 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWan: Open and Advanced Large-Scale Video Generative Models
Mar 26, 2025



This report presents Wan, a comprehensive and open suite of video foundation models designed to push the boundaries of video generation. Built upon the mainstream diffusion transformer paradigm, Wan achieves significant advancements in generative capabilities through a series of innovations, including our novel VAE, scalable pre-training strategies, large-scale data curation, and automated evaluation metrics. These contributions collectively enhance the model's performance and versatility. Specifically, Wan is characterized by four key features: Leading Performance: The 14B model of Wan, trained on a vast dataset comprising billions of images and videos, demonstrates the scaling laws of video generation with respect to both data and model size. It consistently outperforms the existing open-source models as well as state-of-the-art commercial solutions across multiple internal and external benchmarks, demonstrating a clear and significant performance superiority. Comprehensiveness: Wan offers two capable models, i.e., 1.3B and 14B parameters, for efficiency and effectiveness respectively. It also covers multiple downstream applications, including image-to-video, instruction-guided video editing, and personal video generation, encompassing up to eight tasks. Consumer-Grade Efficiency: The 1.3B model demonstrates exceptional resource efficiency, requiring only 8.19 GB VRAM, making it compatible with a wide range of consumer-grade GPUs. Openness: We open-source the entire series of Wan, including source code and all models, with the goal of fostering the growth of the video generation community. This openness seeks to significantly expand the creative possibilities of video production in the industry and provide academia with high-quality video foundation models. All the code and models are available at https://github.com/Wan-Video/Wan2.1.
What Is a Good Caption? A Comprehensive Visual Caption Benchmark for Evaluating Both Correctness and Coverage of MLLMs
Feb 19, 2025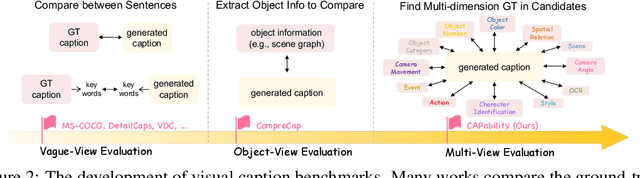
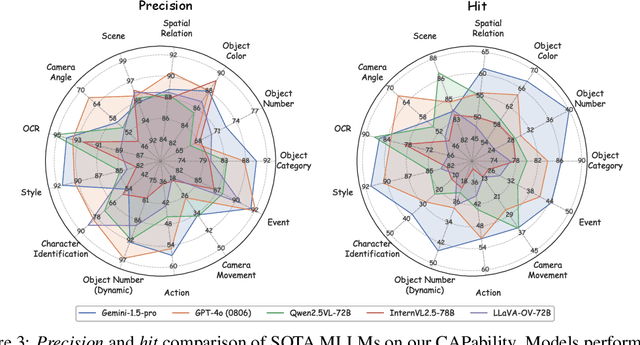


Recent advancements in Multimodal Large Language Models (MLLMs) have rendered traditional visual captioning benchmarks obsolete, as they primarily evaluate short descriptions with outdated metrics. While recent benchmarks address these limitations by decomposing captions into visual elements and adopting model-based evaluation, they remain incomplete-overlooking critical aspects, while providing vague, non-explanatory scores. To bridge this gap, we propose CV-CapBench, a Comprehensive Visual Caption Benchmark that systematically evaluates caption quality across 6 views and 13 dimensions. CV-CapBench introduces precision, recall, and hit rate metrics for each dimension, uniquely assessing both correctness and coverage. Experiments on leading MLLMs reveal significant capability gaps, particularly in dynamic and knowledge-intensive dimensions. These findings provide actionable insights for future research. The code and data will be released.
Exploiting Images for Video Recognition with Hierarchical Generative Adversarial Networks
May 11, 2018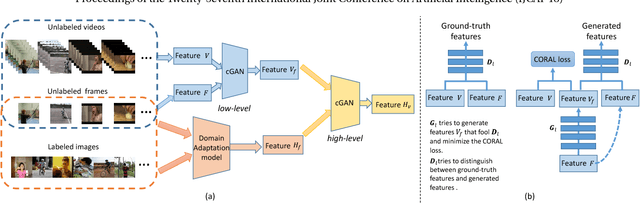
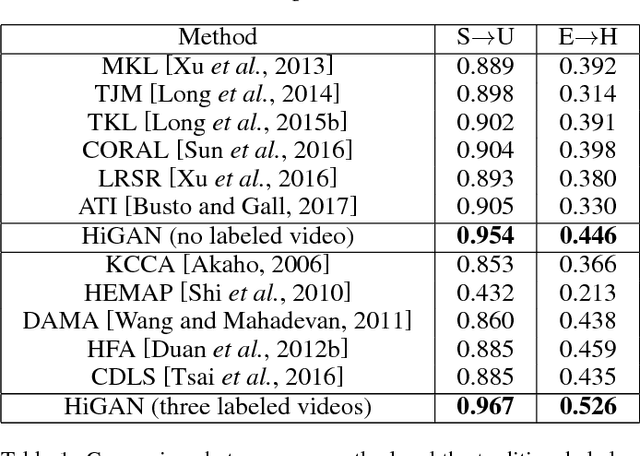
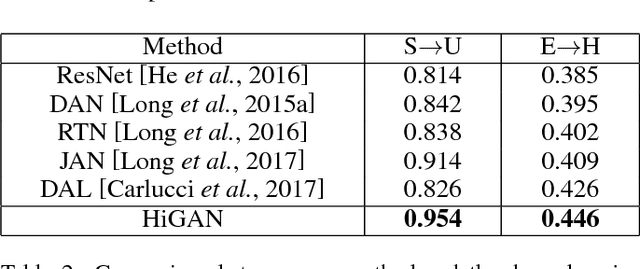

Existing deep learning methods of video recognition usually require a large number of labeled videos for training. But for a new task, videos are often unlabeled and it is also time-consuming and labor-intensive to annotate them. Instead of human annotation, we try to make use of existing fully labeled images to help recognize those videos. However, due to the problem of domain shifts and heterogeneous feature representations, the performance of classifiers trained on images may be dramatically degraded for video recognition tasks. In this paper, we propose a novel method, called Hierarchical Generative Adversarial Networks (HiGAN), to enhance recognition in videos (i.e., target domain) by transferring knowledge from images (i.e., source domain). The HiGAN model consists of a \emph{low-level} conditional GAN and a \emph{high-level} conditional GAN. By taking advantage of these two-level adversarial learning, our method is capable of learning a domain-invariant feature representation of source images and target videos. Comprehensive experiments on two challenging video recognition datasets (i.e. UCF101 and HMDB51) demonstrate the effectiveness of the proposed method when compared with the existing state-of-the-art domain adaptation methods.