous federated learning optimization with delays in gradient updates. Our theoretical framework extends the standard FedAvg aggregation scheme by introducing stochastic aggregation weights to represent the variability of the clients update time, due for example to heterogeneous hardware capabilities. Our formalism applies to the general federated setting where clients have heterogeneous datasets and perform at least one step of stochastic gradient descent (SGD). We demonstrate convergence for such a scheme and provide sufficient conditions for the related minimum to be the optimum of the federated problem. We show that our general framework applies to existing optimization schemes including centralized learning, FedAvg, asynchronous FedAvg, and FedBuff. The theory here provided allows drawing meaningful guidelines for designing a federated learning experiment in heterogeneous conditions. In particular, we develop in this work FedFix, a novel extension of FedAvg enabling efficient asynchronous federated training while preserving the convergence stability of synchronous aggregation. We empirically demonstrate our theory on a series of experiments showing that asynchronous FedAvg leads to fast convergence at the expense of stability, and we finally demonstrate the improvements of FedFix over synchronous and asynchronous FedAvg.
Personalized Federated Learning through Local Memorization
Nov 17, 2021

Federated learning allows clients to collaboratively learn statistical models while keeping their data local. Federated learning was originally used to train a unique global model to be served to all clients, but this approach might be sub-optimal when clients' local data distributions are heterogeneous. In order to tackle this limitation, recent personalized federated learning methods train a separate model for each client while still leveraging the knowledge available at other clients. In this work, we exploit the ability of deep neural networks to extract high quality vectorial representations (embeddings) from non-tabular data, e.g., images and text, to propose a personalization mechanism based on local memorization. Personalization is obtained interpolating a pre-trained global model with a $k$-nearest neighbors (kNN) model based on the shared representation provided by the global model. We provide generalization bounds for the proposed approach and we show on a suite of federated datasets that this approach achieves significantly higher accuracy and fairness than state-of-the-art methods.
Federated Multi-Task Learning under a Mixture of Distributions
Aug 23, 2021

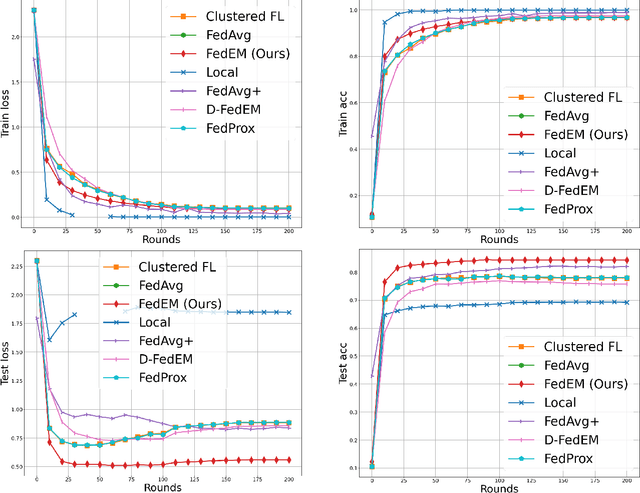

The increasing size of data generated by smartphones and IoT devices motivated the development of Federated Learning (FL), a framework for on-device collaborative training of machine learning models. First efforts in FL focused on learning a single global model with good average performance across clients, but the global model may be arbitrarily bad for a given client, due to the inherent heterogeneity of local data distributions. Federated multi-task learning (MTL) approaches can learn personalized models by formulating an opportune penalized optimization problem. The penalization term can capture complex relations among personalized models, but eschews clear statistical assumptions about local data distributions. In this work, we propose to study federated MTL under the flexible assumption that each local data distribution is a mixture of unknown underlying distributions. This assumption encompasses most of the existing personalized FL approaches and leads to federated EM-like algorithms for both client-server and fully decentralized settings. Moreover, it provides a principled way to serve personalized models to clients not seen at training time. The algorithms' convergence is analyzed through a novel federated surrogate optimization framework, which can be of general interest. Experimental results on FL benchmarks show that in most cases our approach provides models with higher accuracy and fairness than state-of-the-art methods.
On The Impact of Client Sampling on Federated Learning Convergence
Jul 26, 2021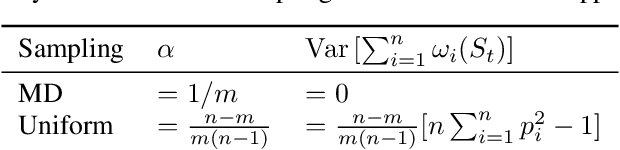
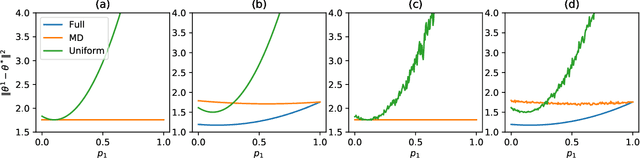
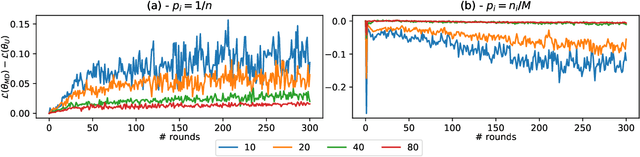

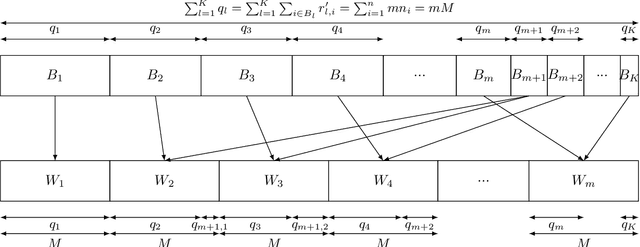
While clients' sampling is a central operation of current state-of-the-art federated learning (FL) approaches, the impact of this procedure on the convergence and speed of FL remains to date under-investigated. In this work we introduce a novel decomposition theorem for the convergence of FL, allowing to clearly quantify the impact of client sampling on the global model update. Contrarily to previous convergence analyses, our theorem provides the exact decomposition of a given convergence step, thus enabling accurate considerations about the role of client sampling and heterogeneity. First, we provide a theoretical ground for previously reported results on the relationship between FL convergence and the variance of the aggregation weights. Second, we prove for the first time that the quality of FL convergence is also impacted by the resulting covariance between aggregation weights. Third, we establish that the sum of the aggregation weights is another source of slow-down and should be equal to 1 to improve FL convergence speed. Our theory is general, and is here applied to Multinomial Distribution (MD) and Uniform sampling, the two default client sampling in FL, and demonstrated through a series of experiments in non-iid and unbalanced scenarios. Our results suggest that MD sampling should be used as default sampling scheme, due to the resilience to the changes in data ratio during the learning process, while Uniform sampling is superior only in the special case when clients have the same amount of data.
Clustered Sampling: Low-Variance and Improved Representativity for Clients Selection in Federated Learning
May 21, 2021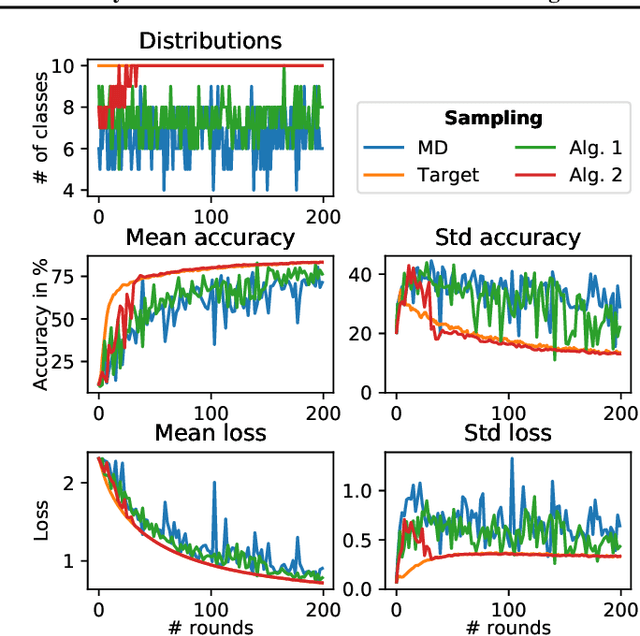
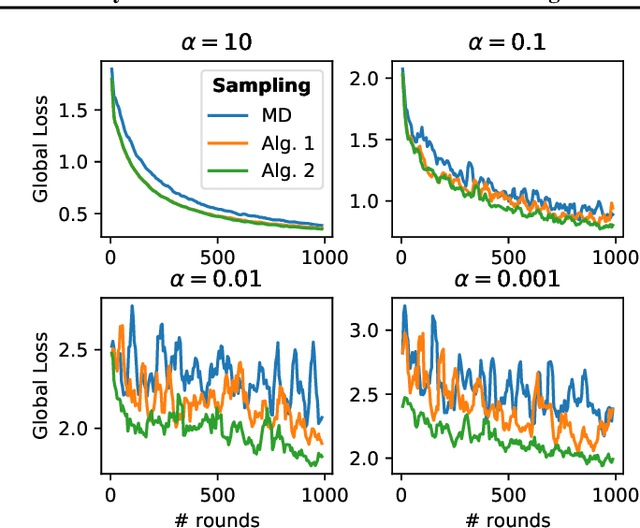

This work addresses the problem of optimizing communications between server and clients in federated learning (FL). Current sampling approaches in FL are either biased, or non optimal in terms of server-clients communications and training stability. To overcome this issue, we introduce \textit{clustered sampling} for clients selection. We prove that clustered sampling leads to better clients representatitivity and to reduced variance of the clients stochastic aggregation weights in FL. Compatibly with our theory, we provide two different clustering approaches enabling clients aggregation based on 1) sample size, and 2) models similarity. Through a series of experiments in non-iid and unbalanced scenarios, we demonstrate that model aggregation through clustered sampling consistently leads to better training convergence and variability when compared to standard sampling approaches. Our approach does not require any additional operation on the clients side, and can be seamlessly integrated in standard FL implementations. Finally, clustered sampling is compatible with existing methods and technologies for privacy enhancement, and for communication reduction through model compression.
Throughput-Optimal Topology Design for Cross-Silo Federated Learning
Oct 23, 2020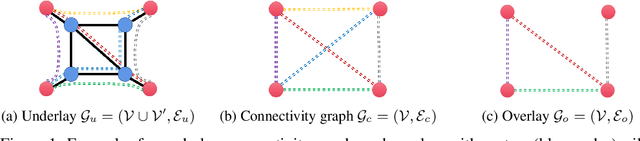


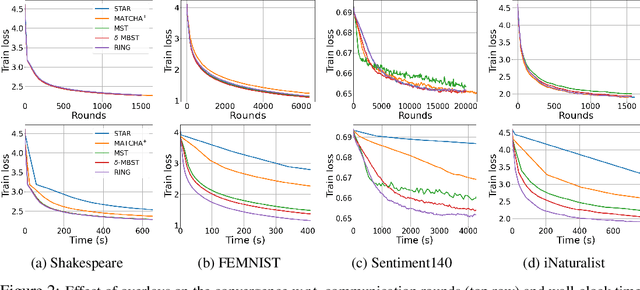
Federated learning usually employs a client-server architecture where an orchestrator iteratively aggregates model updates from remote clients and pushes them back a refined model. This approach may be inefficient in cross-silo settings, as close-by data silos with high-speed access links may exchange information faster than with the orchestrator, and the orchestrator may become a communication bottleneck. In this paper we define the problem of topology design for cross-silo federated learning using the theory of max-plus linear systems to compute the system throughput---number of communication rounds per time unit. We also propose practical algorithms that, under the knowledge of measurable network characteristics, find a topology with the largest throughput or with provable throughput guarantees. In realistic Internet networks with 10 Gbps access links for silos, our algorithms speed up training by a factor 9 and 1.5 in comparison to the master-slave architecture and to state-of-the-art MATCHA, respectively. Speedups are even larger with slower access links.