 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequential Informed Federated Unlearning: Efficient and Provable Client Unlearning in Federated Optimization
Nov 21, 2022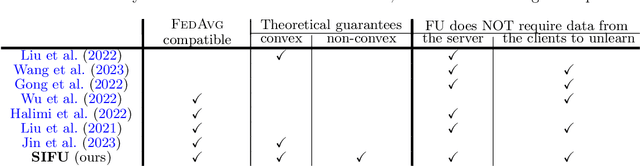
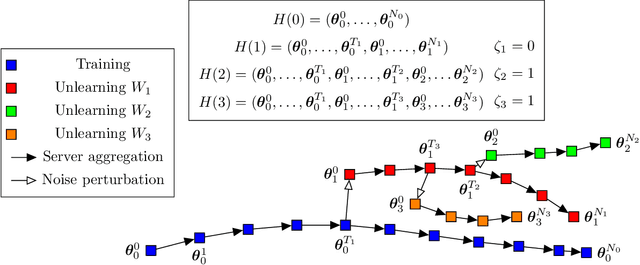
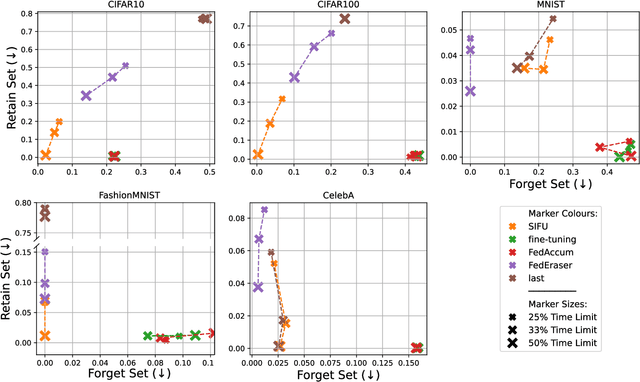
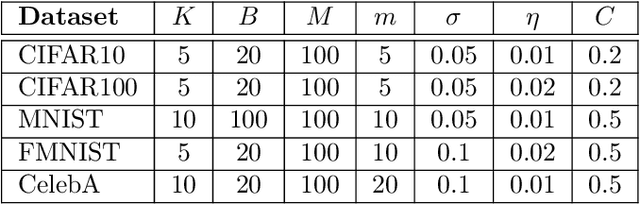
The aim of Machine Unlearning (MU) is to provide theoretical guarantees on the removal of the contribution of a given data point from a training procedure. Federated Unlearning (FU) consists in extending MU to unlearn a given client's contribution from a federated training routine. Current FU approaches are generally not scalable, and do not come with sound theoretical quantification of the effectiveness of unlearning. In this work we present Informed Federated Unlearning (IFU), a novel efficient and quantifiable FU approach. Upon unlearning request from a given client, IFU identifies the optimal FL iteration from which FL has to be reinitialized, with unlearning guarantees obtained through a randomized perturbation mechanism. The theory of IFU is also extended to account for sequential unlearning requests. Experimental results on different tasks and dataset show that IFU leads to more efficient unlearning procedures as compared to basic re-training and state-of-the-art FU approaches.
A General Theory for Federated Optimization with Asynchronous and Heterogeneous Clients Updates
Jun 21, 2022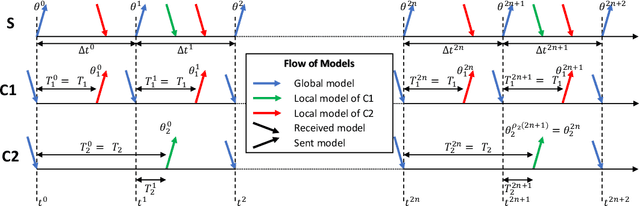


We propose a novel framework to study asynchronous federated learning optimization with delays in gradient updates. Our theoretical framework extends the standard FedAvg aggregation scheme by introducing stochastic aggregation weights to represent the variability of the clients update time, due for example to heterogeneous hardware capabilities. Our formalism applies to the general federated setting where clients have heterogeneous datasets and perform at least one step of stochastic gradient descent (SGD). We demonstrate convergence for such a scheme and provide sufficient conditions for the related minimum to be the optimum of the federated problem. We show that our general framework applies to existing optimization schemes including centralized learning, FedAvg, asynchronous FedAvg, and FedBuff. The theory here provided allows drawing meaningful guidelines for designing a federated learning experiment in heterogeneous conditions. In particular, we develop in this work FedFix, a novel extension of FedAvg enabling efficient asynchronous federated training while preserving the convergence stability of synchronous aggregation. We empirically demonstrate our theory on a series of experiments showing that asynchronous FedAvg leads to fast convergence at the expense of stability, and we finally demonstrate the improvements of FedFix over synchronous and asynchronous FedAvg.
On The Impact of Client Sampling on Federated Learning Convergence
Jul 26, 2021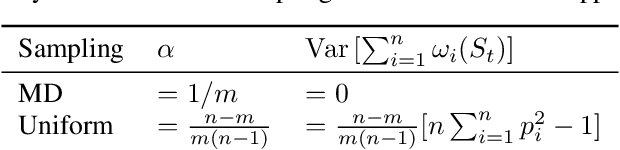
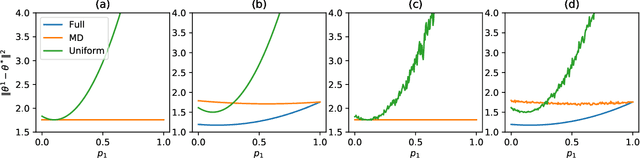
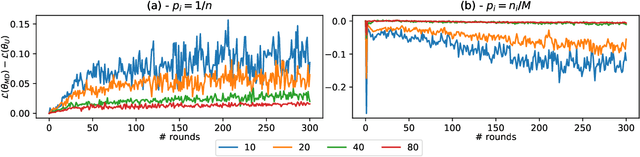

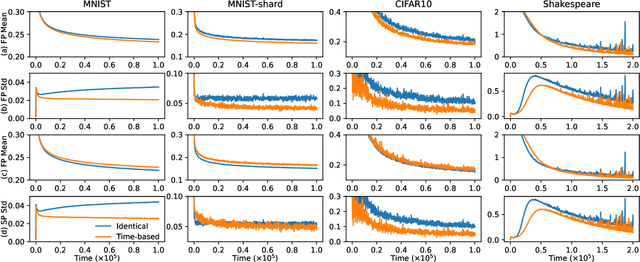
While clients' sampling is a central operation of current state-of-the-art federated learning (FL) approaches, the impact of this procedure on the convergence and speed of FL remains to date under-investigated. In this work we introduce a novel decomposition theorem for the convergence of FL, allowing to clearly quantify the impact of client sampling on the global model update. Contrarily to previous convergence analyses, our theorem provides the exact decomposition of a given convergence step, thus enabling accurate considerations about the role of client sampling and heterogeneity. First, we provide a theoretical ground for previously reported results on the relationship between FL convergence and the variance of the aggregation weights. Second, we prove for the first time that the quality of FL convergence is also impacted by the resulting covariance between aggregation weights. Third, we establish that the sum of the aggregation weights is another source of slow-down and should be equal to 1 to improve FL convergence speed. Our theory is general, and is here applied to Multinomial Distribution (MD) and Uniform sampling, the two default client sampling in FL, and demonstrated through a series of experiments in non-iid and unbalanced scenarios. Our results suggest that MD sampling should be used as default sampling scheme, due to the resilience to the changes in data ratio during the learning process, while Uniform sampling is superior only in the special case when clients have the same amount of data.
Clustered Sampling: Low-Variance and Improved Representativity for Clients Selection in Federated Learning
May 21, 2021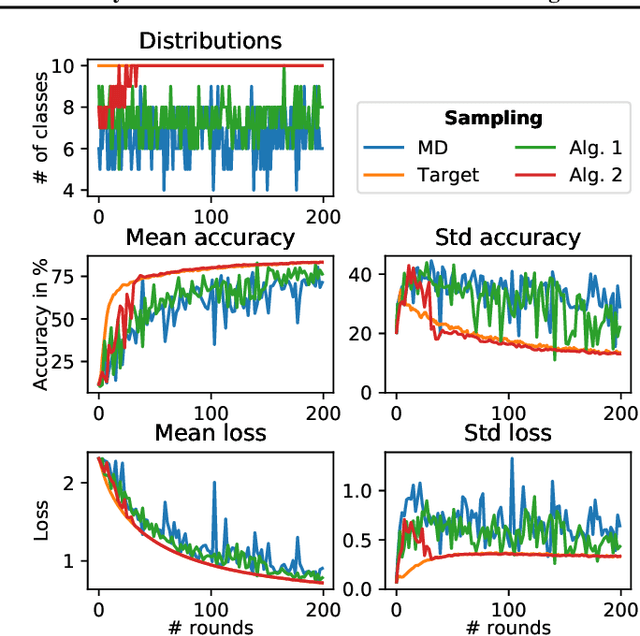
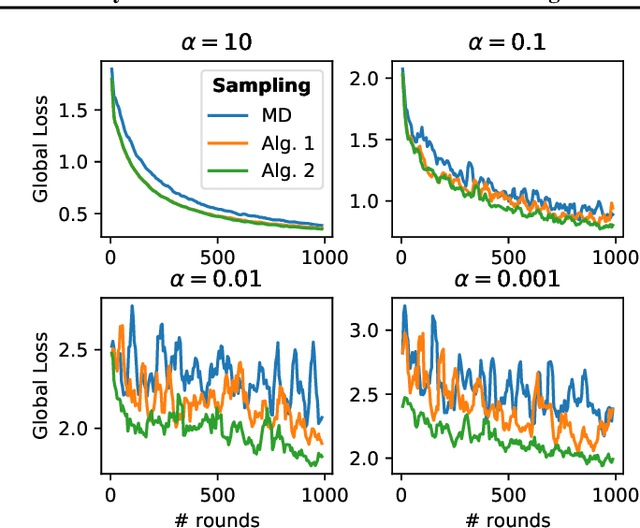

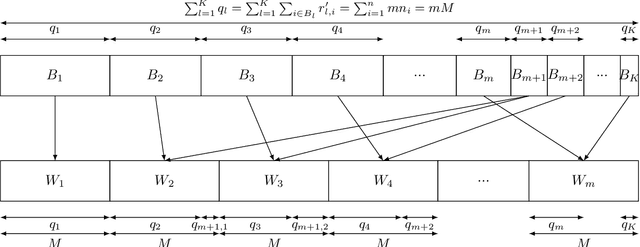
This work addresses the problem of optimizing communications between server and clients in federated learning (FL). Current sampling approaches in FL are either biased, or non optimal in terms of server-clients communications and training stability. To overcome this issue, we introduce \textit{clustered sampling} for clients selection. We prove that clustered sampling leads to better clients representatitivity and to reduced variance of the clients stochastic aggregation weights in FL. Compatibly with our theory, we provide two different clustering approaches enabling clients aggregation based on 1) sample size, and 2) models similarity. Through a series of experiments in non-iid and unbalanced scenarios, we demonstrate that model aggregation through clustered sampling consistently leads to better training convergence and variability when compared to standard sampling approaches. Our approach does not require any additional operation on the clients side, and can be seamlessly integrated in standard FL implementations. Finally, clustered sampling is compatible with existing methods and technologies for privacy enhancement, and for communication reduction through model compression.
Free-rider Attacks on Model Aggregation in Federated Learning
Jun 21, 2020

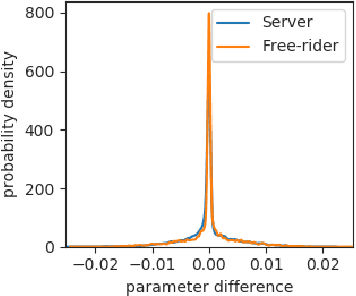

Free-rider attacks on federated learning consist in dissimulating participation to the federated learning process with the goal of obtaining the final aggregated model without actually contributing with any data. We introduce here the first theoretical and experimental analysis of free-rider attacks on federated learning schemes based on iterative parameters aggregation, such as FedAvg or FedProx, and provide formal guarantees for these attacks to converge to the aggregated models of the fair participants. We first show that a straightforward implementation of this attack can be simply achieved by not updating the local parameters during the iterative federated optimization. As this attack can be detected by adopting simple countermeasures at the server level, we subsequently study more complex disguising schemes based on stochastic updates of the free-rider parameters. We demonstrate the proposed strategies on a number of experimental scenarios, in both iid and non-iid settings. We conclude by providing recommendations to avoid free-rider attacks in real world applications of federated learning, especially in sensitive domains where security of data and models is critical.