 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTessera: Unlocking Heterogeneous GPUs through Kernel-Granularity Disaggregation
Apr 11, 2026Disaggregation maps parts of an AI workload to different types of GPUs, offering a path to utilize modern heterogeneous GPU clusters. However, existing solutions operate at a coarse granularity and are tightly coupled to specific model architectures, leaving much room for performance improvement. This paper presents Tessera, the first kernel disaggregation system to improve performance and cost efficiency on heterogeneous GPUs for large model inference. Our key insight is that kernels within a single application exhibit diverse resource demands, making them the most suitable granularity for aligning computation with hardware capabilities. Tessera integrates offline analysis with online adaptation by extracting precise inter-kernel dependencies from PTX to ensure correctness, overlapping communication with computation through a pipelined execution model, and employing workload-aware scheduling with lightweight runtime adaptation. Extensive evaluations across five heterogeneous GPUs and four model architectures, scaling up to 16 GPUs, show that Tessera improves serving throughput and cost efficiency by up to 2.3x and 1.6x, respectively, compared to existing disaggregation methods, while generalizing to model architectures where prior approaches do not apply. Surprisingly, a heterogeneous GPU pair under Tessera can even exceed the throughput of two homogeneous high-end GPUs at a lower cost.
AIBench: Evaluating Visual-Logical Consistency in Academic Illustration Generation
Mar 31, 2026Although image generation has boosted various applications via its rapid evolution, whether the state-of-the-art models are able to produce ready-to-use academic illustrations for papers is still largely unexplored. Directly comparing or evaluating the illustration with VLM is native but requires oracle multi-modal understanding ability, which is unreliable for long and complex texts and illustrations. To address this, we propose AIBench, the first benchmark using VQA for evaluating logic correctness of the academic illustrations and VLMs for assessing aesthetics. In detail, we designed four levels of questions proposed from a logic diagram summarized from the method part of the paper, which query whether the generated illustration aligns with the paper on different scales. Our VQA-based approach raises more accurate and detailed evaluations on visual-logical consistency while relying less on the ability of the judger VLM. With our high-quality AIBench, we conduct extensive experiments and conclude that the performance gap between models on this task is significantly larger than general ones, reflecting their various complex reasoning and high-density generation ability. Further, the logic and aesthetics are hard to optimize simultaneously as in handcrafted illustrations. Additional experiments further state that test-time scaling on both abilities significantly boosts the performance on this task.
GenAgent: Scaling Text-to-Image Generation via Agentic Multimodal Reasoning
Jan 26, 2026We introduce GenAgent, unifying visual understanding and generation through an agentic multimodal model. Unlike unified models that face expensive training costs and understanding-generation trade-offs, GenAgent decouples these capabilities through an agentic framework: understanding is handled by the multimodal model itself, while generation is achieved by treating image generation models as invokable tools. Crucially, unlike existing modular systems constrained by static pipelines, this design enables autonomous multi-turn interactions where the agent generates multimodal chains-of-thought encompassing reasoning, tool invocation, judgment, and reflection to iteratively refine outputs. We employ a two-stage training strategy: first, cold-start with supervised fine-tuning on high-quality tool invocation and reflection data to bootstrap agent behaviors; second, end-to-end agentic reinforcement learning combining pointwise rewards (final image quality) and pairwise rewards (reflection accuracy), with trajectory resampling for enhanced multi-turn exploration. GenAgent significantly boosts base generator(FLUX.1-dev) performance on GenEval++ (+23.6\%) and WISE (+14\%). Beyond performance gains, our framework demonstrates three key properties: 1) cross-tool generalization to generators with varying capabilities, 2) test-time scaling with consistent improvements across interaction rounds, and 3) task-adaptive reasoning that automatically adjusts to different tasks. Our code will be available at \href{https://github.com/deep-kaixun/GenAgent}{this url}.
MMARD: Improving the Min-Max Optimization Process in Adversarial Robustness Distillation
Mar 09, 2025Adversarial Robustness Distillation (ARD) is a promising task to boost the robustness of small-capacity models with the guidance of the pre-trained robust teacher. The ARD can be summarized as a min-max optimization process, i.e., synthesizing adversarial examples (inner) & training the student (outer). Although competitive robustness performance, existing ARD methods still have issues. In the inner process, the synthetic training examples are far from the teacher's decision boundary leading to important robust information missing. In the outer process, the student model is decoupled from learning natural and robust scenarios, leading to the robustness saturation, i.e., student performance is highly susceptible to customized teacher selection. To tackle these issues, this paper proposes a general Min-Max optimization Adversarial Robustness Distillation (MMARD) method. For the inner process, we introduce the teacher's robust predictions, which drive the training examples closer to the teacher's decision boundary to explore more robust knowledge. For the outer process, we propose a structured information modeling method based on triangular relationships to measure the mutual information of the model in natural and robust scenarios and enhance the model's ability to understand multi-scenario mapping relationships. Experiments show our MMARD achieves state-of-the-art performance on multiple benchmarks. Besides, MMARD is plug-and-play and convenient to combine with existing methods.
Towards Context-Aware Emotion Recognition Debiasing from a Causal Demystification Perspective via De-confounded Training
Jul 06, 2024
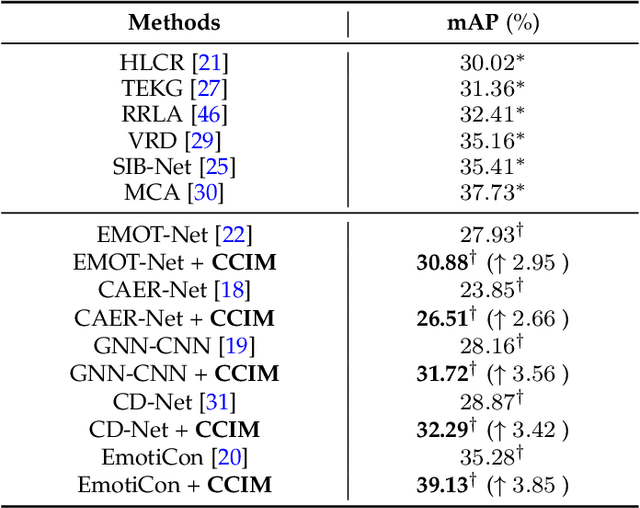
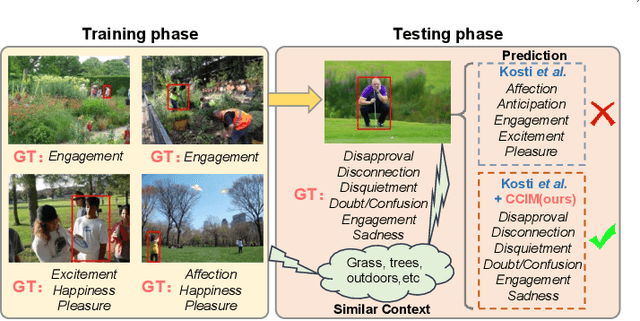
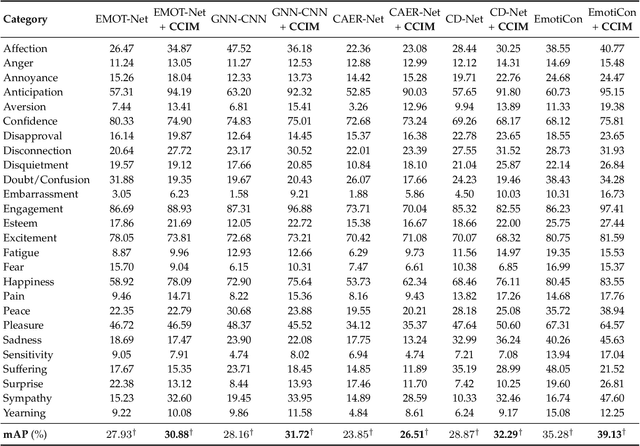
Understanding emotions from diverse contexts has received widespread attention in computer vision communities. The core philosophy of Context-Aware Emotion Recognition (CAER) is to provide valuable semantic cues for recognizing the emotions of target persons by leveraging rich contextual information. Current approaches invariably focus on designing sophisticated structures to extract perceptually critical representations from contexts. Nevertheless, a long-neglected dilemma is that a severe context bias in existing datasets results in an unbalanced distribution of emotional states among different contexts, causing biased visual representation learning. From a causal demystification perspective, the harmful bias is identified as a confounder that misleads existing models to learn spurious correlations based on likelihood estimation, limiting the models' performance. To address the issue, we embrace causal inference to disentangle the models from the impact of such bias, and formulate the causalities among variables in the CAER task via a customized causal graph. Subsequently, we present a Contextual Causal Intervention Module (CCIM) to de-confound the confounder, which is built upon backdoor adjustment theory to facilitate seeking approximate causal effects during model training. As a plug-and-play component, CCIM can easily integrate with existing approaches and bring significant improvements. Systematic experiments on three datasets demonstrate the effectiveness of our CCIM.
Self-Cooperation Knowledge Distillation for Novel Class Discovery
Jul 02, 2024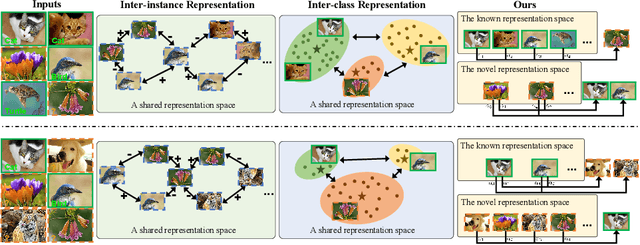

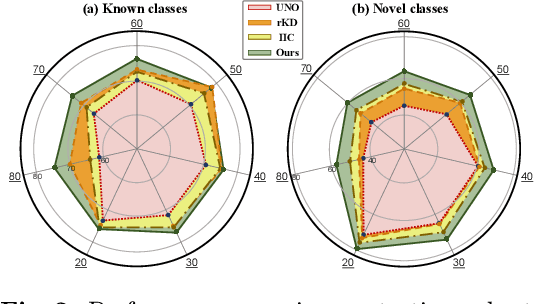
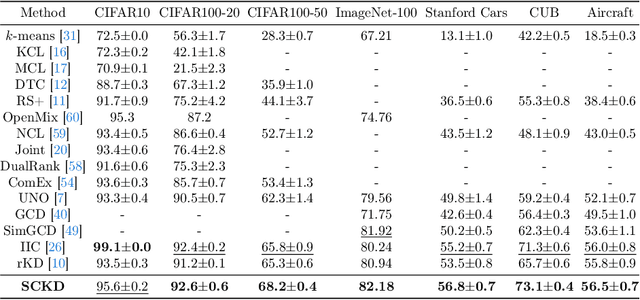
Novel Class Discovery (NCD) aims to discover unknown and novel classes in an unlabeled set by leveraging knowledge already learned about known classes. Existing works focus on instance-level or class-level knowledge representation and build a shared representation space to achieve performance improvements. However, a long-neglected issue is the potential imbalanced number of samples from known and novel classes, pushing the model towards dominant classes. Therefore, these methods suffer from a challenging trade-off between reviewing known classes and discovering novel classes. Based on this observation, we propose a Self-Cooperation Knowledge Distillation (SCKD) method to utilize each training sample (whether known or novel, labeled or unlabeled) for both review and discovery. Specifically, the model's feature representations of known and novel classes are used to construct two disjoint representation spaces. Through spatial mutual information, we design a self-cooperation learning to encourage model learning from the two feature representation spaces from itself. Extensive experiments on six datasets demonstrate that our method can achieve significant performance improvements, achieving state-of-the-art performance.
De-confounded Data-free Knowledge Distillation for Handling Distribution Shifts
Mar 28, 2024



Data-Free Knowledge Distillation (DFKD) is a promising task to train high-performance small models to enhance actual deployment without relying on the original training data. Existing methods commonly avoid relying on private data by utilizing synthetic or sampled data. However, a long-overlooked issue is that the severe distribution shifts between their substitution and original data, which manifests as huge differences in the quality of images and class proportions. The harmful shifts are essentially the confounder that significantly causes performance bottlenecks. To tackle the issue, this paper proposes a novel perspective with causal inference to disentangle the student models from the impact of such shifts. By designing a customized causal graph, we first reveal the causalities among the variables in the DFKD task. Subsequently, we propose a Knowledge Distillation Causal Intervention (KDCI) framework based on the backdoor adjustment to de-confound the confounder. KDCI can be flexibly combined with most existing state-of-the-art baselines. Experiments in combination with six representative DFKD methods demonstrate the effectiveness of our KDCI, which can obviously help existing methods under almost all settings, \textit{e.g.}, improving the baseline by up to 15.54\% accuracy on the CIFAR-100 dataset.
Towards Multimodal Human Intention Understanding Debiasing via Subject-Deconfounding
Mar 08, 2024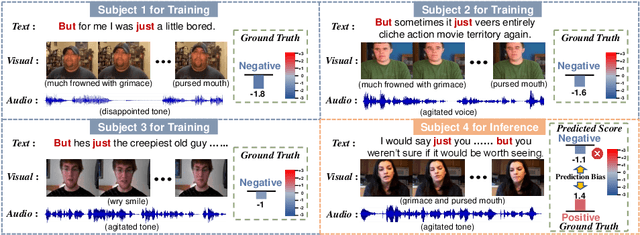
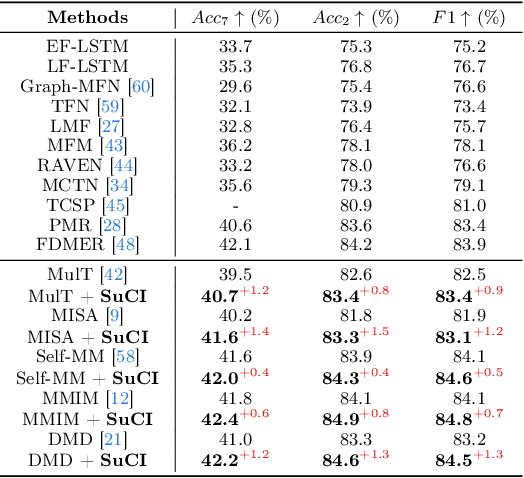
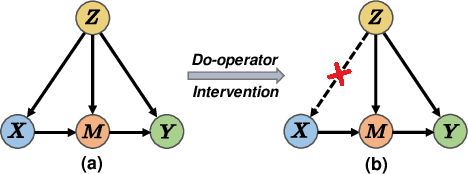
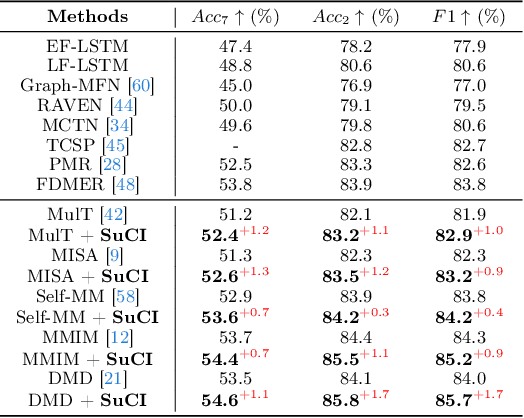
Multimodal intention understanding (MIU) is an indispensable component of human expression analysis (e.g., sentiment or humor) from heterogeneous modalities, including visual postures, linguistic contents, and acoustic behaviors. Existing works invariably focus on designing sophisticated structures or fusion strategies to achieve impressive improvements. Unfortunately, they all suffer from the subject variation problem due to data distribution discrepancies among subjects. Concretely, MIU models are easily misled by distinct subjects with different expression customs and characteristics in the training data to learn subject-specific spurious correlations, significantly limiting performance and generalizability across uninitiated subjects.Motivated by this observation, we introduce a recapitulative causal graph to formulate the MIU procedure and analyze the confounding effect of subjects. Then, we propose SuCI, a simple yet effective causal intervention module to disentangle the impact of subjects acting as unobserved confounders and achieve model training via true causal effects. As a plug-and-play component, SuCI can be widely applied to most methods that seek unbiased predictions. Comprehensive experiments on several MIU benchmarks clearly demonstrate the effectiveness of the proposed module.
Towards Multimodal Sentiment Analysis Debiasing via Bias Purification
Mar 08, 2024Multimodal Sentiment Analysis (MSA) aims to understand human intentions by integrating emotion-related clues from diverse modalities, such as visual, language, and audio. Unfortunately, the current MSA task invariably suffers from unplanned dataset biases, particularly multimodal utterance-level label bias and word-level context bias. These harmful biases potentially mislead models to focus on statistical shortcuts and spurious correlations, causing severe performance bottlenecks. To alleviate these issues, we present a Multimodal Counterfactual Inference Sentiment (MCIS) analysis framework based on causality rather than conventional likelihood. Concretely, we first formulate a causal graph to discover harmful biases from already-trained vanilla models. In the inference phase, given a factual multimodal input, MCIS imagines two counterfactual scenarios to purify and mitigate these biases. Then, MCIS can make unbiased decisions from biased observations by comparing factual and counterfactual outcomes. We conduct extensive experiments on several standard MSA benchmarks. Qualitative and quantitative results show the effectiveness of the proposed framework.
Improving Generalization in Visual Reinforcement Learning via Conflict-aware Gradient Agreement Augmentation
Aug 02, 2023



Learning a policy with great generalization to unseen environments remains challenging but critical in visual reinforcement learning. Despite the success of augmentation combination in the supervised learning generalization, naively applying it to visual RL algorithms may damage the training efficiency, suffering from serve performance degradation. In this paper, we first conduct qualitative analysis and illuminate the main causes: (i) high-variance gradient magnitudes and (ii) gradient conflicts existed in various augmentation methods. To alleviate these issues, we propose a general policy gradient optimization framework, named Conflict-aware Gradient Agreement Augmentation (CG2A), and better integrate augmentation combination into visual RL algorithms to address the generalization bias. In particular, CG2A develops a Gradient Agreement Solver to adaptively balance the varying gradient magnitudes, and introduces a Soft Gradient Surgery strategy to alleviate the gradient conflicts. Extensive experiments demonstrate that CG2A significantly improves the generalization performance and sample efficiency of visual RL algorithms.