 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNirvana: A Specialized Generalist Model With Task-Aware Memory Mechanism
Oct 30, 2025Specialized Generalist Models (SGMs) aim to preserve broad capabilities while achieving expert-level performance in target domains. However, traditional LLM structures including Transformer, Linear Attention, and hybrid models do not employ specialized memory mechanism guided by task information. In this paper, we present Nirvana, an SGM with specialized memory mechanism, linear time complexity, and test-time task information extraction. Besides, we propose the Task-Aware Memory Trigger ($\textit{Trigger}$) that flexibly adjusts memory mechanism based on the current task's requirements. In Trigger, each incoming sample is treated as a self-supervised fine-tuning task, enabling Nirvana to adapt its task-related parameters on the fly to domain shifts. We also design the Specialized Memory Updater ($\textit{Updater}$) that dynamically memorizes the context guided by Trigger. We conduct experiments on both general language tasks and specialized medical tasks. On a variety of natural language modeling benchmarks, Nirvana achieves competitive or superior results compared to the existing LLM structures. To prove the effectiveness of Trigger on specialized tasks, we test Nirvana's performance on a challenging medical task, i.e., Magnetic Resonance Imaging (MRI). We post-train frozen Nirvana backbone with lightweight codecs on paired electromagnetic signals and MRI images. Despite the frozen Nirvana backbone, Trigger guides the model to adapt to the MRI domain with the change of task-related parameters. Nirvana achieves higher-quality MRI reconstruction compared to conventional MRI models as well as the models with traditional LLMs' backbone, and can also generate accurate preliminary clinical reports accordingly.
Native Hybrid Attention for Efficient Sequence Modeling
Oct 08, 2025



Transformers excel at sequence modeling but face quadratic complexity, while linear attention offers improved efficiency but often compromises recall accuracy over long contexts. In this work, we introduce Native Hybrid Attention (NHA), a novel hybrid architecture of linear and full attention that integrates both intra \& inter-layer hybridization into a unified layer design. NHA maintains long-term context in key-value slots updated by a linear RNN, and augments them with short-term tokens from a sliding window. A single \texttt{softmax attention} operation is then applied over all keys and values, enabling per-token and per-head context-dependent weighting without requiring additional fusion parameters. The inter-layer behavior is controlled through a single hyperparameter, the sliding window size, which allows smooth adjustment between purely linear and full attention while keeping all layers structurally uniform. Experimental results show that NHA surpasses Transformers and other hybrid baselines on recall-intensive and commonsense reasoning tasks. Furthermore, pretrained LLMs can be structurally hybridized with NHA, achieving competitive accuracy while delivering significant efficiency gains. Code is available at https://github.com/JusenD/NHA.
SSFO: Self-Supervised Faithfulness Optimization for Retrieval-Augmented Generation
Aug 24, 2025Retrieval-Augmented Generation (RAG) systems require Large Language Models (LLMs) to generate responses that are faithful to the retrieved context. However, faithfulness hallucination remains a critical challenge, as existing methods often require costly supervision and post-training or significant inference burdens. To overcome these limitations, we introduce Self-Supervised Faithfulness Optimization (SSFO), the first self-supervised alignment approach for enhancing RAG faithfulness. SSFO constructs preference data pairs by contrasting the model's outputs generated with and without the context. Leveraging Direct Preference Optimization (DPO), SSFO aligns model faithfulness without incurring labeling costs or additional inference burden. We theoretically and empirically demonstrate that SSFO leverages a benign form of \emph{likelihood displacement}, transferring probability mass from parametric-based tokens to context-aligned tokens. Based on this insight, we propose a modified DPO loss function to encourage likelihood displacement. Comprehensive evaluations show that SSFO significantly outperforms existing methods, achieving state-of-the-art faithfulness on multiple context-based question-answering datasets. Notably, SSFO exhibits strong generalization, improving cross-lingual faithfulness and preserving general instruction-following capabilities. We release our code and model at the anonymous link: https://github.com/chkwy/SSFO
CogniBench: A Legal-inspired Framework and Dataset for Assessing Cognitive Faithfulness of Large Language Models
May 28, 2025Faithfulness hallucination are claims generated by a Large Language Model (LLM) not supported by contexts provided to the LLM. Lacking assessment standard, existing benchmarks only contain "factual statements" that rephrase source materials without marking "cognitive statements" that make inference from the given context, making the consistency evaluation and optimization of cognitive statements difficult. Inspired by how an evidence is assessed in the legislative domain, we design a rigorous framework to assess different levels of faithfulness of cognitive statements and create a benchmark dataset where we reveal insightful statistics. We design an annotation pipeline to create larger benchmarks for different LLMs automatically, and the resulting larger-scale CogniBench-L dataset can be used to train accurate cognitive hallucination detection model. We release our model and dataset at: https://github.com/FUTUREEEEEE/CogniBench
A Survey of Efficient Reasoning for Large Reasoning Models: Language, Multimodality, and Beyond
Mar 27, 2025Recent Large Reasoning Models (LRMs), such as DeepSeek-R1 and OpenAI o1, have demonstrated strong performance gains by scaling up the length of Chain-of-Thought (CoT) reasoning during inference. However, a growing concern lies in their tendency to produce excessively long reasoning traces, which are often filled with redundant content (e.g., repeated definitions), over-analysis of simple problems, and superficial exploration of multiple reasoning paths for harder tasks. This inefficiency introduces significant challenges for training, inference, and real-world deployment (e.g., in agent-based systems), where token economy is critical. In this survey, we provide a comprehensive overview of recent efforts aimed at improving reasoning efficiency in LRMs, with a particular focus on the unique challenges that arise in this new paradigm. We identify common patterns of inefficiency, examine methods proposed across the LRM lifecycle, i.e., from pretraining to inference, and discuss promising future directions for research. To support ongoing development, we also maintain a real-time GitHub repository tracking recent progress in the field. We hope this survey serves as a foundation for further exploration and inspires innovation in this rapidly evolving area.
Linear-MoE: Linear Sequence Modeling Meets Mixture-of-Experts
Mar 07, 2025
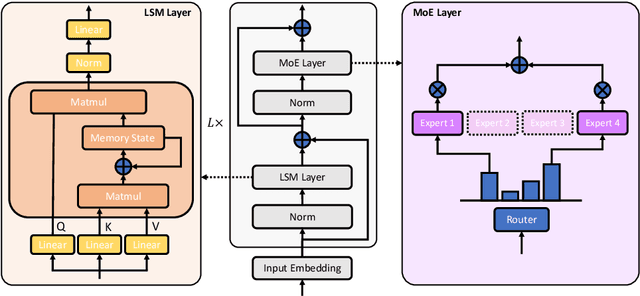
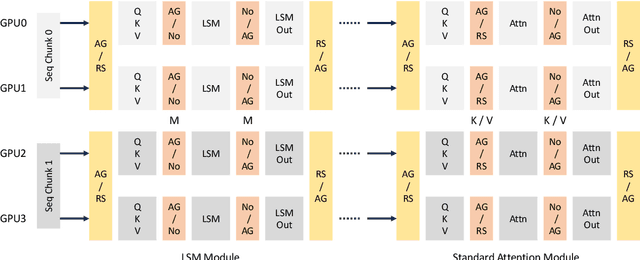
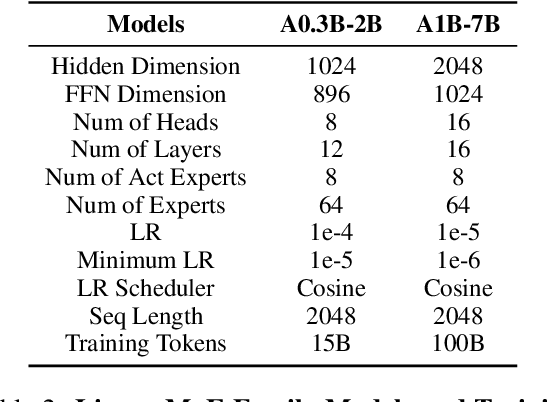
Linear Sequence Modeling (LSM) like linear attention, state space models and linear RNNs, and Mixture-of-Experts (MoE) have recently emerged as significant architectural improvements. In this paper, we introduce Linear-MoE, a production-level system for modeling and training large-scale models that integrate LSM with MoE. Linear-MoE leverages the advantages of both LSM modules for linear-complexity sequence modeling and MoE layers for sparsely activation, aiming to offer high performance with efficient training. The Linear-MoE system comprises: 1) Modeling subsystem, which provides a unified framework supporting all instances of LSM. and 2) Training subsystem, which facilitates efficient training by incorporating various advanced parallelism technologies, particularly Sequence Parallelism designed for Linear-MoE models. Additionally, we explore hybrid models that combine Linear-MoE layers with standard Transformer-MoE layers with its Sequence Parallelism to further enhance model flexibility and performance. Evaluations on two model series, A0.3B-2B and A1B-7B, demonstrate Linear-MoE achieves efficiency gains while maintaining competitive performance on various benchmarks, showcasing its potential as a next-generation foundational model architecture. Code: https://github.com/OpenSparseLLMs/Linear-MoE.
Liger: Linearizing Large Language Models to Gated Recurrent Structures
Mar 03, 2025



Transformers with linear recurrent modeling offer linear-time training and constant-memory inference. Despite their demonstrated efficiency and performance, pretraining such non-standard architectures from scratch remains costly and risky. The linearization of large language models (LLMs) transforms pretrained standard models into linear recurrent structures, enabling more efficient deployment. However, current linearization methods typically introduce additional feature map modules that require extensive fine-tuning and overlook the gating mechanisms used in state-of-the-art linear recurrent models. To address these issues, this paper presents Liger, short for Linearizing LLMs to gated recurrent structures. Liger is a novel approach for converting pretrained LLMs into gated linear recurrent models without adding extra parameters. It repurposes the pretrained key matrix weights to construct diverse gating mechanisms, facilitating the formation of various gated recurrent structures while avoiding the need to train additional components from scratch. Using lightweight fine-tuning with Low-Rank Adaptation (LoRA), Liger restores the performance of the linearized gated recurrent models to match that of the original LLMs. Additionally, we introduce Liger Attention, an intra-layer hybrid attention mechanism, which significantly recovers 93\% of the Transformer-based LLM at 0.02\% pre-training tokens during the linearization process, achieving competitive results across multiple benchmarks, as validated on models ranging from 1B to 8B parameters. Code is available at https://github.com/OpenSparseLLMs/Linearization.
MoM: Linear Sequence Modeling with Mixture-of-Memories
Feb 19, 2025



Linear sequence modeling methods, such as linear attention, state space modeling, and linear RNNs, offer significant efficiency improvements by reducing the complexity of training and inference. However, these methods typically compress the entire input sequence into a single fixed-size memory state, which leads to suboptimal performance on recall-intensive downstream tasks. Drawing inspiration from neuroscience, particularly the brain's ability to maintain robust long-term memory while mitigating "memory interference", we introduce a novel architecture called Mixture-of-Memories (MoM). MoM utilizes multiple independent memory states, with a router network directing input tokens to specific memory states. This approach greatly enhances the overall memory capacity while minimizing memory interference. As a result, MoM performs exceptionally well on recall-intensive tasks, surpassing existing linear sequence modeling techniques. Despite incorporating multiple memory states, the computation of each memory state remains linear in complexity, allowing MoM to retain the linear-complexity advantage during training, while constant-complexity during inference. Our experimental results show that MoM significantly outperforms current linear sequence models on downstream language tasks, particularly recall-intensive tasks, and even achieves performance comparable to Transformer models. The code is released at https://github.com/OpenSparseLLMs/MoM and is also released as a part of https://github.com/OpenSparseLLMs/Linear-MoE.
LASP-2: Rethinking Sequence Parallelism for Linear Attention and Its Hybrid
Feb 11, 2025



Linear sequence modeling approaches, such as linear attention, provide advantages like linear-time training and constant-memory inference over sequence lengths. However, existing sequence parallelism (SP) methods are either not optimized for the right-product-first feature of linear attention or use a ring-style communication strategy, which results in lower computation parallelism, limits their scalability for longer sequences in distributed systems. In this paper, we introduce LASP-2, a new SP method to enhance both communication and computation parallelism when training linear attention transformer models with very-long input sequences. Compared to previous work LASP, LASP-2 rethinks the minimal communication requirement for SP on linear attention layers, reorganizes the whole communication-computation workflow of LASP. In this way, only one single AllGather collective communication is needed on intermediate memory states, whose sizes are independent of the sequence length, leading to significant improvements of both communication and computation parallelism, as well as their overlap. Additionally, we extend LASP-2 to LASP-2H by applying similar communication redesign to standard attention modules, offering an efficient SP solution for hybrid models that blend linear and standard attention layers. Our evaluation on a Linear-Llama3 model, a variant of Llama3 with linear attention replacing standard attention, demonstrates the effectiveness of LASP-2 and LASP-2H. Specifically, LASP-2 achieves training speed improvements of 15.2% over LASP and 36.6% over Ring Attention, with a sequence length of 2048K across 64 GPUs. The Code is released as a part of: https://github.com/OpenSparseLLMs/Linear-MoE.
MiniMax-01: Scaling Foundation Models with Lightning Attention
Jan 14, 2025We introduce MiniMax-01 series, including MiniMax-Text-01 and MiniMax-VL-01, which are comparable to top-tier models while offering superior capabilities in processing longer contexts. The core lies in lightning attention and its efficient scaling. To maximize computational capacity, we integrate it with Mixture of Experts (MoE), creating a model with 32 experts and 456 billion total parameters, of which 45.9 billion are activated for each token. We develop an optimized parallel strategy and highly efficient computation-communication overlap techniques for MoE and lightning attention. This approach enables us to conduct efficient training and inference on models with hundreds of billions of parameters across contexts spanning millions of tokens. The context window of MiniMax-Text-01 can reach up to 1 million tokens during training and extrapolate to 4 million tokens during inference at an affordable cost. Our vision-language model, MiniMax-VL-01 is built through continued training with 512 billion vision-language tokens. Experiments on both standard and in-house benchmarks show that our models match the performance of state-of-the-art models like GPT-4o and Claude-3.5-Sonnet while offering 20-32 times longer context window. We publicly release MiniMax-01 at https://github.com/MiniMax-AI.