 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoDance: An Unbind-Rebind Paradigm for Robust Multi-Subject Animation
Jan 16, 2026Character image animation is gaining significant importance across various domains, driven by the demand for robust and flexible multi-subject rendering. While existing methods excel in single-person animation, they struggle to handle arbitrary subject counts, diverse character types, and spatial misalignment between the reference image and the driving poses. We attribute these limitations to an overly rigid spatial binding that forces strict pixel-wise alignment between the pose and reference, and an inability to consistently rebind motion to intended subjects. To address these challenges, we propose CoDance, a novel Unbind-Rebind framework that enables the animation of arbitrary subject counts, types, and spatial configurations conditioned on a single, potentially misaligned pose sequence. Specifically, the Unbind module employs a novel pose shift encoder to break the rigid spatial binding between the pose and the reference by introducing stochastic perturbations to both poses and their latent features, thereby compelling the model to learn a location-agnostic motion representation. To ensure precise control and subject association, we then devise a Rebind module, leveraging semantic guidance from text prompts and spatial guidance from subject masks to direct the learned motion to intended characters. Furthermore, to facilitate comprehensive evaluation, we introduce a new multi-subject CoDanceBench. Extensive experiments on CoDanceBench and existing datasets show that CoDance achieves SOTA performance, exhibiting remarkable generalization across diverse subjects and spatial layouts. The code and weights will be open-sourced.
FlowNet: Modeling Dynamic Spatio-Temporal Systems via Flow Propagation
Nov 05, 2025Accurately modeling complex dynamic spatio-temporal systems requires capturing flow-mediated interdependencies and context-sensitive interaction dynamics. Existing methods, predominantly graph-based or attention-driven, rely on similarity-driven connectivity assumptions, neglecting asymmetric flow exchanges that govern system evolution. We propose Spatio-Temporal Flow, a physics-inspired paradigm that explicitly models dynamic node couplings through quantifiable flow transfers governed by conservation principles. Building on this, we design FlowNet, a novel architecture leveraging flow tokens as information carriers to simulate source-to-destination transfers via Flow Allocation Modules, ensuring state redistribution aligns with conservation laws. FlowNet dynamically adjusts the interaction radius through an Adaptive Spatial Masking module, suppressing irrelevant noise while enabling context-aware propagation. A cascaded architecture enhances scalability and nonlinear representation capacity. Experiments demonstrate that FlowNet significantly outperforms existing state-of-the-art approaches on seven metrics in the modeling of three real-world systems, validating its efficiency and physical interpretability. We establish a principled methodology for modeling complex systems through spatio-temporal flow interactions.
ROSE: Remove Objects with Side Effects in Videos
Aug 26, 2025Video object removal has achieved advanced performance due to the recent success of video generative models. However, when addressing the side effects of objects, e.g., their shadows and reflections, existing works struggle to eliminate these effects for the scarcity of paired video data as supervision. This paper presents ROSE, termed Remove Objects with Side Effects, a framework that systematically studies the object's effects on environment, which can be categorized into five common cases: shadows, reflections, light, translucency and mirror. Given the challenges of curating paired videos exhibiting the aforementioned effects, we leverage a 3D rendering engine for synthetic data generation. We carefully construct a fully-automatic pipeline for data preparation, which simulates a large-scale paired dataset with diverse scenes, objects, shooting angles, and camera trajectories. ROSE is implemented as an video inpainting model built on diffusion transformer. To localize all object-correlated areas, the entire video is fed into the model for reference-based erasing. Moreover, additional supervision is introduced to explicitly predict the areas affected by side effects, which can be revealed through the differential mask between the paired videos. To fully investigate the model performance on various side effect removal, we presents a new benchmark, dubbed ROSE-Bench, incorporating both common scenarios and the five special side effects for comprehensive evaluation. Experimental results demonstrate that ROSE achieves superior performance compared to existing video object erasing models and generalizes well to real-world video scenarios. The project page is https://rose2025-inpaint.github.io/.
Dimension-Reduction Attack! Video Generative Models are Experts on Controllable Image Synthesis
May 29, 2025Video generative models can be regarded as world simulators due to their ability to capture dynamic, continuous changes inherent in real-world environments. These models integrate high-dimensional information across visual, temporal, spatial, and causal dimensions, enabling predictions of subjects in various status. A natural and valuable research direction is to explore whether a fully trained video generative model in high-dimensional space can effectively support lower-dimensional tasks such as controllable image generation. In this work, we propose a paradigm for video-to-image knowledge compression and task adaptation, termed \textit{Dimension-Reduction Attack} (\texttt{DRA-Ctrl}), which utilizes the strengths of video models, including long-range context modeling and flatten full-attention, to perform various generation tasks. Specially, to address the challenging gap between continuous video frames and discrete image generation, we introduce a mixup-based transition strategy that ensures smooth adaptation. Moreover, we redesign the attention structure with a tailored masking mechanism to better align text prompts with image-level control. Experiments across diverse image generation tasks, such as subject-driven and spatially conditioned generation, show that repurposed video models outperform those trained directly on images. These results highlight the untapped potential of large-scale video generators for broader visual applications. \texttt{DRA-Ctrl} provides new insights into reusing resource-intensive video models and lays foundation for future unified generative models across visual modalities. The project page is https://dra-ctrl-2025.github.io/DRA-Ctrl/.
mmRAG: A Modular Benchmark for Retrieval-Augmented Generation over Text, Tables, and Knowledge Graphs
May 16, 2025Retrieval-Augmented Generation (RAG) has emerged as a powerful paradigm for enhancing the capabilities of large language models. However, existing RAG evaluation predominantly focuses on text retrieval and relies on opaque, end-to-end assessments of generated outputs. To address these limitations, we introduce mmRAG, a modular benchmark designed for evaluating multi-modal RAG systems. Our benchmark integrates queries from six diverse question-answering datasets spanning text, tables, and knowledge graphs, which we uniformly convert into retrievable documents. To enable direct, granular evaluation of individual RAG components -- such as the accuracy of retrieval and query routing -- beyond end-to-end generation quality, we follow standard information retrieval procedures to annotate document relevance and derive dataset relevance. We establish baseline performance by evaluating a wide range of RAG implementations on mmRAG.
Wan: Open and Advanced Large-Scale Video Generative Models
Mar 26, 2025



This report presents Wan, a comprehensive and open suite of video foundation models designed to push the boundaries of video generation. Built upon the mainstream diffusion transformer paradigm, Wan achieves significant advancements in generative capabilities through a series of innovations, including our novel VAE, scalable pre-training strategies, large-scale data curation, and automated evaluation metrics. These contributions collectively enhance the model's performance and versatility. Specifically, Wan is characterized by four key features: Leading Performance: The 14B model of Wan, trained on a vast dataset comprising billions of images and videos, demonstrates the scaling laws of video generation with respect to both data and model size. It consistently outperforms the existing open-source models as well as state-of-the-art commercial solutions across multiple internal and external benchmarks, demonstrating a clear and significant performance superiority. Comprehensiveness: Wan offers two capable models, i.e., 1.3B and 14B parameters, for efficiency and effectiveness respectively. It also covers multiple downstream applications, including image-to-video, instruction-guided video editing, and personal video generation, encompassing up to eight tasks. Consumer-Grade Efficiency: The 1.3B model demonstrates exceptional resource efficiency, requiring only 8.19 GB VRAM, making it compatible with a wide range of consumer-grade GPUs. Openness: We open-source the entire series of Wan, including source code and all models, with the goal of fostering the growth of the video generation community. This openness seeks to significantly expand the creative possibilities of video production in the industry and provide academia with high-quality video foundation models. All the code and models are available at https://github.com/Wan-Video/Wan2.1.
Mimir: Improving Video Diffusion Models for Precise Text Understanding
Dec 04, 2024



Text serves as the key control signal in video generation due to its narrative nature. To render text descriptions into video clips, current video diffusion models borrow features from text encoders yet struggle with limited text comprehension. The recent success of large language models (LLMs) showcases the power of decoder-only transformers, which offers three clear benefits for text-to-video (T2V) generation, namely, precise text understanding resulting from the superior scalability, imagination beyond the input text enabled by next token prediction, and flexibility to prioritize user interests through instruction tuning. Nevertheless, the feature distribution gap emerging from the two different text modeling paradigms hinders the direct use of LLMs in established T2V models. This work addresses this challenge with Mimir, an end-to-end training framework featuring a carefully tailored token fuser to harmonize the outputs from text encoders and LLMs. Such a design allows the T2V model to fully leverage learned video priors while capitalizing on the text-related capability of LLMs. Extensive quantitative and qualitative results demonstrate the effectiveness of Mimir in generating high-quality videos with excellent text comprehension, especially when processing short captions and managing shifting motions. Project page: https://lucaria-academy.github.io/Mimir/
In-Context LoRA for Diffusion Transformers
Oct 31, 2024



Recent research arXiv:2410.15027 has explored the use of diffusion transformers (DiTs) for task-agnostic image generation by simply concatenating attention tokens across images. However, despite substantial computational resources, the fidelity of the generated images remains suboptimal. In this study, we reevaluate and streamline this framework by hypothesizing that text-to-image DiTs inherently possess in-context generation capabilities, requiring only minimal tuning to activate them. Through diverse task experiments, we qualitatively demonstrate that existing text-to-image DiTs can effectively perform in-context generation without any tuning. Building on this insight, we propose a remarkably simple pipeline to leverage the in-context abilities of DiTs: (1) concatenate images instead of tokens, (2) perform joint captioning of multiple images, and (3) apply task-specific LoRA tuning using small datasets (e.g., $20\sim 100$ samples) instead of full-parameter tuning with large datasets. We name our models In-Context LoRA (IC-LoRA). This approach requires no modifications to the original DiT models, only changes to the training data. Remarkably, our pipeline generates high-fidelity image sets that better adhere to prompts. While task-specific in terms of tuning data, our framework remains task-agnostic in architecture and pipeline, offering a powerful tool for the community and providing valuable insights for further research on product-level task-agnostic generation systems. We release our code, data, and models at https://github.com/ali-vilab/In-Context-LoRA
Group Diffusion Transformers are Unsupervised Multitask Learners
Oct 19, 2024
While large language models (LLMs) have revolutionized natural language processing with their task-agnostic capabilities, visual generation tasks such as image translation, style transfer, and character customization still rely heavily on supervised, task-specific datasets. In this work, we introduce Group Diffusion Transformers (GDTs), a novel framework that unifies diverse visual generation tasks by redefining them as a group generation problem. In this approach, a set of related images is generated simultaneously, optionally conditioned on a subset of the group. GDTs build upon diffusion transformers with minimal architectural modifications by concatenating self-attention tokens across images. This allows the model to implicitly capture cross-image relationships (e.g., identities, styles, layouts, surroundings, and color schemes) through caption-based correlations. Our design enables scalable, unsupervised, and task-agnostic pretraining using extensive collections of image groups sourced from multimodal internet articles, image galleries, and video frames. We evaluate GDTs on a comprehensive benchmark featuring over 200 instructions across 30 distinct visual generation tasks, including picture book creation, font design, style transfer, sketching, colorization, drawing sequence generation, and character customization. Our models achieve competitive zero-shot performance without any additional fine-tuning or gradient updates. Furthermore, ablation studies confirm the effectiveness of key components such as data scaling, group size, and model design. These results demonstrate the potential of GDTs as scalable, general-purpose visual generation systems.
DreamVideo-2: Zero-Shot Subject-Driven Video Customization with Precise Motion Control
Oct 17, 2024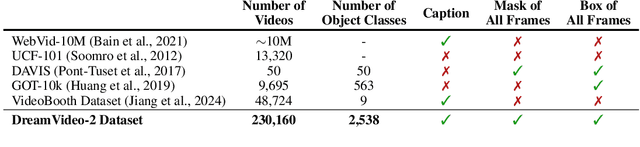
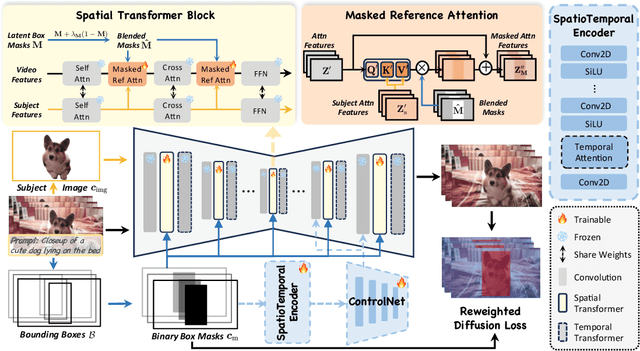


Recent advances in customized video generation have enabled users to create videos tailored to both specific subjects and motion trajectories. However, existing methods often require complicated test-time fine-tuning and struggle with balancing subject learning and motion control, limiting their real-world applications. In this paper, we present DreamVideo-2, a zero-shot video customization framework capable of generating videos with a specific subject and motion trajectory, guided by a single image and a bounding box sequence, respectively, and without the need for test-time fine-tuning. Specifically, we introduce reference attention, which leverages the model's inherent capabilities for subject learning, and devise a mask-guided motion module to achieve precise motion control by fully utilizing the robust motion signal of box masks derived from bounding boxes. While these two components achieve their intended functions, we empirically observe that motion control tends to dominate over subject learning. To address this, we propose two key designs: 1) the masked reference attention, which integrates a blended latent mask modeling scheme into reference attention to enhance subject representations at the desired positions, and 2) a reweighted diffusion loss, which differentiates the contributions of regions inside and outside the bounding boxes to ensure a balance between subject and motion control. Extensive experimental results on a newly curated dataset demonstrate that DreamVideo-2 outperforms state-of-the-art methods in both subject customization and motion control. The dataset, code, and models will be made publicly available.