 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaster Diffusion Action Segmentation
Aug 04, 2024
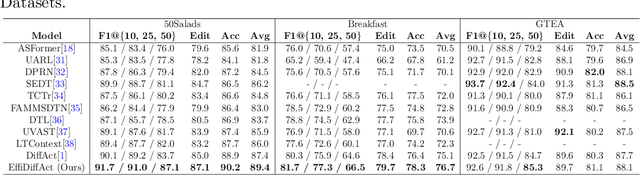
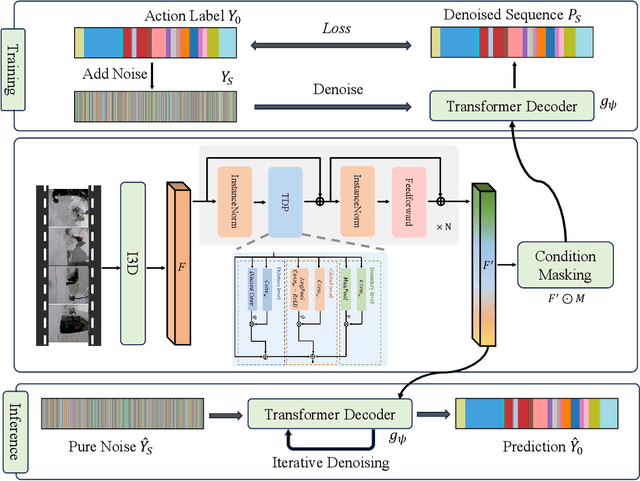

Temporal Action Segmentation (TAS) is an essential task in video analysis, aiming to segment and classify continuous frames into distinct action segments. However, the ambiguous boundaries between actions pose a significant challenge for high-precision segmentation. Recent advances in diffusion models have demonstrated substantial success in TAS tasks due to their stable training process and high-quality generation capabilities. However, the heavy sampling steps required by diffusion models pose a substantial computational burden, limiting their practicality in real-time applications. Additionally, most related works utilize Transformer-based encoder architectures. Although these architectures excel at capturing long-range dependencies, they incur high computational costs and face feature-smoothing issues when processing long video sequences. To address these challenges, we propose EffiDiffAct, an efficient and high-performance TAS algorithm. Specifically, we develop a lightweight temporal feature encoder that reduces computational overhead and mitigates the rank collapse phenomenon associated with traditional self-attention mechanisms. Furthermore, we introduce an adaptive skip strategy that allows for dynamic adjustment of timestep lengths based on computed similarity metrics during inference, thereby further enhancing computational efficiency. Comprehensive experiments on the 50Salads, Breakfast, and GTEA datasets demonstrated the effectiveness of the proposed algorithm.
Towards Context-Aware Emotion Recognition Debiasing from a Causal Demystification Perspective via De-confounded Training
Jul 06, 2024
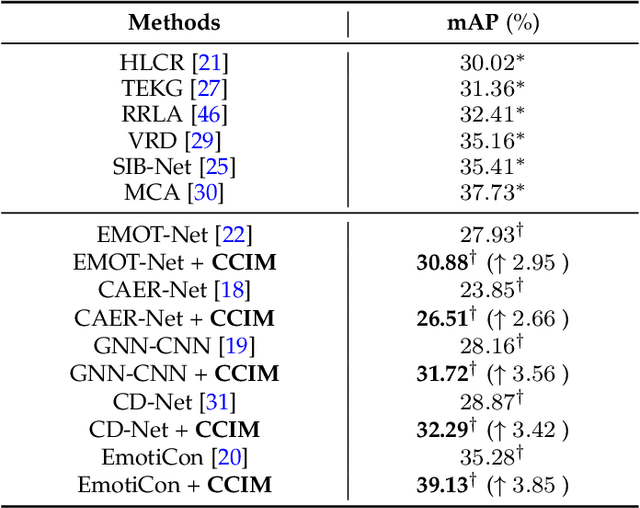
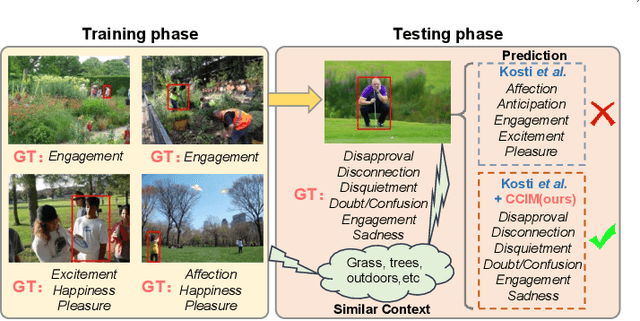
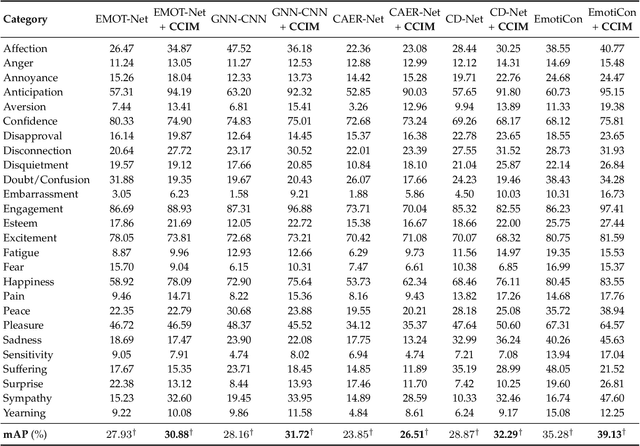
Understanding emotions from diverse contexts has received widespread attention in computer vision communities. The core philosophy of Context-Aware Emotion Recognition (CAER) is to provide valuable semantic cues for recognizing the emotions of target persons by leveraging rich contextual information. Current approaches invariably focus on designing sophisticated structures to extract perceptually critical representations from contexts. Nevertheless, a long-neglected dilemma is that a severe context bias in existing datasets results in an unbalanced distribution of emotional states among different contexts, causing biased visual representation learning. From a causal demystification perspective, the harmful bias is identified as a confounder that misleads existing models to learn spurious correlations based on likelihood estimation, limiting the models' performance. To address the issue, we embrace causal inference to disentangle the models from the impact of such bias, and formulate the causalities among variables in the CAER task via a customized causal graph. Subsequently, we present a Contextual Causal Intervention Module (CCIM) to de-confound the confounder, which is built upon backdoor adjustment theory to facilitate seeking approximate causal effects during model training. As a plug-and-play component, CCIM can easily integrate with existing approaches and bring significant improvements. Systematic experiments on three datasets demonstrate the effectiveness of our CCIM.
Multi-Scale Heterogeneity-Aware Hypergraph Representation for Histopathology Whole Slide Images
Apr 30, 2024Survival prediction is a complex ordinal regression task that aims to predict the survival coefficient ranking among a cohort of patients, typically achieved by analyzing patients' whole slide images. Existing deep learning approaches mainly adopt multiple instance learning or graph neural networks under weak supervision. Most of them are unable to uncover the diverse interactions between different types of biological entities(\textit{e.g.}, cell cluster and tissue block) across multiple scales, while such interactions are crucial for patient survival prediction. In light of this, we propose a novel multi-scale heterogeneity-aware hypergraph representation framework. Specifically, our framework first constructs a multi-scale heterogeneity-aware hypergraph and assigns each node with its biological entity type. It then mines diverse interactions between nodes on the graph structure to obtain a global representation. Experimental results demonstrate that our method outperforms state-of-the-art approaches on three benchmark datasets. Code is publicly available at \href{https://github.com/Hanminghao/H2GT}{https://github.com/Hanminghao/H2GT}.
CPR-Coach: Recognizing Composite Error Actions based on Single-class Training
Sep 21, 2023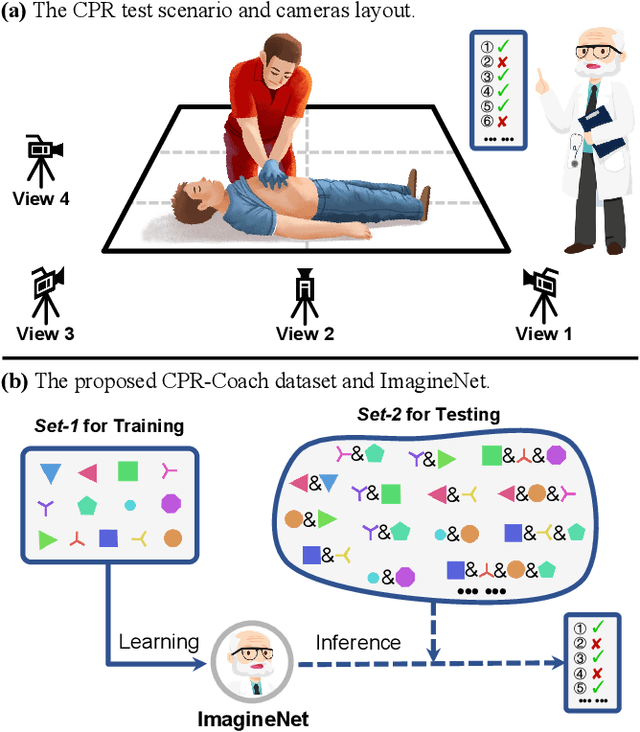
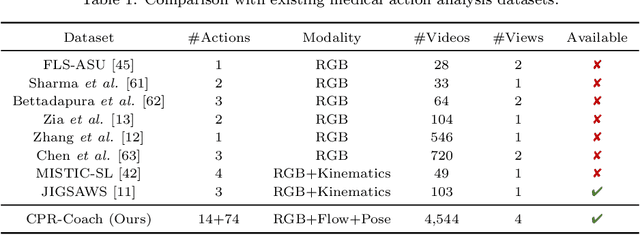

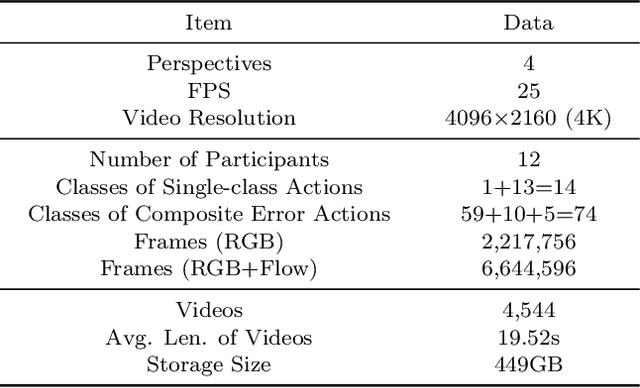
The fine-grained medical action analysis task has received considerable attention from pattern recognition communities recently, but it faces the problems of data and algorithm shortage. Cardiopulmonary Resuscitation (CPR) is an essential skill in emergency treatment. Currently, the assessment of CPR skills mainly depends on dummies and trainers, leading to high training costs and low efficiency. For the first time, this paper constructs a vision-based system to complete error action recognition and skill assessment in CPR. Specifically, we define 13 types of single-error actions and 74 types of composite error actions during external cardiac compression and then develop a video dataset named CPR-Coach. By taking the CPR-Coach as a benchmark, this paper thoroughly investigates and compares the performance of existing action recognition models based on different data modalities. To solve the unavoidable Single-class Training & Multi-class Testing problem, we propose a humancognition-inspired framework named ImagineNet to improve the model's multierror recognition performance under restricted supervision. Extensive experiments verify the effectiveness of the framework. We hope this work could advance research toward fine-grained medical action analysis and skill assessment. The CPR-Coach dataset and the code of ImagineNet are publicly available on Github.
Towards Simultaneous Segmentation of Liver Tumors and Intrahepatic Vessels via Cross-attention Mechanism
Feb 20, 2023Accurate visualization of liver tumors and their surrounding blood vessels is essential for noninvasive diagnosis and prognosis prediction of tumors. In medical image segmentation, there is still a lack of in-depth research on the simultaneous segmentation of liver tumors and peritumoral blood vessels. To this end, we collect the first liver tumor, and vessel segmentation benchmark datasets containing 52 portal vein phase computed tomography images with liver, liver tumor, and vessel annotations. In this case, we propose a 3D U-shaped Cross-Attention Network (UCA-Net) that utilizes a tailored cross-attention mechanism instead of the traditional skip connection to effectively model the encoder and decoder feature. Specifically, the UCA-Net uses a channel-wise cross-attention module to reduce the semantic gap between encoder and decoder and a slice-wise cross-attention module to enhance the contextual semantic learning ability among distinct slices. Experimental results show that the proposed UCA-Net can accurately segment 3D medical images and achieve state-of-the-art performance on the liver tumor and intrahepatic vessel segmentation task.