 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgecuRoboV2: Dynamics-Aware Motion Generation with Depth-Fused Distance Fields for High-DoF Robots
Mar 05, 2026Effective robot autonomy requires motion generation that is safe, feasible, and reactive. Current methods are fragmented: fast planners output physically unexecutable trajectories, reactive controllers struggle with high-fidelity perception, and existing solvers fail on high-DoF systems. We present cuRoboV2, a unified framework with three key innovations: (1) B-spline trajectory optimization that enforces smoothness and torque limits; (2) a GPU-native TSDF/ESDF perception pipeline that generates dense signed distance fields covering the full workspace, unlike existing methods that only provide distances within sparsely allocated blocks, up to 10x faster and in 8x less memory than the state-of-the-art at manipulation scale, with up to 99% collision recall; and (3) scalable GPU-native whole-body computation, namely topology-aware kinematics, differentiable inverse dynamics, and map-reduce self-collision, that achieves up to 61x speedup while also extending to high-DoF humanoids (where previous GPU implementations fail). On benchmarks, cuRoboV2 achieves 99.7% success under 3kg payload (where baselines achieve only 72--77%), 99.6% collision-free IK on a 48-DoF humanoid (where prior methods fail entirely), and 89.5% retargeting constraint satisfaction (vs. 61% for PyRoki); these collision-free motions yield locomotion policies with 21% lower tracking error than PyRoki and 12x lower cross-seed variance than mink. A ground-up codebase redesign for discoverability enabled LLM coding assistants to author up to 73% of new modules, including hand-optimized CUDA kernels, demonstrating that well-structured robotics code can unlock productive human--LLM collaboration. Together, these advances provide a unified, dynamics-aware motion generation stack that scales from single-arm manipulators to full humanoids.
CARI4D: Category Agnostic 4D Reconstruction of Human-Object Interaction
Dec 12, 2025Accurate capture of human-object interaction from ubiquitous sensors like RGB cameras is important for applications in human understanding, gaming, and robot learning. However, inferring 4D interactions from a single RGB view is highly challenging due to the unknown object and human information, depth ambiguity, occlusion, and complex motion, which hinder consistent 3D and temporal reconstruction. Previous methods simplify the setup by assuming ground truth object template or constraining to a limited set of object categories. We present CARI4D, the first category-agnostic method that reconstructs spatially and temporarily consistent 4D human-object interaction at metric scale from monocular RGB videos. To this end, we propose a pose hypothesis selection algorithm that robustly integrates the individual predictions from foundation models, jointly refine them through a learned render-and-compare paradigm to ensure spatial, temporal and pixel alignment, and finally reasoning about intricate contacts for further refinement satisfying physical constraints. Experiments show that our method outperforms prior art by 38% on in-distribution dataset and 36% on unseen dataset in terms of reconstruction error. Our model generalizes beyond the training categories and thus can be applied zero-shot to in-the-wild internet videos. Our code and pretrained models will be publicly released.
Fast-FoundationStereo: Real-Time Zero-Shot Stereo Matching
Dec 11, 2025Stereo foundation models achieve strong zero-shot generalization but remain computationally prohibitive for real-time applications. Efficient stereo architectures, on the other hand, sacrifice robustness for speed and require costly per-domain fine-tuning. To bridge this gap, we present Fast-FoundationStereo, a family of architectures that achieve, for the first time, strong zero-shot generalization at real-time frame rate. We employ a divide-and-conquer acceleration strategy with three components: (1) knowledge distillation to compress the hybrid backbone into a single efficient student; (2) blockwise neural architecture search for automatically discovering optimal cost filtering designs under latency budgets, reducing search complexity exponentially; and (3) structured pruning for eliminating redundancy in the iterative refinement module. Furthermore, we introduce an automatic pseudo-labeling pipeline used to curate 1.4M in-the-wild stereo pairs to supplement synthetic training data and facilitate knowledge distillation. The resulting model can run over 10x faster than FoundationStereo while closely matching its zero-shot accuracy, thus establishing a new state-of-the-art among real-time methods. Project page: https://nvlabs.github.io/Fast-FoundationStereo/
GraspGen: A Diffusion-based Framework for 6-DOF Grasping with On-Generator Training
Jul 17, 2025Grasping is a fundamental robot skill, yet despite significant research advancements, learning-based 6-DOF grasping approaches are still not turnkey and struggle to generalize across different embodiments and in-the-wild settings. We build upon the recent success on modeling the object-centric grasp generation process as an iterative diffusion process. Our proposed framework, GraspGen, consists of a DiffusionTransformer architecture that enhances grasp generation, paired with an efficient discriminator to score and filter sampled grasps. We introduce a novel and performant on-generator training recipe for the discriminator. To scale GraspGen to both objects and grippers, we release a new simulated dataset consisting of over 53 million grasps. We demonstrate that GraspGen outperforms prior methods in simulations with singulated objects across different grippers, achieves state-of-the-art performance on the FetchBench grasping benchmark, and performs well on a real robot with noisy visual observations.
3D-Generalist: Self-Improving Vision-Language-Action Models for Crafting 3D Worlds
Jul 09, 2025Despite large-scale pretraining endowing models with language and vision reasoning capabilities, improving their spatial reasoning capability remains challenging due to the lack of data grounded in the 3D world. While it is possible for humans to manually create immersive and interactive worlds through 3D graphics, as seen in applications such as VR, gaming, and robotics, this process remains highly labor-intensive. In this paper, we propose a scalable method for generating high-quality 3D environments that can serve as training data for foundation models. We recast 3D environment building as a sequential decision-making problem, employing Vision-Language-Models (VLMs) as policies that output actions to jointly craft a 3D environment's layout, materials, lighting, and assets. Our proposed framework, 3D-Generalist, trains VLMs to generate more prompt-aligned 3D environments via self-improvement fine-tuning. We demonstrate the effectiveness of 3D-Generalist and the proposed training strategy in generating simulation-ready 3D environments. Furthermore, we demonstrate its quality and scalability in synthetic data generation by pretraining a vision foundation model on the generated data. After fine-tuning the pre-trained model on downstream tasks, we show that it surpasses models pre-trained on meticulously human-crafted synthetic data and approaches results achieved with real data orders of magnitude larger.
RaySt3R: Predicting Novel Depth Maps for Zero-Shot Object Completion
Jun 05, 20253D shape completion has broad applications in robotics, digital twin reconstruction, and extended reality (XR). Although recent advances in 3D object and scene completion have achieved impressive results, existing methods lack 3D consistency, are computationally expensive, and struggle to capture sharp object boundaries. Our work (RaySt3R) addresses these limitations by recasting 3D shape completion as a novel view synthesis problem. Specifically, given a single RGB-D image and a novel viewpoint (encoded as a collection of query rays), we train a feedforward transformer to predict depth maps, object masks, and per-pixel confidence scores for those query rays. RaySt3R fuses these predictions across multiple query views to reconstruct complete 3D shapes. We evaluate RaySt3R on synthetic and real-world datasets, and observe it achieves state-of-the-art performance, outperforming the baselines on all datasets by up to 44% in 3D chamfer distance. Project page: https://rayst3r.github.io
BOP Challenge 2024 on Model-Based and Model-Free 6D Object Pose Estimation
Apr 03, 2025We present the evaluation methodology, datasets and results of the BOP Challenge 2024, the sixth in a series of public competitions organized to capture the state of the art in 6D object pose estimation and related tasks. In 2024, our goal was to transition BOP from lab-like setups to real-world scenarios. First, we introduced new model-free tasks, where no 3D object models are available and methods need to onboard objects just from provided reference videos. Second, we defined a new, more practical 6D object detection task where identities of objects visible in a test image are not provided as input. Third, we introduced new BOP-H3 datasets recorded with high-resolution sensors and AR/VR headsets, closely resembling real-world scenarios. BOP-H3 include 3D models and onboarding videos to support both model-based and model-free tasks. Participants competed on seven challenge tracks, each defined by a task, object onboarding setup, and dataset group. Notably, the best 2024 method for model-based 6D localization of unseen objects (FreeZeV2.1) achieves 22% higher accuracy on BOP-Classic-Core than the best 2023 method (GenFlow), and is only 4% behind the best 2023 method for seen objects (GPose2023) although being significantly slower (24.9 vs 2.7s per image). A more practical 2024 method for this task is Co-op which takes only 0.8s per image and is 25X faster and 13% more accurate than GenFlow. Methods have a similar ranking on 6D detection as on 6D localization but higher run time. On model-based 2D detection of unseen objects, the best 2024 method (MUSE) achieves 21% relative improvement compared to the best 2023 method (CNOS). However, the 2D detection accuracy for unseen objects is still noticealy (-53%) behind the accuracy for seen objects (GDet2023). The online evaluation system stays open and is available at http://bop.felk.cvut.cz/
RoboSpatial: Teaching Spatial Understanding to 2D and 3D Vision-Language Models for Robotics
Nov 25, 2024

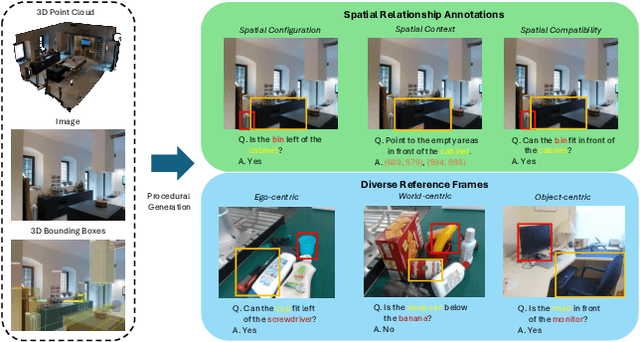

Spatial understanding is a crucial capability for robots to make grounded decisions based on their environment. This foundational skill enables robots not only to perceive their surroundings but also to reason about and interact meaningfully within the world. In modern robotics, these capabilities are taken on by visual language models, and they face significant challenges when applied to spatial reasoning context due to their training data sources. These sources utilize general-purpose image datasets, and they often lack sophisticated spatial scene understanding capabilities. For example, the datasets do not address reference frame comprehension - spatial relationships require clear contextual understanding, whether from an ego-centric, object-centric, or world-centric perspective, which allow for effective real-world interaction. To address this issue, we introduce RoboSpatial, a large-scale spatial understanding dataset consisting of real indoor and tabletop scenes captured as 3D scans and egocentric images, annotated with rich spatial information relevant to robotics. The dataset includes 1M images, 5K 3D scans, and 3M annotated spatial relationships, with paired 2D egocentric images and 3D scans to make it both 2D and 3D ready. Our experiments show that models trained with RoboSpatial outperform baselines on downstream tasks such as spatial affordance prediction, spatial relationship prediction, and robotics manipulation.
SPOT: SE(3) Pose Trajectory Diffusion for Object-Centric Manipulation
Nov 01, 2024



We introduce SPOT, an object-centric imitation learning framework. The key idea is to capture each task by an object-centric representation, specifically the SE(3) object pose trajectory relative to the target. This approach decouples embodiment actions from sensory inputs, facilitating learning from various demonstration types, including both action-based and action-less human hand demonstrations, as well as cross-embodiment generalization. Additionally, object pose trajectories inherently capture planning constraints from demonstrations without the need for manually crafted rules. To guide the robot in executing the task, the object trajectory is used to condition a diffusion policy. We show improvement compared to prior work on RLBench simulated tasks. In real-world evaluation, using only eight demonstrations shot on an iPhone, our approach completed all tasks while fully complying with task constraints. Project page: https://nvlabs.github.io/object_centric_diffusion
GRS: Generating Robotic Simulation Tasks from Real-World Images
Oct 20, 2024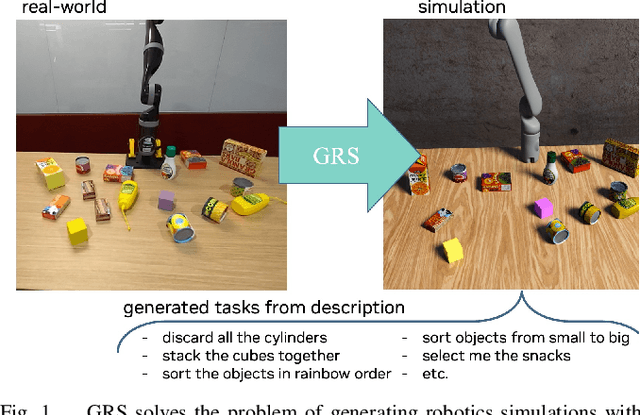
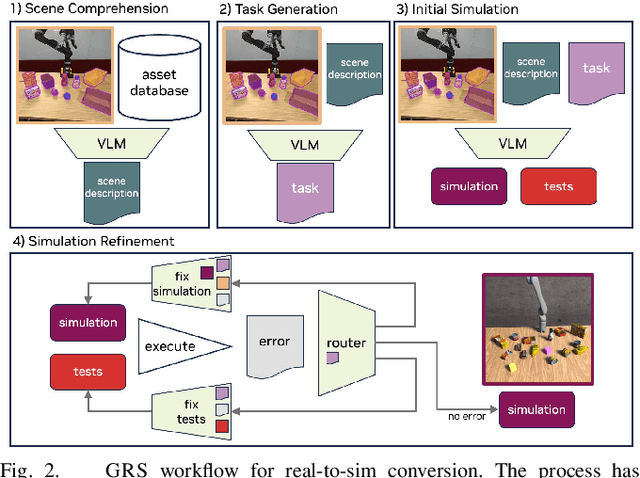


We introduce GRS (Generating Robotic Simulation tasks), a novel system to address the challenge of real-to-sim in robotics, computer vision, and AR/VR. GRS enables the creation of digital twin simulations from single real-world RGB-D observations, complete with diverse, solvable tasks for virtual agent training. We use state-of-the-art vision-language models (VLMs) to achieve a comprehensive real-to-sim pipeline. GRS operates in three stages: 1) scene comprehension using SAM2 for object segmentation and VLMs for object description, 2) matching identified objects with simulation-ready assets, and 3) generating contextually appropriate robotic tasks. Our approach ensures simulations align with task specifications by generating test suites designed to verify adherence to the task specification. We introduce a router that iteratively refines the simulation and test code to ensure the simulation is solvable by a robot policy while remaining aligned to the task specification. Our experiments demonstrate the system's efficacy in accurately identifying object correspondence, which allows us to generate task environments that closely match input environments, and enhance automated simulation task generation through our novel router mechanism.