 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Geometry of On-Policy Distillation
Jun 05, 2026On-policy distillation (OPD) is increasingly used to improve large language model reasoning, but its training dynamics remain poorly understood. We characterize the trajectory of OPD updates in parameter space and compare it with supervised fine-tuning (SFT) and reinforcement learning with verifiable rewards (RLVR). A suite of parameter-space diagnostics consistently places OPD in a relaxed off-principal regime: compared with SFT, its updates affect fewer weights and avoid principal directions more strongly, while compared with RLVR, they remain less tightly constrained. Beyond this static localization, OPD exhibits subspace locking: its cumulative updates rapidly enter a narrow low-dimensional channel. Constraining training to the update subspace formed early in training preserves OPD performance but substantially degrades SFT, indicating that the locked subspace is functionally sufficient for OPD. Control experiments further show that sparsifying the update tokens and shifting rollout generation off-policy preserve the rank dynamics, whereas mixing the OPD objective with RLVR changes them. Overall, these results suggest that OPD is not merely an intermediate point between SFT and RLVR, but induces its own update geometry in parameter space.
Personalize Your Large Vision-language Models With In-context Prompt Tuning
May 29, 2026Large vision-language models (LVLMs) have demonstrated strong general multimodal capability and are increasingly deployed in downstream systems. This trend has driven growing interest in LVLM personalization, which aims to enable models to quickly and effectively learn out-of-distribution multimodal concepts to meet user-specific needs. However, many existing methods rely on inference-time training, which reduces efficiency. They also struggle to maintain accuracy in complex multi-image, multi-concept settings. These limitations restrict the broader deployment of LVLM-based systems. Therefore, this paper proposes in-context prompt tuning (ICPT). Specifically, ICPT employs a lightweight projection module capable of operating in complex scenarios to extract fine-grained visual semantics from multiple reference images, seamlessly transforming these features alongside identity-label mappings into continuous prompts. To maximize computational efficiency, this module adaptively determines the prompt length based on the intrinsic visual complexity of each concept. Crucially, to overcome the environmental biases and cross-concept interference prevalent in real-world applications, we introduce two novel geometric regularizations. These constraints refine prompt representations by decoupling key identities from transient environmental states and separating concepts to avoid semantic confusion. Extensive experiments show that ICPT achieves state-of-the-art personalization accuracy across diverse tasks and LVLM backbones.
TRACES: Proactive Safety Auditing for Multi-Turn LLM Agents via Trajectory-State Modeling
May 26, 2026LLM agents increasingly operate through multi-turn tool use and environment interaction, where safety risks often emerge from intermediate steps long before they surface in the final outcome. Reactive auditing is therefore insufficient: post-hoc diagnosis frequently misses the chance to flag risks while they are unfolding. We propose TRACES, a representation-based proactive auditor that learns prefix-level trajectory risk states from the hidden representations of an observer LLM. TRACES induces latent mechanism features from step representations and models their temporal evolution to estimate whether a partial trajectory is drifting toward unsafe behavior. To sidestep the cost and ambiguity of step-level risk annotation, TRACES is trained with weak trajectory-level supervision while still producing dense prefix-level risk estimates. Across multiple agent safety benchmarks, TRACES improves both full-trajectory safety prediction and proactive risk discrimination. Our analyses further suggest that these risk states can help train a safer agent, highlighting the broader potential of proactive auditing for long-horizon agent safety.
DeCo-DETR: Decoupled Cognition DETR for efficient Open-Vocabulary Object Detection
Apr 03, 2026Open-vocabulary Object Detection (OVOD) enables models to recognize objects beyond predefined categories, but existing approaches remain limited in practical deployment. On the one hand, multimodal designs often incur substantial computational overhead due to their reliance on text encoders at inference time. On the other hand, tightly coupled training objectives introduce a trade-off between closed-set detection accuracy and open-world generalization. Thus, we propose Decoupled Cognition DETR (DeCo-DETR), a vision-centric framework that addresses these challenges through a unified decoupling paradigm. Instead of depending on online text encoding, DeCo-DETR constructs a hierarchical semantic prototype space from region-level descriptions generated by pre-trained LVLMs and aligned via CLIP, enabling efficient and reusable semantic representation. Building upon this representation, the framework further disentangles semantic reasoning from localization through a decoupled training strategy, which separates alignment and detection into parallel optimization streams. Extensive experiments on standard OVOD benchmarks demonstrate that DeCo-DETR achieves competitive zero-shot detection performance while significantly improving inference efficiency. These results highlight the effectiveness of decoupling semantic cognition from detection, offering a practical direction for scalable OVOD systems.
Not All Directions Matter: Toward Structured and Task-Aware Low-Rank Adaptation
Mar 15, 2026Low-Rank Adaptation (LoRA) has become a cornerstone of parameter-efficient fine-tuning (PEFT). Yet, its efficacy is hampered by two fundamental limitations: semantic drift, by treating all update directions with equal importance, and structural incoherence, from adapting layers independently, resulting in suboptimal, uncoordinated updates. To remedy these, we propose StructLoRA, a framework that addresses both limitations through a principled, dual-component design: (1) an Information Bottleneck-guided filter that prunes task-irrelevant directions to mitigate semantic drift, and (2) a lightweight, training-only graph-based coordinator that enforces inter-layer consistency to resolve structural incoherence. Extensive experiments across large language model , vision language model, and vision model (including LLaMA, LLaVA, and ViT) demonstrate that StructLoRA consistently establishes a new state-of-the-art, outperforming not only vanilla LoRA but also advanced dynamic rank allocation and sparsity-based methods. Notably, the benefits are particularly pronounced in challenging low-rank and low-data regimes. Crucially, since our proposed modules operate only during training, StructLoRA enhances performance with zero additional inference cost, advancing the focus of PEFT -- from mere parameter compression to a more holistic optimization of information quality and structural integrity.
RTD-Guard: A Black-Box Textual Adversarial Detection Framework via Replacement Token Detection
Mar 13, 2026Textual adversarial attacks pose a serious security threat to Natural Language Processing (NLP) systems by introducing imperceptible perturbations that mislead deep learning models. While adversarial example detection offers a lightweight alternative to robust training, existing methods typically rely on prior knowledge of attacks, white-box access to the victim model, or numerous queries, which severely limits their practical deployment. This paper introduces RTD-Guard, a novel black-box framework for detecting textual adversarial examples. Our key insight is that word-substitution perturbations in adversarial attacks closely resemble the "replaced tokens" that a Replaced Token Detection (RTD) discriminator is pre-trained to identify. Leveraging this, RTD-Guard employs an off-the-shelf RTD discriminator-without fine-tuning-to localize suspicious tokens, masks them, and detects adversarial examples by observing the prediction confidence shift of the victim model before and after intervention. The entire process requires no adversarial data, model tuning, or internal model access, and uses only two black-box queries. Comprehensive experiments on multiple benchmark datasets demonstrate that RTD-Guard effectively detects adversarial texts generated by diverse state-of-the-art attack methods. It surpasses existing detection baselines across multiple metrics, offering a highly efficient, practical, and resource-light defense mechanism-particularly suited for real-world deployment in resource-constrained or privacy-sensitive environments.
Steering Vector Fields for Context-Aware Inference-Time Control in Large Language Models
Feb 02, 2026Steering vectors (SVs) offer a lightweight way to control large language models (LLMs) at inference time by shifting hidden activations, providing a practical middle ground between prompting and fine-tuning. Yet SVs can be unreliable in practice. Some concepts are unsteerable, and even when steering helps on average it can backfire for a non-trivial fraction of inputs. Reliability also degrades in long-form generation and multi-attribute steering. We take a geometric view of these failures. A static SV applies the same update vector everywhere in representation space, implicitly assuming that the concept-improving direction is constant across contexts. When the locally effective direction varies with the current activation, a single global vector can become misaligned, which yields weak or reversed effects. Guided by this perspective, we propose Steering Vector Fields (SVF), which learns a differentiable concept scoring function whose local gradient defines the steering direction at each activation, making interventions explicitly context-dependent. This formulation supports coordinated multi-layer interventions in a shared, aligned concept space, and enables efficient long-form and multi-attribute control within a unified framework. Across multiple LLMs and steering tasks, SVF delivers stronger and more reliable control, improving the practicality of inference-time steering.
Evaluating Parameter Efficient Methods for RLVR
Dec 30, 2025We systematically evaluate Parameter-Efficient Fine-Tuning (PEFT) methods under the paradigm of Reinforcement Learning with Verifiable Rewards (RLVR). RLVR incentivizes language models to enhance their reasoning capabilities through verifiable feedback; however, while methods like LoRA are commonly used, the optimal PEFT architecture for RLVR remains unidentified. In this work, we conduct the first comprehensive evaluation of over 12 PEFT methodologies across the DeepSeek-R1-Distill families on mathematical reasoning benchmarks. Our empirical results challenge the default adoption of standard LoRA with three main findings. First, we demonstrate that structural variants, such as DoRA, AdaLoRA, and MiSS, consistently outperform LoRA. Second, we uncover a spectral collapse phenomenon in SVD-informed initialization strategies (\textit{e.g.,} PiSSA, MiLoRA), attributing their failure to a fundamental misalignment between principal-component updates and RL optimization. Furthermore, our ablations reveal that extreme parameter reduction (\textit{e.g.,} VeRA, Rank-1) severely bottlenecks reasoning capacity. We further conduct ablation studies and scaling experiments to validate our findings. This work provides a definitive guide for advocating for more exploration for parameter-efficient RL methods.
Self-Supervised Visual Prompting for Cross-Domain Road Damage Detection
Nov 16, 2025
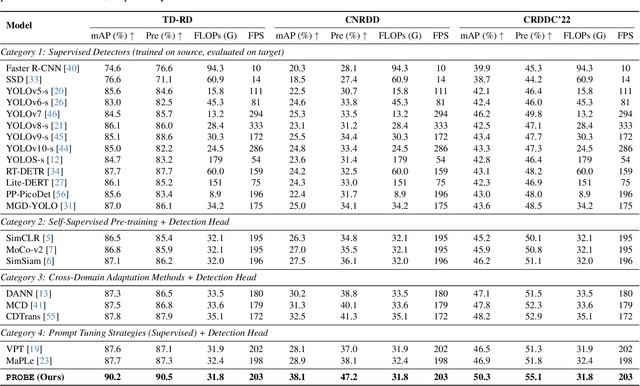
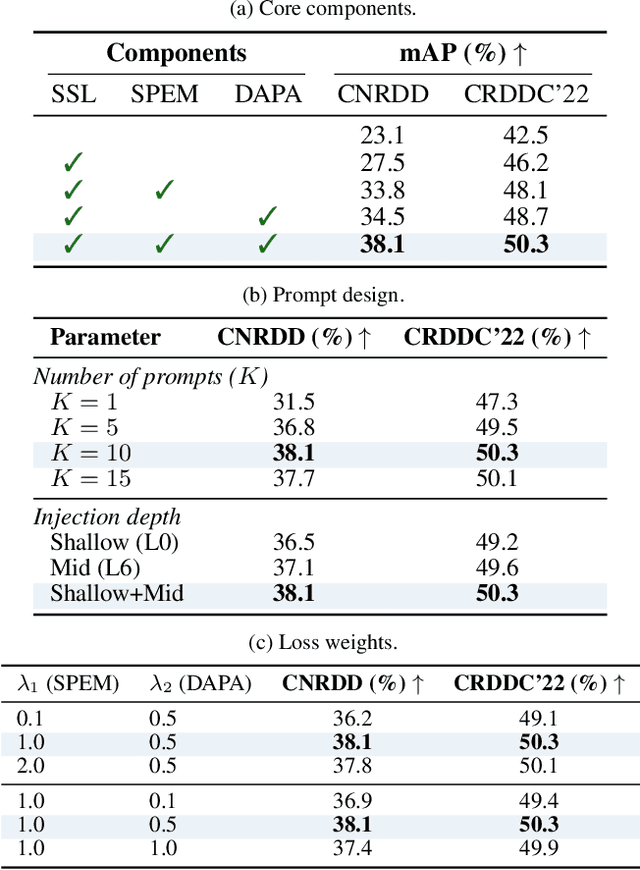

The deployment of automated pavement defect detection is often hindered by poor cross-domain generalization. Supervised detectors achieve strong in-domain accuracy but require costly re-annotation for new environments, while standard self-supervised methods capture generic features and remain vulnerable to domain shift. We propose \ours, a self-supervised framework that \emph{visually probes} target domains without labels. \ours introduces a Self-supervised Prompt Enhancement Module (SPEM), which derives defect-aware prompts from unlabeled target data to guide a frozen ViT backbone, and a Domain-Aware Prompt Alignment (DAPA) objective, which aligns prompt-conditioned source and target representations. Experiments on four challenging benchmarks show that \ours consistently outperforms strong supervised, self-supervised, and adaptation baselines, achieving robust zero-shot transfer, improved resilience to domain variations, and high data efficiency in few-shot adaptation. These results highlight self-supervised prompting as a practical direction for building scalable and adaptive visual inspection systems. Source code is publicly available: https://github.com/xixiaouab/PROBE/tree/main
Read the Scene, Not the Script: Outcome-Aware Safety for LLMs
Oct 05, 2025Safety-aligned Large Language Models (LLMs) still show two dominant failure modes: they are easily jailbroken, or they over-refuse harmless inputs that contain sensitive surface signals. We trace both to a common cause: current models reason weakly about links between actions and outcomes and over-rely on surface-form signals, lexical or stylistic cues that do not encode consequences. We define this failure mode as Consequence-blindness. To study consequence-blindness, we build a benchmark named CB-Bench covering four risk scenarios that vary whether semantic risk aligns with outcome risk, enabling evaluation under both matched and mismatched conditions which are often ignored by existing safety benchmarks. Mainstream models consistently fail to separate these risks and exhibit consequence-blindness, indicating that consequence-blindness is widespread and systematic. To mitigate consequence-blindness, we introduce CS-Chain-4k, a consequence-reasoning dataset for safety alignment. Models fine-tuned on CS-Chain-4k show clear gains against semantic-camouflage jailbreaks and reduce over-refusal on harmless inputs, while maintaining utility and generalization on other benchmarks. These results clarify the limits of current alignment, establish consequence-aware reasoning as a core alignment goal and provide a more practical and reproducible evaluation path.