 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoLo: A Physical Orchestrator for Open-Vocabulary Long-Horizon Manipulation
Jun 05, 2026Open-vocabulary long-horizon manipulation requires robots to reason over flexible instructions and complex multi-object scenes while adaptively planning, executing, monitoring, and recovering from failures. We address these demands with a closed agent loop in which a VLM orchestrates heterogeneous robot capabilities as interruptible tools. Unlike in virtual AI agents, the timing of decisions, actions and tool calls is important in a physical world that does not pause for reasoning. We refer to this setting as Physical Orchestration, and propose VoLoAgent, a VLM that plans, monitors, and recovers by treating a VLA/WAM as an interruptible tool it steers mid-rollout alongside vision models and action primitives. To evaluate these long-horizon capabilities, we introduce RoboVoLo, a high-fidelity benchmark for open-vocabulary long-horizon manipulation across common sense, memory/state tracking, complex references, and world knowledge, with both task-level success and failure-mode diagnostics. Experiments show VoLoAgent substantially outperforms single VLA/VLM or tool-based systems, with validation on real-robot experiments. Project page: https://chicychen.github.io/VoLo/
Effective Multi-sensor Conditioning for Street-view Novel-view Synthesis
Jun 01, 2026Modern vehicle platforms are equipped with a rich sensor suite, including LiDAR, calibrated multi-camera rigs, and accurate ego-motion, that in principle offers strong signal for re-rendering a driving scene from novel viewpoints. A growing line of recent work leverages video diffusion models for this task, using their generative priors to synthesize plausible novel views from sparse vehicle observations. In practice, however, existing methods exploit only a fragment of this signal, and their quality tends to degrade as the target trajectory departs from the recorded driving path. We argue that this is fundamentally a multi-sensor fusion problem: sparse LiDAR reprojections supply accurate but incomplete metric geometry, surround-view reference imagery supplies dense appearance but no metric depth, and camera poses tie the two together across views. We introduce StreetNVS, a video diffusion framework that jointly conditions on all three signals through a Reference-Enhanced Camera Attention module based on a relative ray-level positional encoding. We develop a two-stage curriculum training strategy that gradually exposes the model to increasingly sparse LiDAR. On the Waymo Open Dataset, StreetNVS substantially outperforms state-of-the-art baselines under sparse LiDAR conditioning, matches methods that rely on 10-100 times denser point clouds. We further show capabilities of synthesizing coherent videos along extreme out-of-trajectory paths such as elevation, lane-shift, pullback, and rotation. Our website: https://streetnvs.github.io
Why Far Looks Up: Probing Spatial Representation in Vision-Language Models
May 28, 2026Vision-language models (VLMs) achieve strong performance on spatial reasoning benchmarks, yet it remains unclear whether this reflects structured 3D understanding or reliance on statistical shortcuts in natural images. We introduce a representation-level analysis framework that constructs minimal contrastive pairs to measure how spatial axes are organized and disentangled within VLM embeddings. Our analysis across multiple model families reveals a consistent vertical-distance entanglement: models conflate vertical image position with distance, mirroring the perspective bias of natural photographs. This bias produces a significant accuracy gap between perspective-consistent and counter-heuristic examples, and intensifies under data scaling even as overall benchmark accuracy improves. We further show that models with similar benchmark scores can exhibit different internal representations, and that these differences predict accuracy and robustness across diverse spatial reasoning benchmarks. To isolate this bias from evaluation-set skew, we introduce SpatialTunnel, a synthetic benchmark designed to expose spatial shortcut biases by removing common correlations present in natural images. Experiments confirm that the entanglement is model-intrinsic, and that models with well-separated spatial axes exhibit greater robustness, suggesting that well-structured spatial representations lead to more reliable spatial reasoning across diverse benchmarks. Code and benchmark are available on the project page: https://cheolhong0916.github.io/whyfarlooksup.github.io/.
RoboLab: A High-Fidelity Simulation Benchmark for Analysis of Task Generalist Policies
Apr 10, 2026The pursuit of general-purpose robotics has yielded impressive foundation models, yet simulation-based benchmarking remains a bottleneck due to rapid performance saturation and a lack of true generalization testing. Existing benchmarks often exhibit significant domain overlap between training and evaluation, trivializing success rates and obscuring insights into robustness. We introduce RoboLab, a simulation benchmarking framework designed to address these challenges. Concretely, our framework is designed to answer two questions: (1) to what extent can we understand the performance of a real-world policy by analyzing its behavior in simulation, and (2) which external factors most strongly affect that behavior under controlled perturbations. First, RoboLab enables human-authored and LLM-enabled generation of scenes and tasks in a robot- and policy-agnostic manner within a physically realistic and photorealistic simulation. With this, we propose the RoboLab-120 benchmark, consisting of 120 tasks categorized into three competency axes: visual, procedural, relational competency, across three difficulty levels. Second, we introduce a systematic analysis of real-world policies that quantify both their performance and the sensitivity of their behavior to controlled perturbations, indicating that high-fidelity simulation can serve as a proxy for analyzing performance and its dependence on external factors. Evaluation with RoboLab exposes significant performance gap in current state-of-the-art models. By providing granular metrics and a scalable toolset, RoboLab offers a scalable framework for evaluating the true generalization capabilities of task-generalist robotic policies.
MME-CoF-Pro: Evaluating Reasoning Coherence in Video Generative Models with Text and Visual Hints
Mar 20, 2026Video generative models show emerging reasoning behaviors. It is essential to ensure that generated events remain causally consistent across frames for reliable deployment, a property we define as reasoning coherence. To bridge the gap in literature for missing reasoning coherence evaluation, we propose MME-CoF-Pro, a comprehensive video reasoning benchmark to assess reasoning coherence in video models. Specifically, MME-CoF-Pro contains 303 samples across 16 categories, ranging from visual logical to scientific reasoning. It introduces Reasoning Score as evaluation metric for assessing process-level necessary intermediate reasoning steps, and includes three evaluation settings, (a) no hint (b) text hint and (c) visual hint, enabling a controlled investigation into the underlying mechanisms of reasoning hint guidance. Evaluation results in 7 open and closed-source video models reveals insights including: (1) Video generative models exhibit weak reasoning coherence, decoupled from generation quality. (2) Text hints boost apparent correctness but often cause inconsistency and hallucinated reasoning (3) Visual hints benefit structured perceptual tasks but struggle with fine-grained perception. Website: https://video-reasoning-coherence.github.io/
Tactile Modality Fusion for Vision-Language-Action Models
Mar 15, 2026We propose TacFiLM, a lightweight modality-fusion approach that integrates visual-tactile signals into vision-language-action (VLA) models. While recent advances in VLA models have introduced robot policies that are both generalizable and semantically grounded, these models mainly rely on vision-based perception. Vision alone, however, cannot capture the complex interaction dynamics that occur during contact-rich manipulation, including contact forces, surface friction, compliance, and shear. While recent attempts to integrate tactile signals into VLA models often increase complexity through token concatenation or large-scale pretraining, the heavy computational demands of behavioural models necessitate more lightweight fusion strategies. To address these challenges, TacFiLM outlines a post-training finetuning approach that conditions intermediate visual features on pretrained tactile representations using feature-wise linear modulation (FiLM). Experimental results on insertion tasks demonstrate consistent improvements in success rate, direct insertion performance, completion time, and force stability across both in-distribution and out-of-distribution tasks. Together, these results support our method as an effective approach to integrating tactile signals into VLA models, improving contact-rich manipulation behaviours.
DT-NVS: Diffusion Transformers for Novel View Synthesis
Nov 11, 2025Generating novel views of a natural scene, e.g., every-day scenes both indoors and outdoors, from a single view is an under-explored problem, even though it is an organic extension to the object-centric novel view synthesis. Existing diffusion-based approaches focus rather on small camera movements in real scenes or only consider unnatural object-centric scenes, limiting their potential applications in real-world settings. In this paper we move away from these constrained regimes and propose a 3D diffusion model trained with image-only losses on a large-scale dataset of real-world, multi-category, unaligned, and casually acquired videos of everyday scenes. We propose DT-NVS, a 3D-aware diffusion model for generalized novel view synthesis that exploits a transformer-based architecture backbone. We make significant contributions to transformer and self-attention architectures to translate images to 3d representations, and novel camera conditioning strategies to allow training on real-world unaligned datasets. In addition, we introduce a novel training paradigm swapping the role of reference frame between the conditioning image and the sampled noisy input. We evaluate our approach on the 3D task of generalized novel view synthesis from a single input image and show improvements over state-of-the-art 3D aware diffusion models and deterministic approaches, while generating diverse outputs.
3D-Generalist: Self-Improving Vision-Language-Action Models for Crafting 3D Worlds
Jul 09, 2025Despite large-scale pretraining endowing models with language and vision reasoning capabilities, improving their spatial reasoning capability remains challenging due to the lack of data grounded in the 3D world. While it is possible for humans to manually create immersive and interactive worlds through 3D graphics, as seen in applications such as VR, gaming, and robotics, this process remains highly labor-intensive. In this paper, we propose a scalable method for generating high-quality 3D environments that can serve as training data for foundation models. We recast 3D environment building as a sequential decision-making problem, employing Vision-Language-Models (VLMs) as policies that output actions to jointly craft a 3D environment's layout, materials, lighting, and assets. Our proposed framework, 3D-Generalist, trains VLMs to generate more prompt-aligned 3D environments via self-improvement fine-tuning. We demonstrate the effectiveness of 3D-Generalist and the proposed training strategy in generating simulation-ready 3D environments. Furthermore, we demonstrate its quality and scalability in synthetic data generation by pretraining a vision foundation model on the generated data. After fine-tuning the pre-trained model on downstream tasks, we show that it surpasses models pre-trained on meticulously human-crafted synthetic data and approaches results achieved with real data orders of magnitude larger.
BOP Challenge 2024 on Model-Based and Model-Free 6D Object Pose Estimation
Apr 03, 2025We present the evaluation methodology, datasets and results of the BOP Challenge 2024, the sixth in a series of public competitions organized to capture the state of the art in 6D object pose estimation and related tasks. In 2024, our goal was to transition BOP from lab-like setups to real-world scenarios. First, we introduced new model-free tasks, where no 3D object models are available and methods need to onboard objects just from provided reference videos. Second, we defined a new, more practical 6D object detection task where identities of objects visible in a test image are not provided as input. Third, we introduced new BOP-H3 datasets recorded with high-resolution sensors and AR/VR headsets, closely resembling real-world scenarios. BOP-H3 include 3D models and onboarding videos to support both model-based and model-free tasks. Participants competed on seven challenge tracks, each defined by a task, object onboarding setup, and dataset group. Notably, the best 2024 method for model-based 6D localization of unseen objects (FreeZeV2.1) achieves 22% higher accuracy on BOP-Classic-Core than the best 2023 method (GenFlow), and is only 4% behind the best 2023 method for seen objects (GPose2023) although being significantly slower (24.9 vs 2.7s per image). A more practical 2024 method for this task is Co-op which takes only 0.8s per image and is 25X faster and 13% more accurate than GenFlow. Methods have a similar ranking on 6D detection as on 6D localization but higher run time. On model-based 2D detection of unseen objects, the best 2024 method (MUSE) achieves 21% relative improvement compared to the best 2023 method (CNOS). However, the 2D detection accuracy for unseen objects is still noticealy (-53%) behind the accuracy for seen objects (GDet2023). The online evaluation system stays open and is available at http://bop.felk.cvut.cz/
RoboSpatial: Teaching Spatial Understanding to 2D and 3D Vision-Language Models for Robotics
Nov 25, 2024

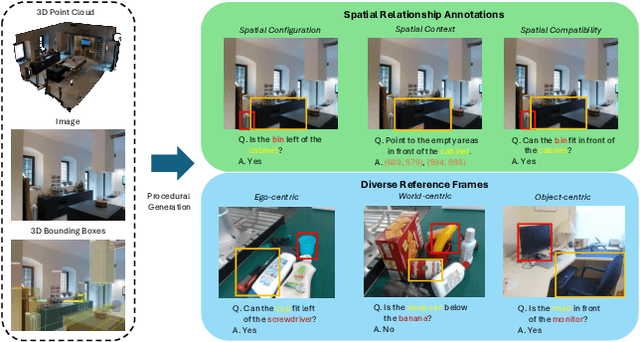

Spatial understanding is a crucial capability for robots to make grounded decisions based on their environment. This foundational skill enables robots not only to perceive their surroundings but also to reason about and interact meaningfully within the world. In modern robotics, these capabilities are taken on by visual language models, and they face significant challenges when applied to spatial reasoning context due to their training data sources. These sources utilize general-purpose image datasets, and they often lack sophisticated spatial scene understanding capabilities. For example, the datasets do not address reference frame comprehension - spatial relationships require clear contextual understanding, whether from an ego-centric, object-centric, or world-centric perspective, which allow for effective real-world interaction. To address this issue, we introduce RoboSpatial, a large-scale spatial understanding dataset consisting of real indoor and tabletop scenes captured as 3D scans and egocentric images, annotated with rich spatial information relevant to robotics. The dataset includes 1M images, 5K 3D scans, and 3M annotated spatial relationships, with paired 2D egocentric images and 3D scans to make it both 2D and 3D ready. Our experiments show that models trained with RoboSpatial outperform baselines on downstream tasks such as spatial affordance prediction, spatial relationship prediction, and robotics manipulation.