 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIM-Bench: Benchmarking and Improving Affective Image Manipulation via Fine-Grained Hierarchical Control
Apr 12, 2026Affective Image Manipulation (AIM) aims to evoke specific emotions through targeted editing. Current image editing benchmarks primarily focus on object-level modifications in general scenarios, lacking the fine-grained granularity to capture affective dimensions. To bridge this gap, we introduce the first benchmark designed for AIM termed AIM-Bench. This benchmark is built upon a dual-path affective modeling scheme that integrates the Mikels emotion taxonomy with the Valence-Arousal-Dominance framework, enabling high-level semantic and fine-grained continuous manipulation. Through a hierarchical human-in-the-loop workflow, we finally curate 800 high-quality samples covering 8 emotional categories and 5 editing types. To effectively assess performance, we also design a composite evaluation suite combining rule-based and model-based metrics to holistically assess instruction consistency, aesthetics, and emotional expressiveness. Extensive evaluations reveal that current editing models face significant challenges, most notably a prevalent positivity bias, which stemming from inherent imbalances in training data distribution. To tackle this, we propose a scalable data engine utilizing an inverse repainting strategy to construct AIM-40k, a balanced instruction-tuning dataset comprising 40k samples. Concretely, we enhance raw affective images via generative redrawing to establish high-fidelity ground truths, and synthesize input images with divergent emotions and paired precise instructions. Fine-tuning a baseline model on AIM-40k yields a 9.15% relative improvement in overall performance, demonstrating the effectiveness of our AIM-40k. Our data and related code will be made open soon.
FED-Bench: A Cross-Granular Benchmark for Disentangled Evaluation of Facial Expression Editing
Mar 31, 2026Facial expression image editing requires fine-grained control to strictly preserve human identity and background while precisely manipulating expression. However, existing editing benchmarks primarily focus on general scenarios, lacking high-quality facial images and corresponding editing instructions. Furthermore, current evaluation metrics exhibit systemic biases in this task, often favoring lazy editing or overfit editing. To bridge these gaps, we propose FED-Bench, a comprehensive benchmark featuring rigorous testing and an accurate evaluation suite. First, we carefully construct a benchmark of 747 triplets through a cascaded and scalable pipeline, each comprising an original image, an editing instruction, and a ground-truth image for precise evaluation. Second, we introduce FED-Score, a cross-granularity evaluation protocol that disentangles assessment into three dimensions: Alignment for verifying instruction following, Fidelity for testing image quality and identity preservation, and Relative Expression Gain for quantifying the magnitude of expression changes, effectively mitigating the aforementioned evaluation biases. Third, we benchmark 18 image editing models, revealing that current approaches struggle to simultaneously achieve high fidelity and accurate expression manipulation, with fine-grained instruction following identified as the primary bottleneck. Finally, leveraging the scalable characteristic of introduced benchmark engine, we provide a 20k+ in-the-wild facial training set and demonstrate its effectiveness by fine-tuning a baseline model that achieves significant performance gains. Our benchmark and related code will be made publicly open soon.
Project Imaging-X: A Survey of 1000+ Open-Access Medical Imaging Datasets for Foundation Model Development
Mar 29, 2026Foundation models have demonstrated remarkable success across diverse domains and tasks, primarily due to the thrive of large-scale, diverse, and high-quality datasets. However, in the field of medical imaging, the curation and assembling of such medical datasets are highly challenging due to the reliance on clinical expertise and strict ethical and privacy constraints, resulting in a scarcity of large-scale unified medical datasets and hindering the development of powerful medical foundation models. In this work, we present the largest survey to date of medical image datasets, covering over 1,000 open-access datasets with a systematic catalog of their modalities, tasks, anatomies, annotations, limitations, and potential for integration. Our analysis exposes a landscape that is modest in scale, fragmented across narrowly scoped tasks, and unevenly distributed across organs and modalities, which in turn limits the utility of existing medical image datasets for developing versatile and robust medical foundation models. To turn fragmentation into scale, we propose a metadata-driven fusion paradigm (MDFP) that integrates public datasets with shared modalities or tasks, thereby transforming multiple small data silos into larger, more coherent resources. Building on MDFP, we release an interactive discovery portal that enables end-to-end, automated medical image dataset integration, and compile all surveyed datasets into a unified, structured table that clearly summarizes their key characteristics and provides reference links, offering the community an accessible and comprehensive repository. By charting the current terrain and offering a principled path to dataset consolidation, our survey provides a practical roadmap for scaling medical imaging corpora, supporting faster data discovery, more principled dataset creation, and more capable medical foundation models.
Diffusion Probe: Generated Image Result Prediction Using CNN Probes
Mar 05, 2026Text-to-image (T2I) diffusion models lack an efficient mechanism for early quality assessment, leading to costly trial-and-error in multi-generation scenarios such as prompt iteration, agent-based generation, and flow-grpo. We reveal a strong correlation between early diffusion cross-attention distributions and final image quality. Based on this finding, we introduce Diffusion Probe, a framework that leverages internal cross-attention maps as predictive signals. We design a lightweight predictor that maps statistical properties of early-stage cross-attention extracted from initial denoising steps to the final image's overall quality. This enables accurate forecasting of image quality across diverse evaluation metrics long before full synthesis is complete. We validate Diffusion Probe across a wide range of settings. On multiple T2I models, across early denoising windows, resolutions, and quality metrics, it achieves strong correlation (PCC > 0.7) and high classification performance (AUC-ROC > 0.9). Its reliability translates into practical gains. By enabling early quality-aware decisions in workflows such as prompt optimization, seed selection, and accelerated RL training, the probe supports more targeted sampling and avoids computation on low-potential generations. This reduces computational overhead while improving final output quality.Diffusion Probe is model-agnostic, efficient, and broadly applicable, offering a practical solution for improving T2I generation efficiency through early quality prediction.
TextPecker: Rewarding Structural Anomaly Quantification for Enhancing Visual Text Rendering
Feb 26, 2026Visual Text Rendering (VTR) remains a critical challenge in text-to-image generation, where even advanced models frequently produce text with structural anomalies such as distortion, blurriness, and misalignment. However, we find that leading MLLMs and specialist OCR models largely fail to perceive these structural anomalies, creating a critical bottleneck for both VTR evaluation and RL-based optimization. As a result, even state-of-the-art generators (e.g., Seedream4.0, Qwen-Image) still struggle to render structurally faithful text. To address this, we propose TextPecker, a plug-and-play structural anomaly perceptive RL strategy that mitigates noisy reward signals and works with any textto-image generator. To enable this capability, we construct a recognition dataset with character-level structural-anomaly annotations and develop a stroke-editing synthesis engine to expand structural-error coverage. Experiments show that TextPecker consistently improves diverse text-to-image models; even on the well-optimized Qwen-Image, it significantly yields average gains of 4% in structural fidelity and 8.7% in semantic alignment for Chinese text rendering, establishing a new state-of-the-art in high-fidelity VTR. Our work fills a gap in VTR optimization, providing a foundational step towards reliable and structural faithful visual text generation.
Fusing Pixels and Genes: Spatially-Aware Learning in Computational Pathology
Feb 15, 2026Recent years have witnessed remarkable progress in multimodal learning within computational pathology. Existing models primarily rely on vision and language modalities; however, language alone lacks molecular specificity and offers limited pathological supervision, leading to representational bottlenecks. In this paper, we propose STAMP, a Spatial Transcriptomics-Augmented Multimodal Pathology representation learning framework that integrates spatially-resolved gene expression profiles to enable molecule-guided joint embedding of pathology images and transcriptomic data. Our study shows that self-supervised, gene-guided training provides a robust and task-agnostic signal for learning pathology image representations. Incorporating spatial context and multi-scale information further enhances model performance and generalizability. To support this, we constructed SpaVis-6M, the largest Visium-based spatial transcriptomics dataset to date, and trained a spatially-aware gene encoder on this resource. Leveraging hierarchical multi-scale contrastive alignment and cross-scale patch localization mechanisms, STAMP effectively aligns spatial transcriptomics with pathology images, capturing spatial structure and molecular variation. We validate STAMP across six datasets and four downstream tasks, where it consistently achieves strong performance. These results highlight the value and necessity of integrating spatially resolved molecular supervision for advancing multimodal learning in computational pathology. The code is included in the supplementary materials. The pretrained weights and SpaVis-6M are available at: https://github.com/Hanminghao/STAMP.
Exploring Physical Intelligence Emergence via Omni-Modal Architecture and Physical Data Engine
Feb 05, 2026Physical understanding remains brittle in omni-modal models because key physical attributes are visually ambiguous and sparsely represented in web-scale data. We present OmniFysics, a compact omni-modal model that unifies understanding across images, audio, video, and text, with integrated speech and image generation. To inject explicit physical knowledge, we build a physical data engine with two components. FysicsAny produces physics-grounded instruction--image supervision by mapping salient objects to verified physical attributes through hierarchical retrieval over a curated prototype database, followed by physics-law--constrained verification and caption rewriting. FysicsOmniCap distills web videos via audio--visual consistency filtering to generate high-fidelity video--instruction pairs emphasizing cross-modal physical cues. We train OmniFysics with staged multimodal alignment and instruction tuning, adopt latent-space flow matching for text-to-image generation, and use an intent router to activate generation only when needed. Experiments show competitive performance on standard multimodal benchmarks and improved results on physics-oriented evaluations.
Dolphin-v2: Universal Document Parsing via Scalable Anchor Prompting
Feb 05, 2026Document parsing has garnered widespread attention as vision-language models (VLMs) advance OCR capabilities. However, the field remains fragmented across dozens of specialized models with varying strengths, forcing users to navigate complex model selection and limiting system scalability. Moreover, existing two-stage approaches depend on axis-aligned bounding boxes for layout detection, failing to handle distorted or photographed documents effectively. To this end, we present Dolphin-v2, a two-stage document image parsing model that substantially improves upon the original Dolphin. In the first stage, Dolphin-v2 jointly performs document type classification (digital-born versus photographed) alongside layout analysis. For digital-born documents, it conducts finer-grained element detection with reading order prediction. In the second stage, we employ a hybrid parsing strategy: photographed documents are parsed holistically as complete pages to handle geometric distortions, while digital-born documents undergo element-wise parallel parsing guided by the detected layout anchors, enabling efficient content extraction. Compared with the original Dolphin, Dolphin-v2 introduces several crucial enhancements: (1) robust parsing of photographed documents via holistic page-level understanding, (2) finer-grained element detection (21 categories) with semantic attribute extraction such as author information and document metadata, and (3) code block recognition with indentation preservation, which existing systems typically lack. Comprehensive evaluations are conducted on DocPTBench, OmniDocBench, and our self-constructed RealDoc-160 benchmark. The results demonstrate substantial improvements: +14.78 points overall on the challenging OmniDocBench and 91% error reduction on photographed documents, while maintaining efficient inference through parallel processing.
Stephanie2: Thinking, Waiting, and Making Decisions Like Humans in Step-by-Step AI Social Chat
Jan 09, 2026Instant-messaging human social chat typically progresses through a sequence of short messages. Existing step-by-step AI chatting systems typically split a one-shot generation into multiple messages and send them sequentially, but they lack an active waiting mechanism and exhibit unnatural message pacing. In order to address these issues, we propose Stephanie2, a novel next-generation step-wise decision-making dialogue agent. With active waiting and message-pace adaptation, Stephanie2 explicitly decides at each step whether to send or wait, and models latency as the sum of thinking time and typing time to achieve more natural pacing. We further introduce a time-window-based dual-agent dialogue system to generate pseudo dialogue histories for human and automatic evaluations. Experiments show that Stephanie2 clearly outperforms Stephanie1 on metrics such as naturalness and engagement, and achieves a higher pass rate on human evaluation with the role identification Turing test.
Beyond Pixel Simulation: Pathology Image Generation via Diagnostic Semantic Tokens and Prototype Control
Dec 24, 2025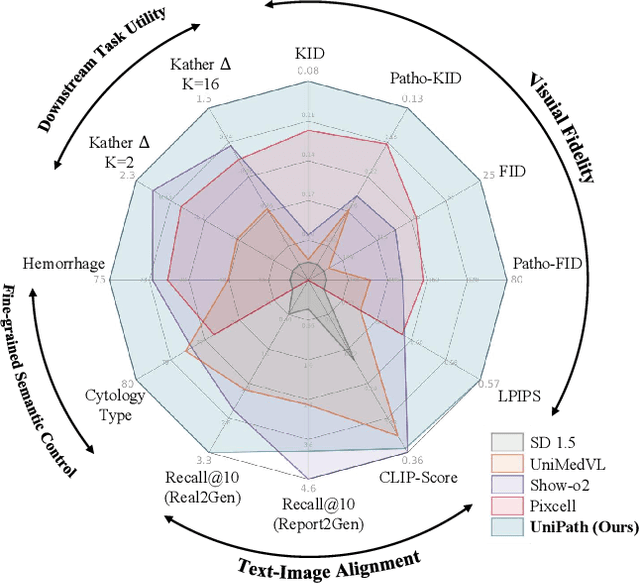
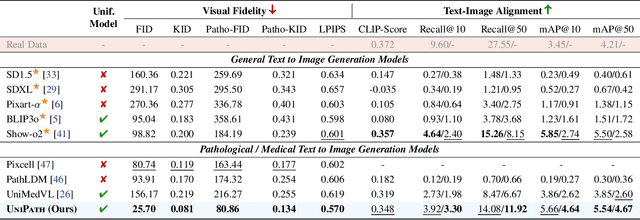
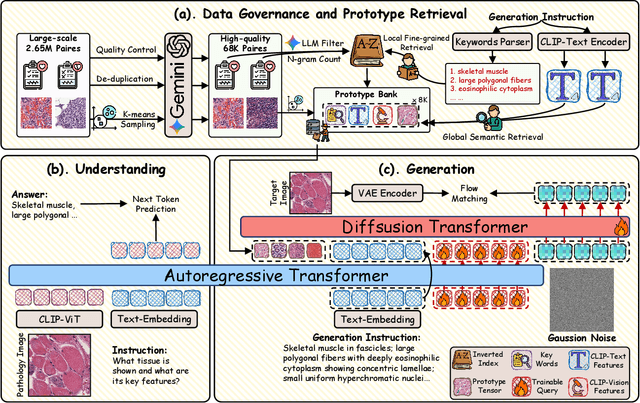
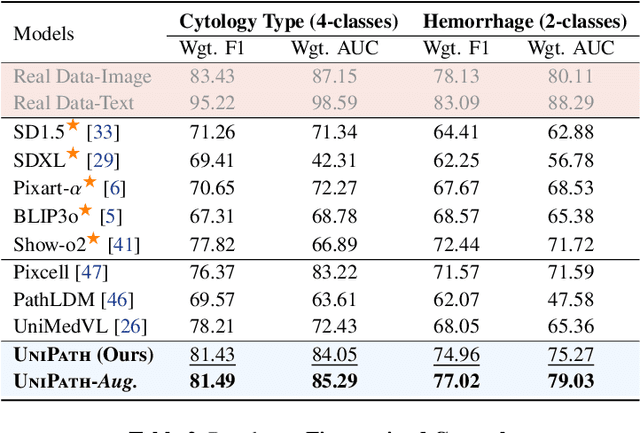
In computational pathology, understanding and generation have evolved along disparate paths: advanced understanding models already exhibit diagnostic-level competence, whereas generative models largely simulate pixels. Progress remains hindered by three coupled factors: the scarcity of large, high-quality image-text corpora; the lack of precise, fine-grained semantic control, which forces reliance on non-semantic cues; and terminological heterogeneity, where diverse phrasings for the same diagnostic concept impede reliable text conditioning. We introduce UniPath, a semantics-driven pathology image generation framework that leverages mature diagnostic understanding to enable controllable generation. UniPath implements Multi-Stream Control: a Raw-Text stream; a High-Level Semantics stream that uses learnable queries to a frozen pathology MLLM to distill paraphrase-robust Diagnostic Semantic Tokens and to expand prompts into diagnosis-aware attribute bundles; and a Prototype stream that affords component-level morphological control via a prototype bank. On the data front, we curate a 2.65M image-text corpus and a finely annotated, high-quality 68K subset to alleviate data scarcity. For a comprehensive assessment, we establish a four-tier evaluation hierarchy tailored to pathology. Extensive experiments demonstrate UniPath's SOTA performance, including a Patho-FID of 80.9 (51% better than the second-best) and fine-grained semantic control achieving 98.7% of the real-image. The meticulously curated datasets, complete source code, and pre-trained model weights developed in this study will be made openly accessible to the public.