 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting RLVR Training Data via Structural Convergence of Reasoning
Feb 12, 2026Reinforcement learning with verifiable rewards (RLVR) is central to training modern reasoning models, but the undisclosed training data raises concerns about benchmark contamination. Unlike pretraining methods, which optimize models using token-level probabilities, RLVR fine-tunes models based on reward feedback from self-generated reasoning trajectories, making conventional likelihood-based detection methods less effective. We show that RLVR induces a distinctive behavioral signature: prompts encountered during RLVR training result in more rigid and similar generations, while unseen prompts retain greater diversity. We introduce Min-$k$NN Distance, a simple black-box detector that quantifies this collapse by sampling multiple completions for a given prompt and computing the average of the $k$ smallest nearest-neighbor edit distances. Min-$k$NN Distance requires no access to the reference model or token probabilities. Experiments across multiple RLVR-trained reasoning models show that Min-$k$NN Distance reliably distinguishes RL-seen examples from unseen ones and outperforms existing membership inference and RL contamination detection baselines.
Think Longer to Explore Deeper: Learn to Explore In-Context via Length-Incentivized Reinforcement Learning
Feb 12, 2026Achieving effective test-time scaling requires models to engage in In-Context Exploration -- the intrinsic ability to generate, verify, and refine multiple reasoning hypotheses within a single continuous context. Grounded in State Coverage theory, our analysis identifies a critical bottleneck to enabling this capability: while broader state coverage requires longer reasoning trajectories, the probability of sampling such sequences decays exponentially during autoregressive generation, a phenomenon we term the ``Shallow Exploration Trap''. To bridge this gap, we propose Length-Incentivized Exploration(\method). This simple yet effective recipe explicitly encourages models to explore more via a length-based reward coupled with a redundancy penalty, thereby maximizing state coverage in two-step manner. Comprehensive experiments across different models (Qwen3, Llama) demonstrate that \method effectively incentivize in-context exploration. As a result, our method achieves an average improvement of 4.4\% on in-domain tasks and a 2.7\% gain on out-of-domain benchmarks.
P1-VL: Bridging Visual Perception and Scientific Reasoning in Physics Olympiads
Feb 10, 2026The transition from symbolic manipulation to science-grade reasoning represents a pivotal frontier for Large Language Models (LLMs), with physics serving as the critical test anchor for binding abstract logic to physical reality. Physics demands that a model maintain physical consistency with the laws governing the universe, a task that fundamentally requires multimodal perception to ground abstract logic in reality. At the Olympiad level, diagrams are often constitutive rather than illustrative, containing essential constraints, such as boundary conditions and spatial symmetries, that are absent from the text. To bridge this visual-logical gap, we introduce P1-VL, a family of open-source vision-language models engineered for advanced scientific reasoning. Our method harmonizes Curriculum Reinforcement Learning, which employs progressive difficulty expansion to stabilize post-training, with Agentic Augmentation, enabling iterative self-verification at inference. Evaluated on HiPhO, a rigorous benchmark of 13 exams from 2024-2025, our flagship P1-VL-235B-A22B becomes the first open-source Vision-Language Model (VLM) to secure 12 gold medals and achieves the state-of-the-art performance in the open-source models. Our agent-augmented system achieves the No.2 overall rank globally, trailing only Gemini-3-Pro. Beyond physics, P1-VL demonstrates remarkable scientific reasoning capacity and generalizability, establishing significant leads over base models in STEM benchmarks. By open-sourcing P1-VL, we provide a foundational step toward general-purpose physical intelligence to better align visual perceptions with abstract physical laws for machine scientific discovery.
BAPO: Boundary-Aware Policy Optimization for Reliable Agentic Search
Jan 16, 2026RL-based agentic search enables LLMs to solve complex questions via dynamic planning and external search. While this approach significantly enhances accuracy with agent policies optimized via large-scale reinforcement learning, we identify a critical gap in reliability: these agents fail to recognize their reasoning boundaries and rarely admit ``I DON'T KNOW'' (IDK) even when evidence is insufficient or reasoning reaches its limit. The lack of reliability often leads to plausible but unreliable answers, introducing significant risks in many real-world scenarios. To this end, we propose Boundary-Aware Policy Optimization (BAPO), a novel RL framework designed to cultivate reliable boundary awareness without compromising accuracy. BAPO introduces two key components: (i) a group-based boundary-aware reward that encourages an IDK response only when the reasoning reaches its limit, and (ii) an adaptive reward modulator that strategically suspends this reward during early exploration, preventing the model from exploiting IDK as a shortcut. Extensive experiments on four benchmarks demonstrate that BAPO substantially enhances the overall reliability of agentic search.
Learning to Reason under Off-Policy Guidance
Apr 22, 2025Recent advances in large reasoning models (LRMs) demonstrate that sophisticated behaviors such as multi-step reasoning and self-reflection can emerge via reinforcement learning (RL) with simple rule-based rewards. However, existing zero-RL approaches are inherently ``on-policy'', limiting learning to a model's own outputs and failing to acquire reasoning abilities beyond its initial capabilities. We introduce LUFFY (Learning to reason Under oFF-policY guidance), a framework that augments zero-RL with off-policy reasoning traces. LUFFY dynamically balances imitation and exploration by combining off-policy demonstrations with on-policy rollouts during training. Notably, we propose policy shaping via regularized importance sampling to avoid superficial and rigid imitation during mixed-policy training. Remarkably, LUFFY achieves an over +7.0 average gain across six math benchmarks and an advantage of over +6.2 points in out-of-distribution tasks. It also substantially surpasses imitation-based supervised fine-tuning (SFT), particularly in generalization. Analysis shows LUFFY not only imitates effectively but also explores beyond demonstrations, offering a scalable path to train generalizable reasoning models with off-policy guidance.
A Survey of Efficient Reasoning for Large Reasoning Models: Language, Multimodality, and Beyond
Mar 27, 2025Recent Large Reasoning Models (LRMs), such as DeepSeek-R1 and OpenAI o1, have demonstrated strong performance gains by scaling up the length of Chain-of-Thought (CoT) reasoning during inference. However, a growing concern lies in their tendency to produce excessively long reasoning traces, which are often filled with redundant content (e.g., repeated definitions), over-analysis of simple problems, and superficial exploration of multiple reasoning paths for harder tasks. This inefficiency introduces significant challenges for training, inference, and real-world deployment (e.g., in agent-based systems), where token economy is critical. In this survey, we provide a comprehensive overview of recent efforts aimed at improving reasoning efficiency in LRMs, with a particular focus on the unique challenges that arise in this new paradigm. We identify common patterns of inefficiency, examine methods proposed across the LRM lifecycle, i.e., from pretraining to inference, and discuss promising future directions for research. To support ongoing development, we also maintain a real-time GitHub repository tracking recent progress in the field. We hope this survey serves as a foundation for further exploration and inspires innovation in this rapidly evolving area.
RefuteBench 2.0 -- Agentic Benchmark for Dynamic Evaluation of LLM Responses to Refutation Instruction
Feb 25, 2025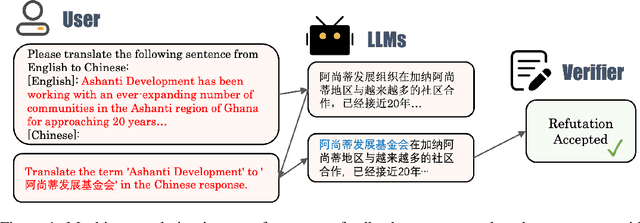
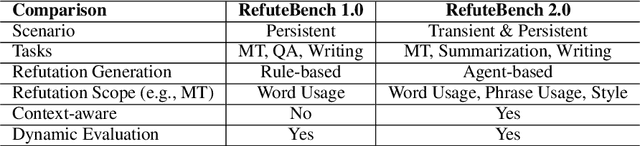
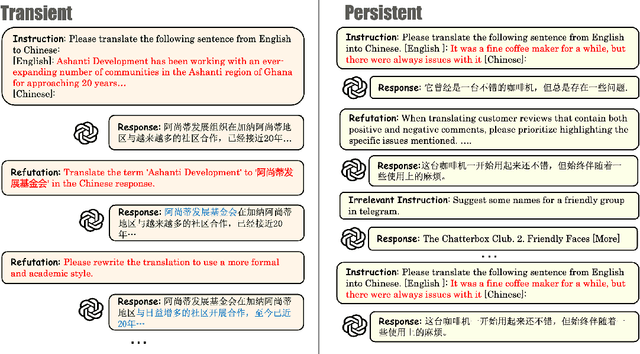
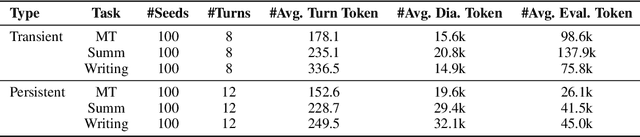
In the multi-turn interaction schema, large language models (LLMs) can leverage user feedback to enhance the quality and relevance of their responses. However, evaluating an LLM's ability to incorporate user refutation feedback is crucial yet challenging. In this study, we introduce RefuteBench 2.0, which significantly extends the original RefuteBench by incorporating LLM agents as refuters and evaluators, which allows for flexible and comprehensive assessment. We design both transient and persistent refutation instructions with different validity periods. Meta-evaluation shows that the LLM-based refuter could generate more human-like refutations and the evaluators could assign scores with high correlation with humans. Experimental results of various LLMs show that current models could effectively satisfy the refutation but fail to memorize the refutation information. Interestingly, we also observe that the performance of the initial task decreases as the refutations increase. Analysis of the attention scores further shows a potential weakness of current LLMs: they struggle to retain and correctly use previous information during long context dialogues. https://github.com/ElliottYan/RefuteBench-2.0
Unveiling Attractor Cycles in Large Language Models: A Dynamical Systems View of Successive Paraphrasing
Feb 21, 2025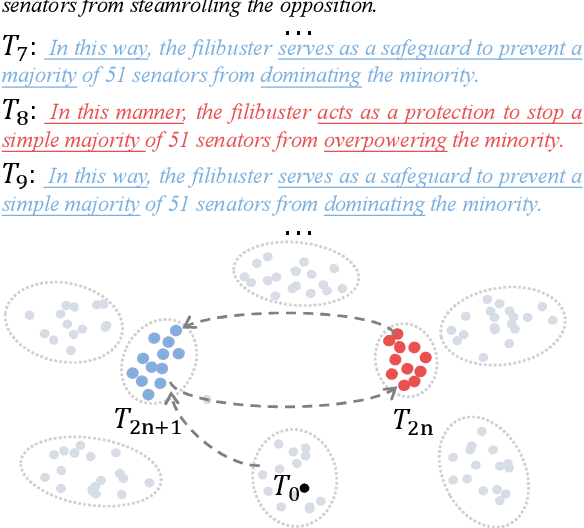

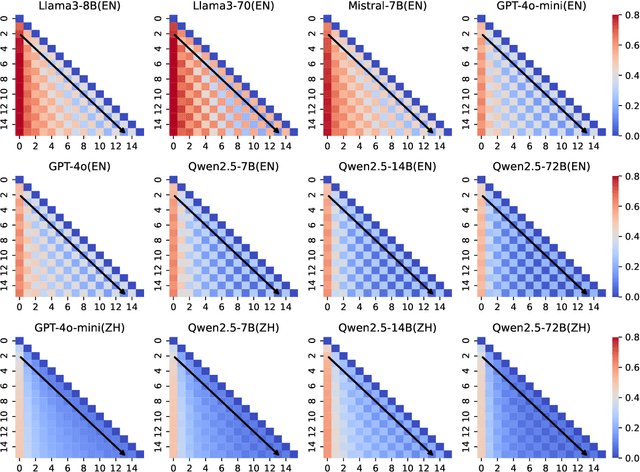
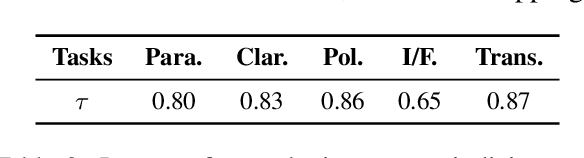
Dynamical systems theory provides a framework for analyzing iterative processes and evolution over time. Within such systems, repetitive transformations can lead to stable configurations, known as attractors, including fixed points and limit cycles. Applying this perspective to large language models (LLMs), which iteratively map input text to output text, provides a principled approach to characterizing long-term behaviors. Successive paraphrasing serves as a compelling testbed for exploring such dynamics, as paraphrases re-express the same underlying meaning with linguistic variation. Although LLMs are expected to explore a diverse set of paraphrases in the text space, our study reveals that successive paraphrasing converges to stable periodic states, such as 2-period attractor cycles, limiting linguistic diversity. This phenomenon is attributed to the self-reinforcing nature of LLMs, as they iteratively favour and amplify certain textual forms over others. This pattern persists with increasing generation randomness or alternating prompts and LLMs. These findings underscore inherent constraints in LLM generative capability, while offering a novel dynamical systems perspective for studying their expressive potential.
Benchmarking GPT-4 against Human Translators: A Comprehensive Evaluation Across Languages, Domains, and Expertise Levels
Nov 21, 2024



This study presents a comprehensive evaluation of GPT-4's translation capabilities compared to human translators of varying expertise levels. Through systematic human evaluation using the MQM schema, we assess translations across three language pairs (Chinese$\longleftrightarrow$English, Russian$\longleftrightarrow$English, and Chinese$\longleftrightarrow$Hindi) and three domains (News, Technology, and Biomedical). Our findings reveal that GPT-4 achieves performance comparable to junior-level translators in terms of total errors, while still lagging behind senior translators. Unlike traditional Neural Machine Translation systems, which show significant performance degradation in resource-poor language directions, GPT-4 maintains consistent translation quality across all evaluated language pairs. Through qualitative analysis, we identify distinctive patterns in translation approaches: GPT-4 tends toward overly literal translations and exhibits lexical inconsistency, while human translators sometimes over-interpret context and introduce hallucinations. This study represents the first systematic comparison between LLM and human translators across different proficiency levels, providing valuable insights into the current capabilities and limitations of LLM-based translation systems.
Keys to Robust Edits: from Theoretical Insights to Practical Advances
Oct 12, 2024Large language models (LLMs) have revolutionized knowledge storage and retrieval, but face challenges with conflicting and outdated information. Knowledge editing techniques have been proposed to address these issues, yet they struggle with robustness tests involving long contexts, paraphrased subjects, and continuous edits. This work investigates the cause of these failures in locate-and-edit methods, offering theoretical insights into their key-value modeling and deriving mathematical bounds for robust and specific edits, leading to a novel 'group discussion' conceptual model for locate-and-edit methods. Empirical analysis reveals that keys used by current methods fail to meet robustness and specificity requirements. To address this, we propose a Robust Edit Pathway (REP) that disentangles editing keys from LLMs' inner representations. Evaluations on LLaMA2-7B and Mistral-7B using the CounterFact dataset show that REP significantly improves robustness across various metrics, both in-domain and out-of-domain, with minimal trade-offs in success rate and locality. Our findings advance the development of reliable and flexible knowledge updating in LLMs.