 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Reason Faithfully through Step-Level Faithfulness Maximization
Feb 03, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has markedly improved the performance of Large Language Models (LLMs) on tasks requiring multi-step reasoning. However, most RLVR pipelines rely on sparse outcome-based rewards, providing little supervision over intermediate steps and thus encouraging over-confidence and spurious reasoning, which in turn increases hallucinations. To address this, we propose FaithRL, a general reinforcement learning framework that directly optimizes reasoning faithfulness. We formalize a faithfulness-maximization objective and theoretically show that optimizing it mitigates over-confidence. To instantiate this objective, we introduce a geometric reward design and a faithfulness-aware advantage modulation mechanism that assigns step-level credit by penalizing unsupported steps while preserving valid partial derivations. Across diverse backbones and benchmarks, FaithRL consistently reduces hallucination rates while maintaining (and often improving) answer correctness. Further analysis confirms that FaithRL increases step-wise reasoning faithfulness and generalizes robustly. Our code is available at https://github.com/aintdoin/FaithRL.
LatentMem: Customizing Latent Memory for Multi-Agent Systems
Feb 03, 2026Large language model (LLM)-powered multi-agent systems (MAS) demonstrate remarkable collective intelligence, wherein multi-agent memory serves as a pivotal mechanism for continual adaptation. However, existing multi-agent memory designs remain constrained by two fundamental bottlenecks: (i) memory homogenization arising from the absence of role-aware customization, and (ii) information overload induced by excessively fine-grained memory entries. To address these limitations, we propose LatentMem, a learnable multi-agent memory framework designed to customize agent-specific memories in a token-efficient manner. Specifically, LatentMem comprises an experience bank that stores raw interaction trajectories in a lightweight form, and a memory composer that synthesizes compact latent memories conditioned on retrieved experience and agent-specific contexts. Further, we introduce Latent Memory Policy Optimization (LMPO), which propagates task-level optimization signals through latent memories to the composer, encouraging it to produce compact and high-utility representations. Extensive experiments across diverse benchmarks and mainstream MAS frameworks show that LatentMem achieves a performance gain of up to $19.36$% over vanilla settings and consistently outperforms existing memory architectures, without requiring any modifications to the underlying frameworks.
Stable-DiffCoder: Pushing the Frontier of Code Diffusion Large Language Model
Jan 23, 2026Diffusion-based language models (DLLMs) offer non-sequential, block-wise generation and richer data reuse compared to autoregressive (AR) models, but existing code DLLMs still lag behind strong AR baselines under comparable budgets. We revisit this setting in a controlled study and introduce Stable-DiffCoder, a block diffusion code model that reuses the Seed-Coder architecture, data, and training pipeline. To enable efficient knowledge learning and stable training, we incorporate a block diffusion continual pretraining (CPT) stage enhanced by a tailored warmup and block-wise clipped noise schedule. Under the same data and architecture, Stable-DiffCoder overall outperforms its AR counterpart on a broad suite of code benchmarks. Moreover, relying only on the CPT and supervised fine-tuning stages, Stable-DiffCoder achieves stronger performance than a wide range of \~8B ARs and DLLMs, demonstrating that diffusion-based training can improve code modeling quality beyond AR training alone. Moreover, diffusion-based any-order modeling improves structured code modeling for editing and reasoning, and through data augmentation, benefits low-resource coding languages.
Toward Efficient Agents: Memory, Tool learning, and Planning
Jan 20, 2026Recent years have witnessed increasing interest in extending large language models into agentic systems. While the effectiveness of agents has continued to improve, efficiency, which is crucial for real-world deployment, has often been overlooked. This paper therefore investigates efficiency from three core components of agents: memory, tool learning, and planning, considering costs such as latency, tokens, steps, etc. Aimed at conducting comprehensive research addressing the efficiency of the agentic system itself, we review a broad range of recent approaches that differ in implementation yet frequently converge on shared high-level principles including but not limited to bounding context via compression and management, designing reinforcement learning rewards to minimize tool invocation, and employing controlled search mechanisms to enhance efficiency, which we discuss in detail. Accordingly, we characterize efficiency in two complementary ways: comparing effectiveness under a fixed cost budget, and comparing cost at a comparable level of effectiveness. This trade-off can also be viewed through the Pareto frontier between effectiveness and cost. From this perspective, we also examine efficiency oriented benchmarks by summarizing evaluation protocols for these components and consolidating commonly reported efficiency metrics from both benchmark and methodological studies. Moreover, we discuss the key challenges and future directions, with the goal of providing promising insights.
DiffThinker: Towards Generative Multimodal Reasoning with Diffusion Models
Dec 30, 2025While recent Multimodal Large Language Models (MLLMs) have attained significant strides in multimodal reasoning, their reasoning processes remain predominantly text-centric, leading to suboptimal performance in complex long-horizon, vision-centric tasks. In this paper, we establish a novel Generative Multimodal Reasoning paradigm and introduce DiffThinker, a diffusion-based reasoning framework. Conceptually, DiffThinker reformulates multimodal reasoning as a native generative image-to-image task, achieving superior logical consistency and spatial precision in vision-centric tasks. We perform a systematic comparison between DiffThinker and MLLMs, providing the first in-depth investigation into the intrinsic characteristics of this paradigm, revealing four core properties: efficiency, controllability, native parallelism, and collaboration. Extensive experiments across four domains (sequential planning, combinatorial optimization, constraint satisfaction, and spatial configuration) demonstrate that DiffThinker significantly outperforms leading closed source models including GPT-5 (+314.2\%) and Gemini-3-Flash (+111.6\%), as well as the fine-tuned Qwen3-VL-32B baseline (+39.0\%), highlighting generative multimodal reasoning as a promising approach for vision-centric reasoning.
VA-$π$: Variational Policy Alignment for Pixel-Aware Autoregressive Generation
Dec 22, 2025Autoregressive (AR) visual generation relies on tokenizers to map images to and from discrete sequences. However, tokenizers are trained to reconstruct clean images from ground-truth tokens, while AR generators are optimized only for token likelihood. This misalignment leads to generated token sequences that may decode into low-quality images, without direct supervision from the pixel space. We propose VA-$π$, a lightweight post-training framework that directly optimizes AR models with a principled pixel-space objective. VA-$π$ formulates the generator-tokenizer alignment as a variational optimization, deriving an evidence lower bound (ELBO) that unifies pixel reconstruction and autoregressive modeling. To optimize under the discrete token space, VA-$π$ introduces a reinforcement-based alignment strategy that treats the AR generator as a policy, uses pixel-space reconstruction quality as its intrinsic reward. The reward is measured by how well the predicted token sequences can reconstruct the original image under teacher forcing, giving the model direct pixel-level guidance without expensive free-running sampling. The regularization term of the ELBO serves as a natural regularizer, maintaining distributional consistency of tokens. VA-$π$ enables rapid adaptation of existing AR generators, without neither tokenizer retraining nor external reward models. With only 1% ImageNet-1K data and 25 minutes of tuning, it reduces FID from 14.36 to 7.65 and improves IS from 86.55 to 116.70 on LlamaGen-XXL, while also yielding notable gains in the text-to-image task on GenEval for both visual generation model (LlamaGen: from 0.306 to 0.339) and unified multi-modal model (Janus-Pro: from 0.725 to 0.744). Code is available at https://github.com/Lil-Shake/VA-Pi.
VideoSSR: Video Self-Supervised Reinforcement Learning
Nov 09, 2025Reinforcement Learning with Verifiable Rewards (RLVR) has substantially advanced the video understanding capabilities of Multimodal Large Language Models (MLLMs). However, the rapid progress of MLLMs is outpacing the complexity of existing video datasets, while the manual annotation of new, high-quality data remains prohibitively expensive. This work investigates a pivotal question: Can the rich, intrinsic information within videos be harnessed to self-generate high-quality, verifiable training data? To investigate this, we introduce three self-supervised pretext tasks: Anomaly Grounding, Object Counting, and Temporal Jigsaw. We construct the Video Intrinsic Understanding Benchmark (VIUBench) to validate their difficulty, revealing that current state-of-the-art MLLMs struggle significantly on these tasks. Building upon these pretext tasks, we develop the VideoSSR-30K dataset and propose VideoSSR, a novel video self-supervised reinforcement learning framework for RLVR. Extensive experiments across 17 benchmarks, spanning four major video domains (General Video QA, Long Video QA, Temporal Grounding, and Complex Reasoning), demonstrate that VideoSSR consistently enhances model performance, yielding an average improvement of over 5\%. These results establish VideoSSR as a potent foundational framework for developing more advanced video understanding in MLLMs. The code is available at https://github.com/lcqysl/VideoSSR.
ExGRPO: Learning to Reason from Experience
Oct 02, 2025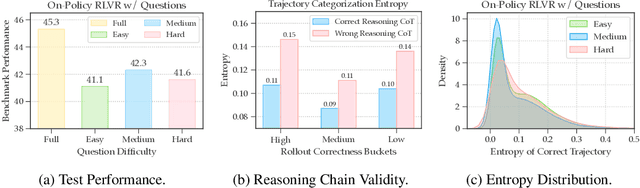
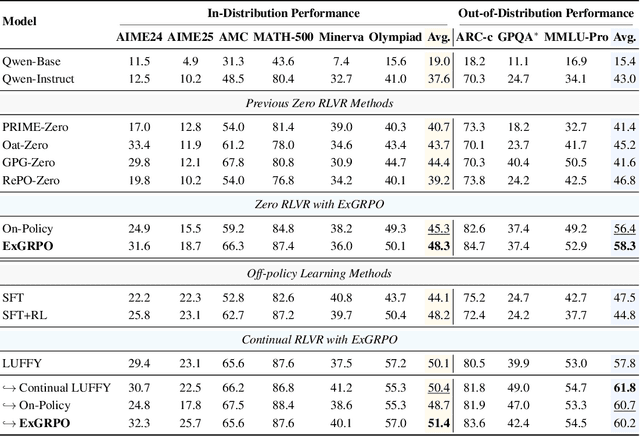
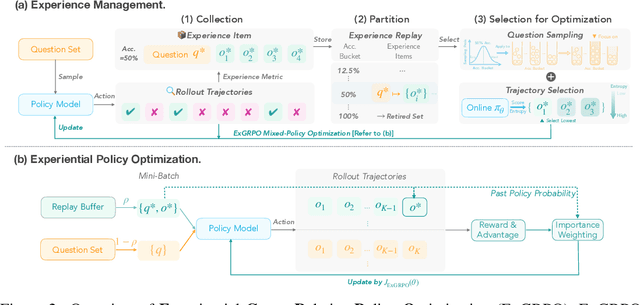
Reinforcement learning from verifiable rewards (RLVR) is an emerging paradigm for improving the reasoning ability of large language models. However, standard on-policy training discards rollout experiences after a single update, leading to computational inefficiency and instability. While prior work on RL has highlighted the benefits of reusing past experience, the role of experience characteristics in shaping learning dynamics of large reasoning models remains underexplored. In this paper, we are the first to investigate what makes a reasoning experience valuable and identify rollout correctness and entropy as effective indicators of experience value. Based on these insights, we propose ExGRPO (Experiential Group Relative Policy Optimization), a framework that organizes and prioritizes valuable experiences, and employs a mixed-policy objective to balance exploration with experience exploitation. Experiments on five backbone models (1.5B-8B parameters) show that ExGRPO consistently improves reasoning performance on mathematical/general benchmarks, with an average gain of +3.5/7.6 points over on-policy RLVR. Moreover, ExGRPO stabilizes training on both stronger and weaker models where on-policy methods fail. These results highlight principled experience management as a key ingredient for efficient and scalable RLVR.
A Survey of Reinforcement Learning for Large Reasoning Models
Sep 10, 2025In this paper, we survey recent advances in Reinforcement Learning (RL) for reasoning with Large Language Models (LLMs). RL has achieved remarkable success in advancing the frontier of LLM capabilities, particularly in addressing complex logical tasks such as mathematics and coding. As a result, RL has emerged as a foundational methodology for transforming LLMs into LRMs. With the rapid progress of the field, further scaling of RL for LRMs now faces foundational challenges not only in computational resources but also in algorithm design, training data, and infrastructure. To this end, it is timely to revisit the development of this domain, reassess its trajectory, and explore strategies to enhance the scalability of RL toward Artificial SuperIntelligence (ASI). In particular, we examine research applying RL to LLMs and LRMs for reasoning abilities, especially since the release of DeepSeek-R1, including foundational components, core problems, training resources, and downstream applications, to identify future opportunities and directions for this rapidly evolving area. We hope this review will promote future research on RL for broader reasoning models. Github: https://github.com/TsinghuaC3I/Awesome-RL-for-LRMs
SafeWork-R1: Coevolving Safety and Intelligence under the AI-45$^{\circ}$ Law
Jul 24, 2025



We introduce SafeWork-R1, a cutting-edge multimodal reasoning model that demonstrates the coevolution of capabilities and safety. It is developed by our proposed SafeLadder framework, which incorporates large-scale, progressive, safety-oriented reinforcement learning post-training, supported by a suite of multi-principled verifiers. Unlike previous alignment methods such as RLHF that simply learn human preferences, SafeLadder enables SafeWork-R1 to develop intrinsic safety reasoning and self-reflection abilities, giving rise to safety `aha' moments. Notably, SafeWork-R1 achieves an average improvement of $46.54\%$ over its base model Qwen2.5-VL-72B on safety-related benchmarks without compromising general capabilities, and delivers state-of-the-art safety performance compared to leading proprietary models such as GPT-4.1 and Claude Opus 4. To further bolster its reliability, we implement two distinct inference-time intervention methods and a deliberative search mechanism, enforcing step-level verification. Finally, we further develop SafeWork-R1-InternVL3-78B, SafeWork-R1-DeepSeek-70B, and SafeWork-R1-Qwen2.5VL-7B. All resulting models demonstrate that safety and capability can co-evolve synergistically, highlighting the generalizability of our framework in building robust, reliable, and trustworthy general-purpose AI.