 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIBench: Evaluating Visual-Logical Consistency in Academic Illustration Generation
Mar 31, 2026Although image generation has boosted various applications via its rapid evolution, whether the state-of-the-art models are able to produce ready-to-use academic illustrations for papers is still largely unexplored. Directly comparing or evaluating the illustration with VLM is native but requires oracle multi-modal understanding ability, which is unreliable for long and complex texts and illustrations. To address this, we propose AIBench, the first benchmark using VQA for evaluating logic correctness of the academic illustrations and VLMs for assessing aesthetics. In detail, we designed four levels of questions proposed from a logic diagram summarized from the method part of the paper, which query whether the generated illustration aligns with the paper on different scales. Our VQA-based approach raises more accurate and detailed evaluations on visual-logical consistency while relying less on the ability of the judger VLM. With our high-quality AIBench, we conduct extensive experiments and conclude that the performance gap between models on this task is significantly larger than general ones, reflecting their various complex reasoning and high-density generation ability. Further, the logic and aesthetics are hard to optimize simultaneously as in handcrafted illustrations. Additional experiments further state that test-time scaling on both abilities significantly boosts the performance on this task.
GenAgent: Scaling Text-to-Image Generation via Agentic Multimodal Reasoning
Jan 26, 2026We introduce GenAgent, unifying visual understanding and generation through an agentic multimodal model. Unlike unified models that face expensive training costs and understanding-generation trade-offs, GenAgent decouples these capabilities through an agentic framework: understanding is handled by the multimodal model itself, while generation is achieved by treating image generation models as invokable tools. Crucially, unlike existing modular systems constrained by static pipelines, this design enables autonomous multi-turn interactions where the agent generates multimodal chains-of-thought encompassing reasoning, tool invocation, judgment, and reflection to iteratively refine outputs. We employ a two-stage training strategy: first, cold-start with supervised fine-tuning on high-quality tool invocation and reflection data to bootstrap agent behaviors; second, end-to-end agentic reinforcement learning combining pointwise rewards (final image quality) and pairwise rewards (reflection accuracy), with trajectory resampling for enhanced multi-turn exploration. GenAgent significantly boosts base generator(FLUX.1-dev) performance on GenEval++ (+23.6\%) and WISE (+14\%). Beyond performance gains, our framework demonstrates three key properties: 1) cross-tool generalization to generators with varying capabilities, 2) test-time scaling with consistent improvements across interaction rounds, and 3) task-adaptive reasoning that automatically adjusts to different tasks. Our code will be available at \href{https://github.com/deep-kaixun/GenAgent}{this url}.
ShowTable: Unlocking Creative Table Visualization with Collaborative Reflection and Refinement
Dec 15, 2025While existing generation and unified models excel at general image generation, they struggle with tasks requiring deep reasoning, planning, and precise data-to-visual mapping abilities beyond general scenarios. To push beyond the existing limitations, we introduce a new and challenging task: creative table visualization, requiring the model to generate an infographic that faithfully and aesthetically visualizes the data from a given table. To address this challenge, we propose ShowTable, a pipeline that synergizes MLLMs with diffusion models via a progressive self-correcting process. The MLLM acts as the central orchestrator for reasoning the visual plan and judging visual errors to provide refined instructions, the diffusion execute the commands from MLLM, achieving high-fidelity results. To support this task and our pipeline, we introduce three automated data construction pipelines for training different modules. Furthermore, we introduce TableVisBench, a new benchmark with 800 challenging instances across 5 evaluation dimensions, to assess performance on this task. Experiments demonstrate that our pipeline, instantiated with different models, significantly outperforms baselines, highlighting its effective multi-modal reasoning, generation, and error correction capabilities.
Wan: Open and Advanced Large-Scale Video Generative Models
Mar 26, 2025



This report presents Wan, a comprehensive and open suite of video foundation models designed to push the boundaries of video generation. Built upon the mainstream diffusion transformer paradigm, Wan achieves significant advancements in generative capabilities through a series of innovations, including our novel VAE, scalable pre-training strategies, large-scale data curation, and automated evaluation metrics. These contributions collectively enhance the model's performance and versatility. Specifically, Wan is characterized by four key features: Leading Performance: The 14B model of Wan, trained on a vast dataset comprising billions of images and videos, demonstrates the scaling laws of video generation with respect to both data and model size. It consistently outperforms the existing open-source models as well as state-of-the-art commercial solutions across multiple internal and external benchmarks, demonstrating a clear and significant performance superiority. Comprehensiveness: Wan offers two capable models, i.e., 1.3B and 14B parameters, for efficiency and effectiveness respectively. It also covers multiple downstream applications, including image-to-video, instruction-guided video editing, and personal video generation, encompassing up to eight tasks. Consumer-Grade Efficiency: The 1.3B model demonstrates exceptional resource efficiency, requiring only 8.19 GB VRAM, making it compatible with a wide range of consumer-grade GPUs. Openness: We open-source the entire series of Wan, including source code and all models, with the goal of fostering the growth of the video generation community. This openness seeks to significantly expand the creative possibilities of video production in the industry and provide academia with high-quality video foundation models. All the code and models are available at https://github.com/Wan-Video/Wan2.1.
Hybrid-Level Instruction Injection for Video Token Compression in Multi-modal Large Language Models
Mar 20, 2025Recent Multi-modal Large Language Models (MLLMs) have been challenged by the computational overhead resulting from massive video frames, often alleviated through compression strategies. However, the visual content is not equally contributed to user instructions, existing strategies (\eg, average pool) inevitably lead to the loss of potentially useful information. To tackle this, we propose the Hybrid-level Instruction Injection Strategy for Conditional Token Compression in MLLMs (HICom), utilizing the instruction as a condition to guide the compression from both local and global levels. This encourages the compression to retain the maximum amount of user-focused information while reducing visual tokens to minimize computational burden. Specifically, the instruction condition is injected into the grouped visual tokens at the local level and the learnable tokens at the global level, and we conduct the attention mechanism to complete the conditional compression. From the hybrid-level compression, the instruction-relevant visual parts are highlighted while the temporal-spatial structure is also preserved for easier understanding of LLMs. To further unleash the potential of HICom, we introduce a new conditional pre-training stage with our proposed dataset HICom-248K. Experiments show that our HICom can obtain distinguished video understanding ability with fewer tokens, increasing the performance by 2.43\% average on three multiple-choice QA benchmarks and saving 78.8\% tokens compared with the SOTA method. The code is available at https://github.com/lntzm/HICom.
Rethinking Video Tokenization: A Conditioned Diffusion-based Approach
Mar 05, 2025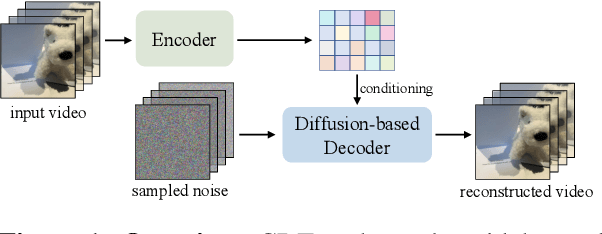
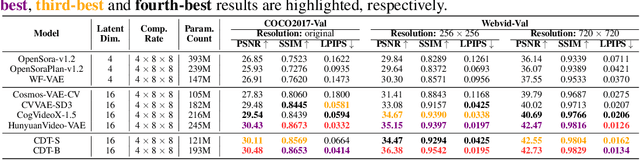
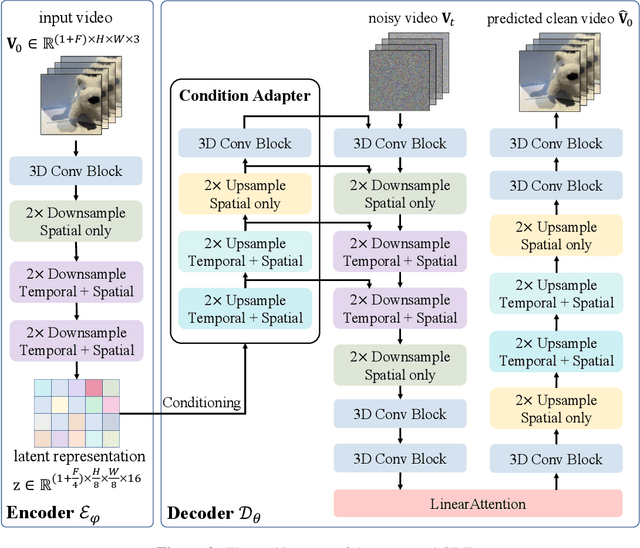
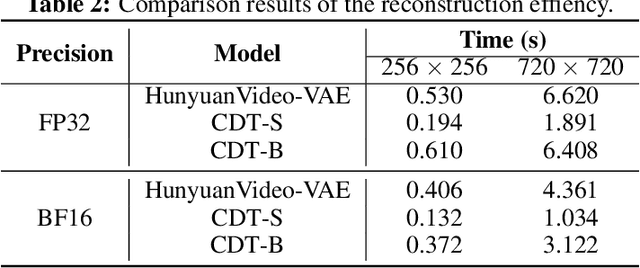
Video tokenizers, which transform videos into compact latent representations, are key to video generation. Existing video tokenizers are based on the VAE architecture and follow a paradigm where an encoder compresses videos into compact latents, and a deterministic decoder reconstructs the original videos from these latents. In this paper, we propose a novel \underline{\textbf{C}}onditioned \underline{\textbf{D}}iffusion-based video \underline{\textbf{T}}okenizer entitled \textbf{\ourmethod}, which departs from previous methods by replacing the deterministic decoder with a 3D causal diffusion model. The reverse diffusion generative process of the decoder is conditioned on the latent representations derived via the encoder. With a feature caching and sampling acceleration, the framework efficiently reconstructs high-fidelity videos of arbitrary lengths. Results show that {\ourmethod} achieves state-of-the-art performance in video reconstruction tasks using just a single-step sampling. Even a smaller version of {\ourmethod} still achieves reconstruction results on par with the top two baselines. Furthermore, the latent video generation model trained using {\ourmethod} also shows superior performance.
UFO: A Unified Approach to Fine-grained Visual Perception via Open-ended Language Interface
Mar 04, 2025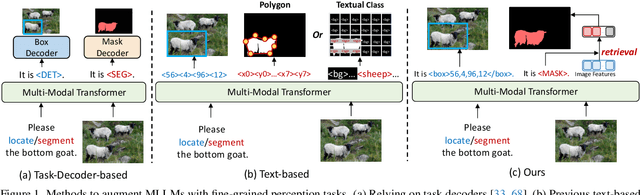
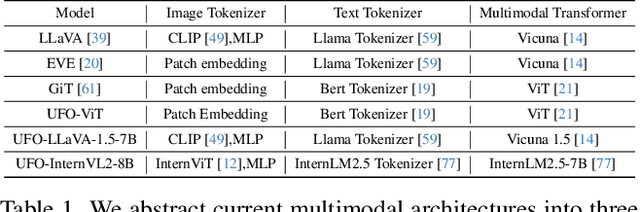
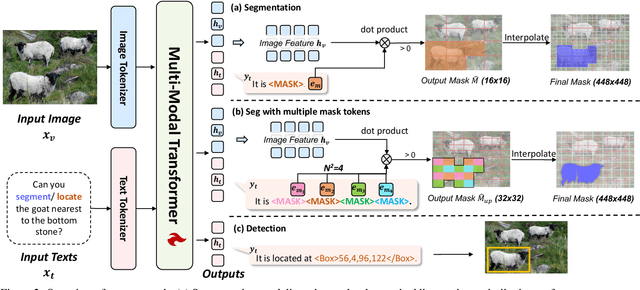
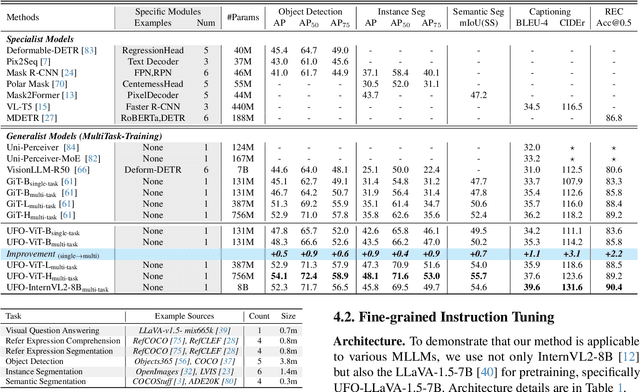
Generalist models have achieved remarkable success in both language and vision-language tasks, showcasing the potential of unified modeling. However, effectively integrating fine-grained perception tasks like detection and segmentation into these models remains a significant challenge. This is primarily because these tasks often rely heavily on task-specific designs and architectures that can complicate the modeling process. To address this challenge, we present \ours, a framework that \textbf{U}nifies \textbf{F}ine-grained visual perception tasks through an \textbf{O}pen-ended language interface. By transforming all perception targets into the language space, \ours unifies object-level detection, pixel-level segmentation, and image-level vision-language tasks into a single model. Additionally, we introduce a novel embedding retrieval approach that relies solely on the language interface to support segmentation tasks. Our framework bridges the gap between fine-grained perception and vision-language tasks, significantly simplifying architectural design and training strategies while achieving comparable or superior performance to methods with intricate task-specific designs. After multi-task training on five standard visual perception datasets, \ours outperforms the previous state-of-the-art generalist models by 12.3 mAP on COCO instance segmentation and 3.3 mIoU on ADE20K semantic segmentation. Furthermore, our method seamlessly integrates with existing MLLMs, effectively combining fine-grained perception capabilities with their advanced language abilities, thereby enabling more challenging tasks such as reasoning segmentation. Code and models are available at https://github.com/nnnth/UFO.
What Is a Good Caption? A Comprehensive Visual Caption Benchmark for Evaluating Both Correctness and Coverage of MLLMs
Feb 19, 2025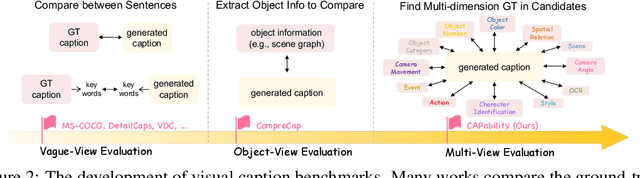
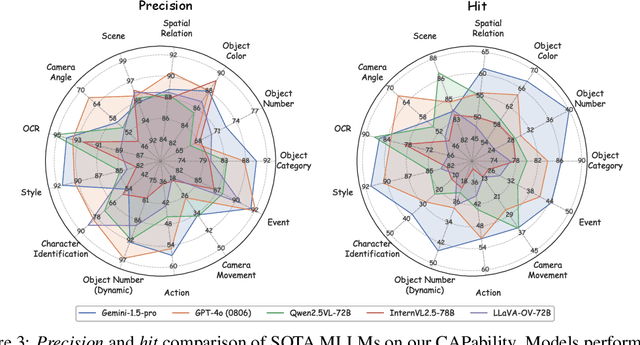


Recent advancements in Multimodal Large Language Models (MLLMs) have rendered traditional visual captioning benchmarks obsolete, as they primarily evaluate short descriptions with outdated metrics. While recent benchmarks address these limitations by decomposing captions into visual elements and adopting model-based evaluation, they remain incomplete-overlooking critical aspects, while providing vague, non-explanatory scores. To bridge this gap, we propose CV-CapBench, a Comprehensive Visual Caption Benchmark that systematically evaluates caption quality across 6 views and 13 dimensions. CV-CapBench introduces precision, recall, and hit rate metrics for each dimension, uniquely assessing both correctness and coverage. Experiments on leading MLLMs reveal significant capability gaps, particularly in dynamic and knowledge-intensive dimensions. These findings provide actionable insights for future research. The code and data will be released.
AlignZeg: Mitigating Objective Misalignment for Zero-shot Semantic Segmentation
Apr 08, 2024A serious issue that harms the performance of zero-shot visual recognition is named objective misalignment, i.e., the learning objective prioritizes improving the recognition accuracy of seen classes rather than unseen classes, while the latter is the true target to pursue. This issue becomes more significant in zero-shot image segmentation because the stronger (i.e., pixel-level) supervision brings a larger gap between seen and unseen classes. To mitigate it, we propose a novel architecture named AlignZeg, which embodies a comprehensive improvement of the segmentation pipeline, including proposal extraction, classification, and correction, to better fit the goal of zero-shot segmentation. (1) Mutually-Refined Proposal Extraction. AlignZeg harnesses a mutual interaction between mask queries and visual features, facilitating detailed class-agnostic mask proposal extraction. (2) Generalization-Enhanced Proposal Classification. AlignZeg introduces synthetic data and incorporates multiple background prototypes to allocate a more generalizable feature space. (3) Predictive Bias Correction. During the inference stage, AlignZeg uses a class indicator to find potential unseen class proposals followed by a prediction postprocess to correct the prediction bias. Experiments demonstrate that AlignZeg markedly enhances zero-shot semantic segmentation, as shown by an average 3.8% increase in hIoU, primarily attributed to a 7.1% improvement in identifying unseen classes, and we further validate that the improvement comes from alleviating the objective misalignment issue.
Towards Balanced Alignment: Modal-Enhanced Semantic Modeling for Video Moment Retrieval
Dec 19, 2023



Video Moment Retrieval (VMR) aims to retrieve temporal segments in untrimmed videos corresponding to a given language query by constructing cross-modal alignment strategies. However, these existing strategies are often sub-optimal since they ignore the modality imbalance problem, \textit{i.e.}, the semantic richness inherent in videos far exceeds that of a given limited-length sentence. Therefore, in pursuit of better alignment, a natural idea is enhancing the video modality to filter out query-irrelevant semantics, and enhancing the text modality to capture more segment-relevant knowledge. In this paper, we introduce Modal-Enhanced Semantic Modeling (MESM), a novel framework for more balanced alignment through enhancing features at two levels. First, we enhance the video modality at the frame-word level through word reconstruction. This strategy emphasizes the portions associated with query words in frame-level features while suppressing irrelevant parts. Therefore, the enhanced video contains less redundant semantics and is more balanced with the textual modality. Second, we enhance the textual modality at the segment-sentence level by learning complementary knowledge from context sentences and ground-truth segments. With the knowledge added to the query, the textual modality thus maintains more meaningful semantics and is more balanced with the video modality. By implementing two levels of MESM, the semantic information from both modalities is more balanced to align, thereby bridging the modality gap. Experiments on three widely used benchmarks, including the out-of-distribution settings, show that the proposed framework achieves a new start-of-the-art performance with notable generalization ability (e.g., 4.42% and 7.69% average gains of R1@0.7 on Charades-STA and Charades-CG). The code will be available at https://github.com/lntzm/MESM.