 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALIGN: Aligned Delegation with Performance Guarantees for Multi-Agent LLM Reasoning
Jan 28, 2026LLMs often underperform on complex reasoning tasks when relying on a single generation-and-selection pipeline. Inference-time ensemble methods can improve performance by sampling diverse reasoning paths or aggregating multiple candidate answers, but they typically treat candidates independently and provide no formal guarantees that ensembling improves reasoning quality. We propose a novel method, Aligned Delegation for Multi-Agent LLM Reasoning (ALIGN), which formulates LLM reasoning as an aligned delegation game. In ALIGN, a principal delegates a task to multiple agents that generate candidate solutions under designed incentives, and then selects among their outputs to produce a final answer. This formulation induces structured interaction among agents while preserving alignment between agent and principal objectives. We establish theoretical guarantees showing that, under a fair comparison with equal access to candidate solutions, ALIGN provably improves expected performance over single-agent generation. Our analysis accommodates correlated candidate answers and relaxes independence assumptions that are commonly used in prior work. Empirical results across a broad range of LLM reasoning benchmarks consistently demonstrate that ALIGN outperforms strong single-agent and ensemble baselines.
Toward Efficient Agents: Memory, Tool learning, and Planning
Jan 20, 2026Recent years have witnessed increasing interest in extending large language models into agentic systems. While the effectiveness of agents has continued to improve, efficiency, which is crucial for real-world deployment, has often been overlooked. This paper therefore investigates efficiency from three core components of agents: memory, tool learning, and planning, considering costs such as latency, tokens, steps, etc. Aimed at conducting comprehensive research addressing the efficiency of the agentic system itself, we review a broad range of recent approaches that differ in implementation yet frequently converge on shared high-level principles including but not limited to bounding context via compression and management, designing reinforcement learning rewards to minimize tool invocation, and employing controlled search mechanisms to enhance efficiency, which we discuss in detail. Accordingly, we characterize efficiency in two complementary ways: comparing effectiveness under a fixed cost budget, and comparing cost at a comparable level of effectiveness. This trade-off can also be viewed through the Pareto frontier between effectiveness and cost. From this perspective, we also examine efficiency oriented benchmarks by summarizing evaluation protocols for these components and consolidating commonly reported efficiency metrics from both benchmark and methodological studies. Moreover, we discuss the key challenges and future directions, with the goal of providing promising insights.
DiffThinker: Towards Generative Multimodal Reasoning with Diffusion Models
Dec 30, 2025While recent Multimodal Large Language Models (MLLMs) have attained significant strides in multimodal reasoning, their reasoning processes remain predominantly text-centric, leading to suboptimal performance in complex long-horizon, vision-centric tasks. In this paper, we establish a novel Generative Multimodal Reasoning paradigm and introduce DiffThinker, a diffusion-based reasoning framework. Conceptually, DiffThinker reformulates multimodal reasoning as a native generative image-to-image task, achieving superior logical consistency and spatial precision in vision-centric tasks. We perform a systematic comparison between DiffThinker and MLLMs, providing the first in-depth investigation into the intrinsic characteristics of this paradigm, revealing four core properties: efficiency, controllability, native parallelism, and collaboration. Extensive experiments across four domains (sequential planning, combinatorial optimization, constraint satisfaction, and spatial configuration) demonstrate that DiffThinker significantly outperforms leading closed source models including GPT-5 (+314.2\%) and Gemini-3-Flash (+111.6\%), as well as the fine-tuned Qwen3-VL-32B baseline (+39.0\%), highlighting generative multimodal reasoning as a promising approach for vision-centric reasoning.
Bohrium + SciMaster: Building the Infrastructure and Ecosystem for Agentic Science at Scale
Dec 23, 2025



AI agents are emerging as a practical way to run multi-step scientific workflows that interleave reasoning with tool use and verification, pointing to a shift from isolated AI-assisted steps toward \emph{agentic science at scale}. This shift is increasingly feasible, as scientific tools and models can be invoked through stable interfaces and verified with recorded execution traces, and increasingly necessary, as AI accelerates scientific output and stresses the peer-review and publication pipeline, raising the bar for traceability and credible evaluation. However, scaling agentic science remains difficult: workflows are hard to observe and reproduce; many tools and laboratory systems are not agent-ready; execution is hard to trace and govern; and prototype AI Scientist systems are often bespoke, limiting reuse and systematic improvement from real workflow signals. We argue that scaling agentic science requires an infrastructure-and-ecosystem approach, instantiated in Bohrium+SciMaster. Bohrium acts as a managed, traceable hub for AI4S assets -- akin to a HuggingFace of AI for Science -- that turns diverse scientific data, software, compute, and laboratory systems into agent-ready capabilities. SciMaster orchestrates these capabilities into long-horizon scientific workflows, on which scientific agents can be composed and executed. Between infrastructure and orchestration, a \emph{scientific intelligence substrate} organizes reusable models, knowledge, and components into executable building blocks for workflow reasoning and action, enabling composition, auditability, and improvement through use. We demonstrate this stack with eleven representative master agents in real workflows, achieving orders-of-magnitude reductions in end-to-end scientific cycle time and generating execution-grounded signals from real workloads at multi-million scale.
ATLAS: A High-Difficulty, Multidisciplinary Benchmark for Frontier Scientific Reasoning
Nov 18, 2025The rapid advancement of Large Language Models (LLMs) has led to performance saturation on many established benchmarks, questioning their ability to distinguish frontier models. Concurrently, existing high-difficulty benchmarks often suffer from narrow disciplinary focus, oversimplified answer formats, and vulnerability to data contamination, creating a fidelity gap with real-world scientific inquiry. To address these challenges, we introduce ATLAS (AGI-Oriented Testbed for Logical Application in Science), a large-scale, high-difficulty, and cross-disciplinary evaluation suite composed of approximately 800 original problems. Developed by domain experts (PhD-level and above), ATLAS spans seven core scientific fields: mathematics, physics, chemistry, biology, computer science, earth science, and materials science. Its key features include: (1) High Originality and Contamination Resistance, with all questions newly created or substantially adapted to prevent test data leakage; (2) Cross-Disciplinary Focus, designed to assess models' ability to integrate knowledge and reason across scientific domains; (3) High-Fidelity Answers, prioritizing complex, open-ended answers involving multi-step reasoning and LaTeX-formatted expressions over simple multiple-choice questions; and (4) Rigorous Quality Control, employing a multi-stage process of expert peer review and adversarial testing to ensure question difficulty, scientific value, and correctness. We also propose a robust evaluation paradigm using a panel of LLM judges for automated, nuanced assessment of complex answers. Preliminary results on leading models demonstrate ATLAS's effectiveness in differentiating their advanced scientific reasoning capabilities. We plan to develop ATLAS into a long-term, open, community-driven platform to provide a reliable "ruler" for progress toward Artificial General Intelligence.
LightAgent: Production-level Open-source Agentic AI Framework
Sep 11, 2025With the rapid advancement of large language models (LLMs), Multi-agent Systems (MAS) have achieved significant progress in various application scenarios. However, substantial challenges remain in designing versatile, robust, and efficient platforms for agent deployment. To address these limitations, we propose \textbf{LightAgent}, a lightweight yet powerful agentic framework, effectively resolving the trade-off between flexibility and simplicity found in existing frameworks. LightAgent integrates core functionalities such as Memory (mem0), Tools, and Tree of Thought (ToT), while maintaining an extremely lightweight structure. As a fully open-source solution, it seamlessly integrates with mainstream chat platforms, enabling developers to easily build self-learning agents. We have released LightAgent at \href{https://github.com/wxai-space/LightAgent}{https://github.com/wxai-space/LightAgent}
UAQFact: Evaluating Factual Knowledge Utilization of LLMs on Unanswerable Questions
May 29, 2025


Handling unanswerable questions (UAQ) is crucial for LLMs, as it helps prevent misleading responses in complex situations. While previous studies have built several datasets to assess LLMs' performance on UAQ, these datasets lack factual knowledge support, which limits the evaluation of LLMs' ability to utilize their factual knowledge when handling UAQ. To address the limitation, we introduce a new unanswerable question dataset UAQFact, a bilingual dataset with auxiliary factual knowledge created from a Knowledge Graph. Based on UAQFact, we further define two new tasks to measure LLMs' ability to utilize internal and external factual knowledge, respectively. Our experimental results across multiple LLM series show that UAQFact presents significant challenges, as LLMs do not consistently perform well even when they have factual knowledge stored. Additionally, we find that incorporating external knowledge may enhance performance, but LLMs still cannot make full use of the knowledge which may result in incorrect responses.
Effective climate policies for major emission reductions of ozone precursors: Global evidence from two decades
May 20, 2025Despite policymakers deploying various tools to mitigate emissions of ozone (O\textsubscript{3}) precursors, such as nitrogen oxides (NO\textsubscript{x}), carbon monoxide (CO), and volatile organic compounds (VOCs), the effectiveness of policy combinations remains uncertain. We employ an integrated framework that couples structural break detection with machine learning to pinpoint effective interventions across the building, electricity, industrial, and transport sectors, identifying treatment effects as abrupt changes without prior assumptions about policy treatment assignment and timing. Applied to two decades of global O\textsubscript{3} precursor emissions data, we detect 78, 77, and 78 structural breaks for NO\textsubscript{x}, CO, and VOCs, corresponding to cumulative emission reductions of 0.96-0.97 Gt, 2.84-2.88 Gt, and 0.47-0.48 Gt, respectively. Sector-level analysis shows that electricity sector structural policies cut NO\textsubscript{x} by up to 32.4\%, while in buildings, developed countries combined adoption subsidies with carbon taxes to achieve 42.7\% CO reductions and developing countries used financing plus fuel taxes to secure 52.3\%. VOCs abatement peaked at 38.5\% when fossil-fuel subsidy reforms were paired with financial incentives. Finally, hybrid strategies merging non-price measures (subsidies, bans, mandates) with pricing instruments delivered up to an additional 10\% co-benefit. These findings guide the sequencing and complementarity of context-specific policy portfolios for O\textsubscript{3} precursor mitigation.
Incentivizing Truthful Language Models via Peer Elicitation Games
May 19, 2025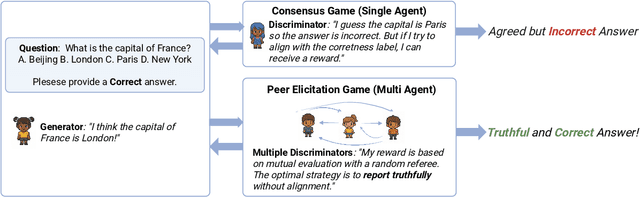
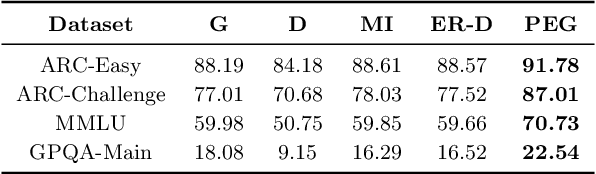
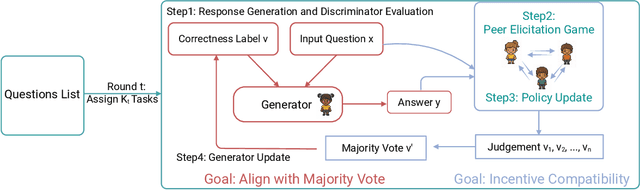

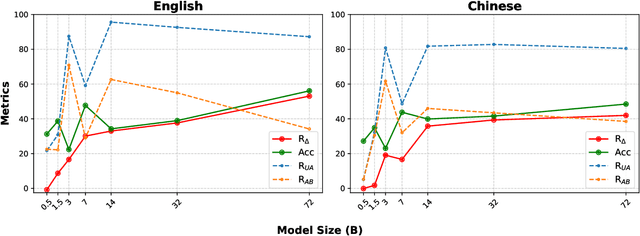
Large Language Models (LLMs) have demonstrated strong generative capabilities but remain prone to inconsistencies and hallucinations. We introduce Peer Elicitation Games (PEG), a training-free, game-theoretic framework for aligning LLMs through a peer elicitation mechanism involving a generator and multiple discriminators instantiated from distinct base models. Discriminators interact in a peer evaluation setting, where rewards are computed using a determinant-based mutual information score that provably incentivizes truthful reporting without requiring ground-truth labels. We establish theoretical guarantees showing that each agent, via online learning, achieves sublinear regret in the sense their cumulative performance approaches that of the best fixed truthful strategy in hindsight. Moreover, we prove last-iterate convergence to a truthful Nash equilibrium, ensuring that the actual policies used by agents converge to stable and truthful behavior over time. Empirical evaluations across multiple benchmarks demonstrate significant improvements in factual accuracy. These results position PEG as a practical approach for eliciting truthful behavior from LLMs without supervision or fine-tuning.
Chain-of-Tools: Utilizing Massive Unseen Tools in the CoT Reasoning of Frozen Language Models
Mar 21, 2025Tool learning can further broaden the usage scenarios of large language models (LLMs). However most of the existing methods either need to finetune that the model can only use tools seen in the training data, or add tool demonstrations into the prompt with lower efficiency. In this paper, we present a new Tool Learning method Chain-of-Tools. It makes full use of the powerful semantic representation capability of frozen LLMs to finish tool calling in CoT reasoning with a huge and flexible tool pool which may contain unseen tools. Especially, to validate the effectiveness of our approach in the massive unseen tool scenario, we construct a new dataset SimpleToolQuestions. We conduct experiments on two numerical reasoning benchmarks (GSM8K-XL and FuncQA) and two knowledge-based question answering benchmarks (KAMEL and SimpleToolQuestions). Experimental results show that our approach performs better than the baseline. We also identify dimensions of the model output that are critical in tool selection, enhancing the model interpretability. Our code and data are available at: https://github.com/fairyshine/Chain-of-Tools .