 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNo More Guessing: a Verifiable Gradient Inversion Attack in Federated Learning
Apr 16, 2026Gradient inversion attacks threaten client privacy in federated learning by reconstructing training samples from clients' shared gradients. Gradients aggregate contributions from multiple records and existing attacks may fail to disentangle them, yielding incorrect reconstructions with no intrinsic way to certify success. In vision and language, attackers may fall back on human inspection to judge reconstruction plausibility, but this is far less feasible for numerical tabular records, fueling the impression that tabular data is less vulnerable. We challenge this perception by proposing a verifiable gradient inversion attack (VGIA) that provides an explicit certificate of correctness for reconstructed samples. Our method adopts a geometric view of ReLU leakage: the activation boundary of a fully connected layer defines a hyperplane in input space. VGIA introduces an algebraic, subspace-based verification test that detects when a hyperplane-delimited region contains exactly one record. Once isolation is certified, VGIA recovers the corresponding feature vector analytically and reconstructs the target via a lightweight optimization step. Experiments on tabular benchmarks with large batch sizes demonstrate exact record and target recovery in regimes where existing state-of-the-art attacks either fail or cannot assess reconstruction fidelity. Compared to prior geometric approaches, VGIA allocates hyperplane queries more effectively, yielding faster reconstructions with fewer attack rounds.
Deadline-Aware Online Scheduling for LLM Fine-Tuning with Spot Market Predictions
Dec 24, 2025



As foundation models grow in size, fine-tuning them becomes increasingly expensive. While GPU spot instances offer a low-cost alternative to on-demand resources, their volatile prices and availability make deadline-aware scheduling particularly challenging. We tackle this difficulty by using a mix of spot and on-demand instances. Distinctively, we show the predictability of prices and availability in a spot instance market, the power of prediction in enabling cost-efficient scheduling and its sensitivity to estimation errors. An integer programming problem is formulated to capture the use of mixed instances under both the price and availability dynamics. We propose an online allocation algorithm with prediction based on the committed horizon control approach that leverages a \emph{commitment level} to enforce the partial sequence of decisions. When this prediction becomes inaccurate, we further present a complementary online algorithm without predictions. An online policy selection algorithm is developed that learns the best policy from a pool constructed by varying the parameters of both algorithms. We prove that the prediction-based algorithm achieves tighter performance bounds as prediction error decreases, while the policy selection algorithm possesses a regret bound of $\mathcal{O}(\sqrt{T})$. Experimental results demonstrate that our online framework can adaptively select the best policy under varying spot market dynamics and prediction quality, consistently outperforming baselines and improving utility by up to 54.8\%.
Reconciling Communication Compression and Byzantine-Robustness in Distributed Learning
Aug 23, 2025Distributed learning (DL) enables scalable model training over decentralized data, but remains challenged by Byzantine faults and high communication costs. While both issues have been studied extensively in isolation, their interaction is less explored. Prior work shows that naively combining communication compression with Byzantine-robust aggregation degrades resilience to faulty nodes (or workers). The state-of-the-art algorithm, namely Byz-DASHA-PAGE [29], makes use of the momentum variance reduction scheme to mitigate the detrimental impact of compression noise on Byzantine-robustness. We propose a new algorithm, named RoSDHB, that integrates the classic Polyak's momentum with a new coordinated compression mechanism. We show that RoSDHB performs comparably to Byz-DASHA-PAGE under the standard (G, B)-gradient dissimilarity heterogeneity model, while it relies on fewer assumptions. In particular, we only assume Lipschitz smoothness of the average loss function of the honest workers, in contrast to [29]that additionally assumes a special smoothness of bounded global Hessian variance. Empirical results on benchmark image classification task show that RoSDHB achieves strong robustness with significant communication savings.
The Cell Ontology in the age of single-cell omics
Jun 10, 2025Single-cell omics technologies have transformed our understanding of cellular diversity by enabling high-resolution profiling of individual cells. However, the unprecedented scale and heterogeneity of these datasets demand robust frameworks for data integration and annotation. The Cell Ontology (CL) has emerged as a pivotal resource for achieving FAIR (Findable, Accessible, Interoperable, and Reusable) data principles by providing standardized, species-agnostic terms for canonical cell types - forming a core component of a wide range of platforms and tools. In this paper, we describe the wide variety of uses of CL in these platforms and tools and detail ongoing work to improve and extend CL content including the addition of transcriptomically defined types, working closely with major atlasing efforts including the Human Cell Atlas and the Brain Initiative Cell Atlas Network to support their needs. We cover the challenges and future plans for harmonising classical and transcriptomic cell type definitions, integrating markers and using Large Language Models (LLMs) to improve content and efficiency of CL workflows.
mmRAG: A Modular Benchmark for Retrieval-Augmented Generation over Text, Tables, and Knowledge Graphs
May 16, 2025Retrieval-Augmented Generation (RAG) has emerged as a powerful paradigm for enhancing the capabilities of large language models. However, existing RAG evaluation predominantly focuses on text retrieval and relies on opaque, end-to-end assessments of generated outputs. To address these limitations, we introduce mmRAG, a modular benchmark designed for evaluating multi-modal RAG systems. Our benchmark integrates queries from six diverse question-answering datasets spanning text, tables, and knowledge graphs, which we uniformly convert into retrievable documents. To enable direct, granular evaluation of individual RAG components -- such as the accuracy of retrieval and query routing -- beyond end-to-end generation quality, we follow standard information retrieval procedures to annotate document relevance and derive dataset relevance. We establish baseline performance by evaluating a wide range of RAG implementations on mmRAG.
Cutting Through Privacy: A Hyperplane-Based Data Reconstruction Attack in Federated Learning
May 15, 2025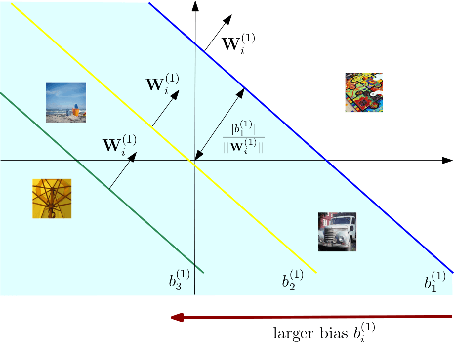
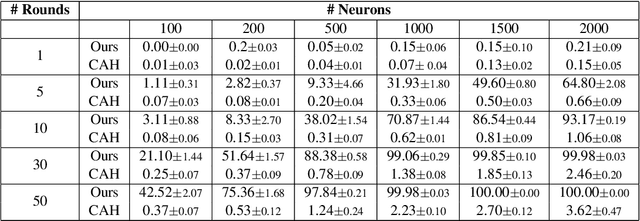
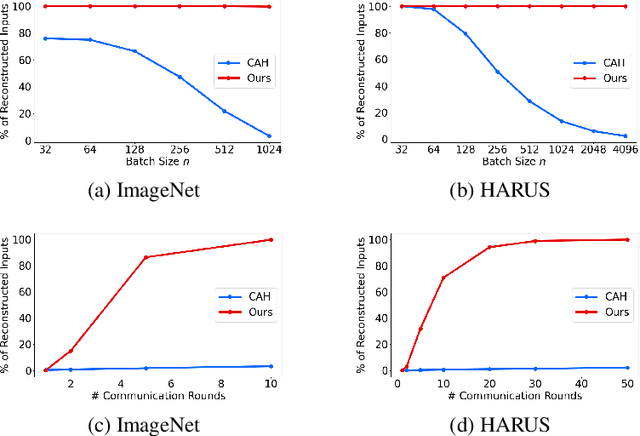
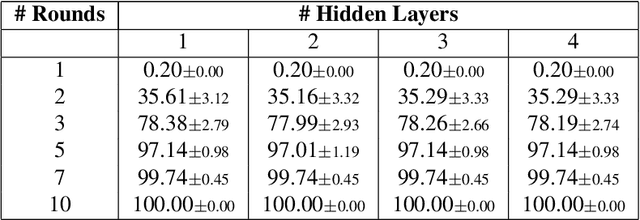
Federated Learning (FL) enables collaborative training of machine learning models across distributed clients without sharing raw data, ostensibly preserving data privacy. Nevertheless, recent studies have revealed critical vulnerabilities in FL, showing that a malicious central server can manipulate model updates to reconstruct clients' private training data. Existing data reconstruction attacks have important limitations: they often rely on assumptions about the clients' data distribution or their efficiency significantly degrades when batch sizes exceed just a few tens of samples. In this work, we introduce a novel data reconstruction attack that overcomes these limitations. Our method leverages a new geometric perspective on fully connected layers to craft malicious model parameters, enabling the perfect recovery of arbitrarily large data batches in classification tasks without any prior knowledge of clients' data. Through extensive experiments on both image and tabular datasets, we demonstrate that our attack outperforms existing methods and achieves perfect reconstruction of data batches two orders of magnitude larger than the state of the art.
Attribute Inference Attacks for Federated Regression Tasks
Nov 19, 2024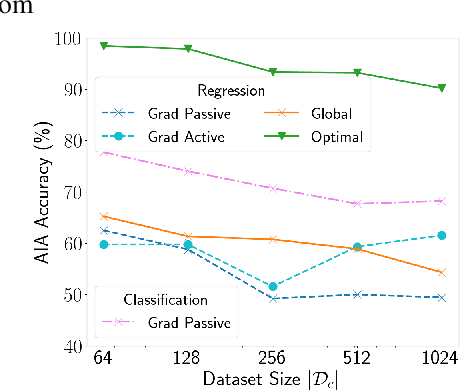
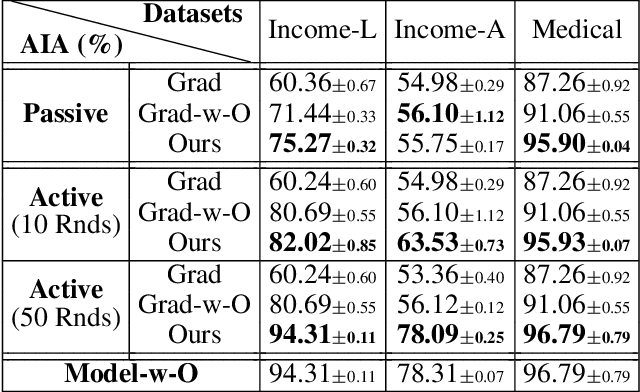
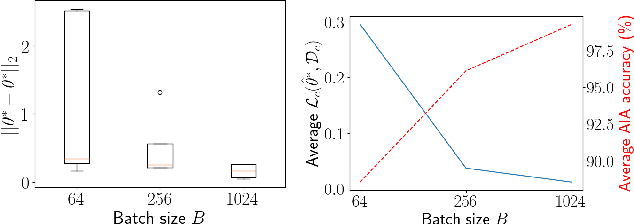
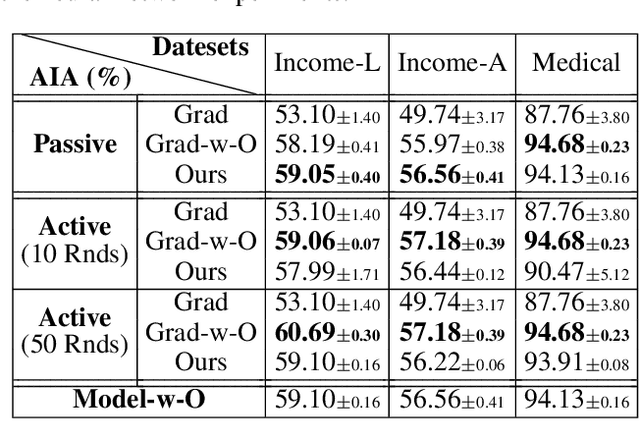
Federated Learning (FL) enables multiple clients, such as mobile phones and IoT devices, to collaboratively train a global machine learning model while keeping their data localized. However, recent studies have revealed that the training phase of FL is vulnerable to reconstruction attacks, such as attribute inference attacks (AIA), where adversaries exploit exchanged messages and auxiliary public information to uncover sensitive attributes of targeted clients. While these attacks have been extensively studied in the context of classification tasks, their impact on regression tasks remains largely unexplored. In this paper, we address this gap by proposing novel model-based AIAs specifically designed for regression tasks in FL environments. Our approach considers scenarios where adversaries can either eavesdrop on exchanged messages or directly interfere with the training process. We benchmark our proposed attacks against state-of-the-art methods using real-world datasets. The results demonstrate a significant increase in reconstruction accuracy, particularly in heterogeneous client datasets, a common scenario in FL. The efficacy of our model-based AIAs makes them better candidates for empirically quantifying privacy leakage for federated regression tasks.
Federated Learning for Cooperative Inference Systems: The Case of Early Exit Networks
May 07, 2024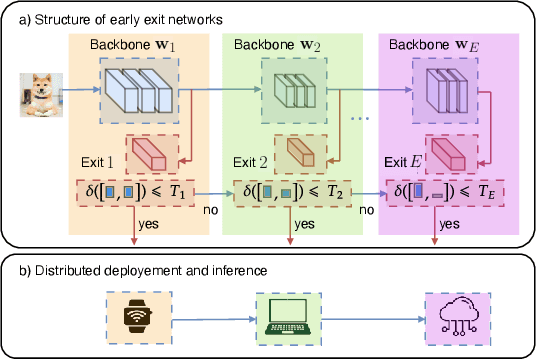
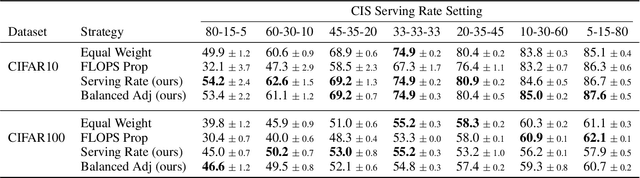
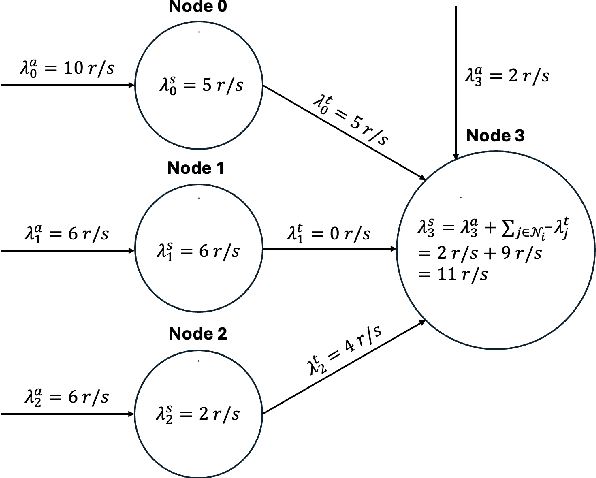
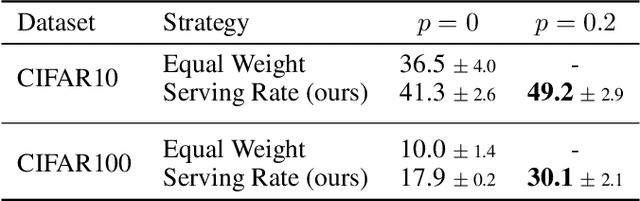
As Internet of Things (IoT) technology advances, end devices like sensors and smartphones are progressively equipped with AI models tailored to their local memory and computational constraints. Local inference reduces communication costs and latency; however, these smaller models typically underperform compared to more sophisticated models deployed on edge servers or in the cloud. Cooperative Inference Systems (CISs) address this performance trade-off by enabling smaller devices to offload part of their inference tasks to more capable devices. These systems often deploy hierarchical models that share numerous parameters, exemplified by Deep Neural Networks (DNNs) that utilize strategies like early exits or ordered dropout. In such instances, Federated Learning (FL) may be employed to jointly train the models within a CIS. Yet, traditional training methods have overlooked the operational dynamics of CISs during inference, particularly the potential high heterogeneity in serving rates across clients. To address this gap, we propose a novel FL approach designed explicitly for use in CISs that accounts for these variations in serving rates. Our framework not only offers rigorous theoretical guarantees, but also surpasses state-of-the-art (SOTA) training algorithms for CISs, especially in scenarios where inference request rates or data availability are uneven among clients.
A Cautionary Tale: On the Role of Reference Data in Empirical Privacy Defenses
Oct 18, 2023



Within the realm of privacy-preserving machine learning, empirical privacy defenses have been proposed as a solution to achieve satisfactory levels of training data privacy without a significant drop in model utility. Most existing defenses against membership inference attacks assume access to reference data, defined as an additional dataset coming from the same (or a similar) underlying distribution as training data. Despite the common use of reference data, previous works are notably reticent about defining and evaluating reference data privacy. As gains in model utility and/or training data privacy may come at the expense of reference data privacy, it is essential that all three aspects are duly considered. In this paper, we first examine the availability of reference data and its privacy treatment in previous works and demonstrate its necessity for fairly comparing defenses. Second, we propose a baseline defense that enables the utility-privacy tradeoff with respect to both training and reference data to be easily understood. Our method is formulated as an empirical risk minimization with a constraint on the generalization error, which, in practice, can be evaluated as a weighted empirical risk minimization (WERM) over the training and reference datasets. Although we conceived of WERM as a simple baseline, our experiments show that, surprisingly, it outperforms the most well-studied and current state-of-the-art empirical privacy defenses using reference data for nearly all relative privacy levels of reference and training data. Our investigation also reveals that these existing methods are unable to effectively trade off reference data privacy for model utility and/or training data privacy. Overall, our work highlights the need for a proper evaluation of the triad model utility / training data privacy / reference data privacy when comparing privacy defenses.
Local Model Reconstruction Attacks in Federated Learning and their Uses
Oct 28, 2022In this paper, we initiate the study of local model reconstruction attacks for federated learning, where a honest-but-curious adversary eavesdrops the messages exchanged between a targeted client and the server, and then reconstructs the local/personalized model of the victim. The local model reconstruction attack allows the adversary to trigger other classical attacks in a more effective way, since the local model only depends on the client's data and can leak more private information than the global model learned by the server. Additionally, we propose a novel model-based attribute inference attack in federated learning leveraging the local model reconstruction attack. We provide an analytical lower-bound for this attribute inference attack. Empirical results using real world datasets confirm that our local reconstruction attack works well for both regression and classification tasks. Moreover, we benchmark our novel attribute inference attack against the state-of-the-art attacks in federated learning. Our attack results in higher reconstruction accuracy especially when the clients' datasets are heterogeneous. Our work provides a new angle for designing powerful and explainable attacks to effectively quantify the privacy risk in FL.