 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo VLMs Perceive or Recall? Probing Visual Perception vs. Memory with Classic Visual Illusions
Jan 29, 2026Large Vision-Language Models (VLMs) often answer classic visual illusions "correctly" on original images, yet persist with the same responses when illusion factors are inverted, even though the visual change is obvious to humans. This raises a fundamental question: do VLMs perceive visual changes or merely recall memorized patterns? While several studies have noted this phenomenon, the underlying causes remain unclear. To move from observations to systematic understanding, this paper introduces VI-Probe, a controllable visual-illusion framework with graded perturbations and matched visual controls (without illusion inducer) that disentangles visually grounded perception from language-driven recall. Unlike prior work that focuses on averaged accuracy, we measure stability and sensitivity using Polarity-Flip Consistency, Template Fixation Index, and an illusion multiplier normalized against matched controls. Experiments across different families reveal that response persistence arises from heterogeneous causes rather than a single mechanism. For instance, GPT-5 exhibits memory override, Claude-Opus-4.1 shows perception-memory competition, while Qwen variants suggest visual-processing limits. Our findings challenge single-cause views and motivate probing-based evaluation that measures both knowledge and sensitivity to controlled visual change. Data and code are available at https://sites.google.com/view/vi-probe/.
Transductive Visual Programming: Evolving Tool Libraries from Experience for Spatial Reasoning
Dec 24, 2025
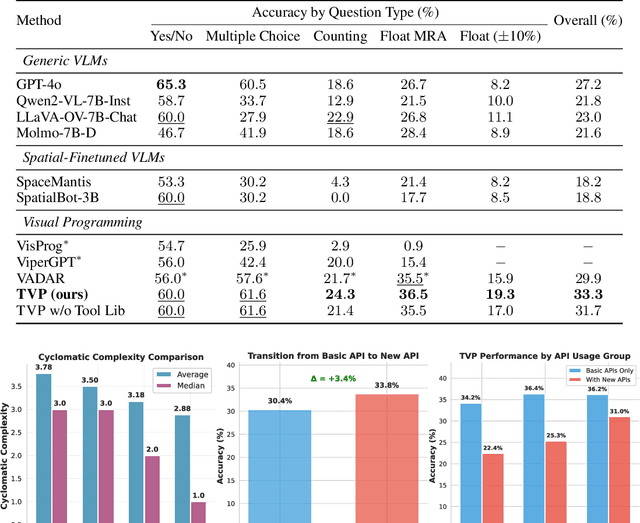
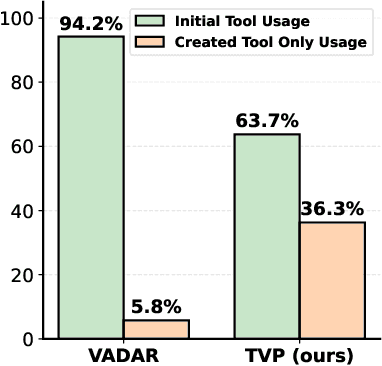
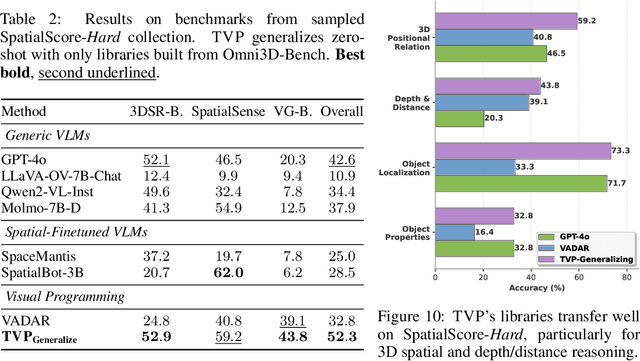
Spatial reasoning in 3D scenes requires precise geometric calculations that challenge vision-language models. Visual programming addresses this by decomposing problems into steps calling specialized tools, yet existing methods rely on either fixed toolsets or speculative tool induction before solving problems, resulting in suboptimal programs and poor utilization of induced tools. We present Transductive Visual Programming (TVP), a novel framework that builds new tools from its own experience rather than speculation. TVP first solves problems using basic tools while accumulating experiential solutions into an Example Library, then abstracts recurring patterns from these programs into reusable higher-level tools for an evolving Tool Library. This allows TVP to tackle new problems with increasingly powerful tools learned from experience. On Omni3D-Bench, TVP achieves state-of-the-art performance, outperforming GPT-4o by 22% and the previous best visual programming system by 11%. Our transductively learned tools are used 5x more frequently as core program dependency than inductively created ones, demonstrating more effective tool discovery and reuse. The evolved tools also show strong generalization to unseen spatial tasks, achieving superior performance on benchmarks from SpatialScore-Hard collection without any testset-specific modification. Our work establishes experience-driven transductive tool creation as a powerful paradigm for building self-evolving visual programming agents that effectively tackle challenging spatial reasoning tasks. We release our code at https://transductive-visualprogram.github.io/.
3D-Generalist: Self-Improving Vision-Language-Action Models for Crafting 3D Worlds
Jul 09, 2025Despite large-scale pretraining endowing models with language and vision reasoning capabilities, improving their spatial reasoning capability remains challenging due to the lack of data grounded in the 3D world. While it is possible for humans to manually create immersive and interactive worlds through 3D graphics, as seen in applications such as VR, gaming, and robotics, this process remains highly labor-intensive. In this paper, we propose a scalable method for generating high-quality 3D environments that can serve as training data for foundation models. We recast 3D environment building as a sequential decision-making problem, employing Vision-Language-Models (VLMs) as policies that output actions to jointly craft a 3D environment's layout, materials, lighting, and assets. Our proposed framework, 3D-Generalist, trains VLMs to generate more prompt-aligned 3D environments via self-improvement fine-tuning. We demonstrate the effectiveness of 3D-Generalist and the proposed training strategy in generating simulation-ready 3D environments. Furthermore, we demonstrate its quality and scalability in synthetic data generation by pretraining a vision foundation model on the generated data. After fine-tuning the pre-trained model on downstream tasks, we show that it surpasses models pre-trained on meticulously human-crafted synthetic data and approaches results achieved with real data orders of magnitude larger.
Symmetrical Visual Contrastive Optimization: Aligning Vision-Language Models with Minimal Contrastive Images
Feb 19, 2025Recent studies have shown that Large Vision-Language Models (VLMs) tend to neglect image content and over-rely on language-model priors, resulting in errors in visually grounded tasks and hallucinations. We hypothesize that this issue arises because existing VLMs are not explicitly trained to generate texts that are accurately grounded in fine-grained image details. To enhance visual feedback during VLM training, we propose S-VCO (Symmetrical Visual Contrastive Optimization), a novel finetuning objective that steers the model toward capturing important visual details and aligning them with corresponding text tokens. To further facilitate this detailed alignment, we introduce MVC, a paired image-text dataset built by automatically filtering and augmenting visual counterfactual data to challenge the model with hard contrastive cases involving Minimal Visual Contrasts. Experiments show that our method consistently improves VLM performance across diverse benchmarks covering various abilities and domains, achieving up to a 22% reduction in hallucinations, and significant gains in vision-centric and general tasks. Notably, these improvements become increasingly pronounced in benchmarks with higher visual dependency. In short, S-VCO offers a significant enhancement of VLM's visually-dependent task performance while retaining or even improving the model's general abilities. We opensource our code at https://s-vco.github.io/
Knowledge-Aware Artifact Image Synthesis with LLM-Enhanced Prompting and Multi-Source Supervision
Dec 13, 2023



Ancient artifacts are an important medium for cultural preservation and restoration. However, many physical copies of artifacts are either damaged or lost, leaving a blank space in archaeological and historical studies that calls for artifact image generation techniques. Despite the significant advancements in open-domain text-to-image synthesis, existing approaches fail to capture the important domain knowledge presented in the textual description, resulting in errors in recreated images such as incorrect shapes and patterns. In this paper, we propose a novel knowledge-aware artifact image synthesis approach that brings lost historical objects accurately into their visual forms. We use a pretrained diffusion model as backbone and introduce three key techniques to enhance the text-to-image generation framework: 1) we construct prompts with explicit archaeological knowledge elicited from large language models (LLMs); 2) we incorporate additional textual guidance to correlated historical expertise in a contrastive manner; 3) we introduce further visual-semantic constraints on edge and perceptual features that enable our model to learn more intricate visual details of the artifacts. Compared to existing approaches, our proposed model produces higher-quality artifact images that align better with the implicit details and historical knowledge contained within written documents, thus achieving significant improvements across automatic metrics and in human evaluation. Our code and data are available at https://github.com/danielwusg/artifact_diffusion.
DiffuVST: Narrating Fictional Scenes with Global-History-Guided Denoising Models
Dec 12, 2023
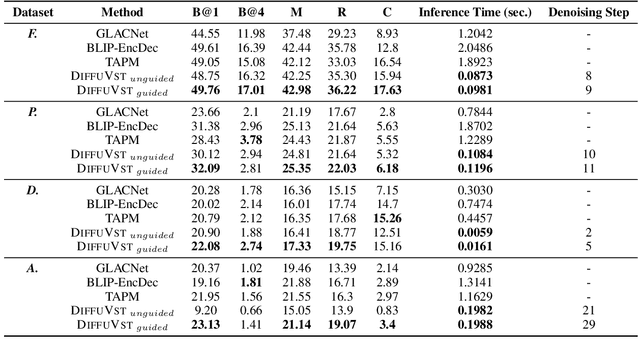
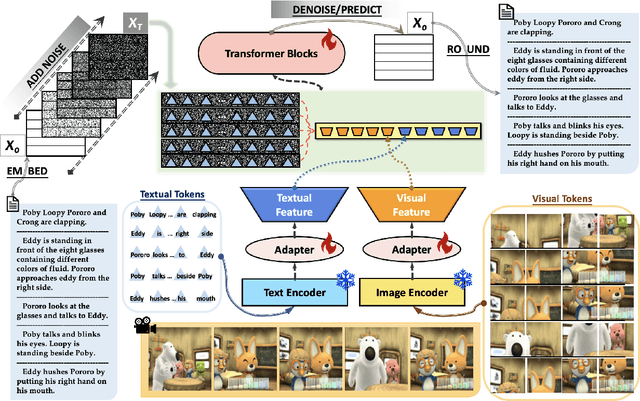
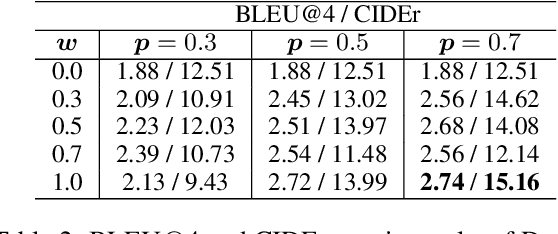
Recent advances in image and video creation, especially AI-based image synthesis, have led to the production of numerous visual scenes that exhibit a high level of abstractness and diversity. Consequently, Visual Storytelling (VST), a task that involves generating meaningful and coherent narratives from a collection of images, has become even more challenging and is increasingly desired beyond real-world imagery. While existing VST techniques, which typically use autoregressive decoders, have made significant progress, they suffer from low inference speed and are not well-suited for synthetic scenes. To this end, we propose a novel diffusion-based system DiffuVST, which models the generation of a series of visual descriptions as a single conditional denoising process. The stochastic and non-autoregressive nature of DiffuVST at inference time allows it to generate highly diverse narratives more efficiently. In addition, DiffuVST features a unique design with bi-directional text history guidance and multimodal adapter modules, which effectively improve inter-sentence coherence and image-to-text fidelity. Extensive experiments on the story generation task covering four fictional visual-story datasets demonstrate the superiority of DiffuVST over traditional autoregressive models in terms of both text quality and inference speed.
Self-Evolved Diverse Data Sampling for Efficient Instruction Tuning
Nov 14, 2023Enhancing the instruction-following ability of Large Language Models (LLMs) primarily demands substantial instruction-tuning datasets. However, the sheer volume of these imposes a considerable computational burden and annotation cost. To investigate a label-efficient instruction tuning method that allows the model itself to actively sample subsets that are equally or even more effective, we introduce a self-evolving mechanism DiverseEvol. In this process, a model iteratively augments its training subset to refine its own performance, without requiring any intervention from humans or more advanced LLMs. The key to our data sampling technique lies in the enhancement of diversity in the chosen subsets, as the model selects new data points most distinct from any existing ones according to its current embedding space. Extensive experiments across three datasets and benchmarks demonstrate the effectiveness of DiverseEvol. Our models, trained on less than 8% of the original dataset, maintain or improve performance compared with finetuning on full data. We also provide empirical evidence to analyze the importance of diversity in instruction data and the iterative scheme as opposed to one-time sampling. Our code is publicly available at https://github.com/OFA-Sys/DiverseEvol.git.
Qwen Technical Report
Sep 28, 2023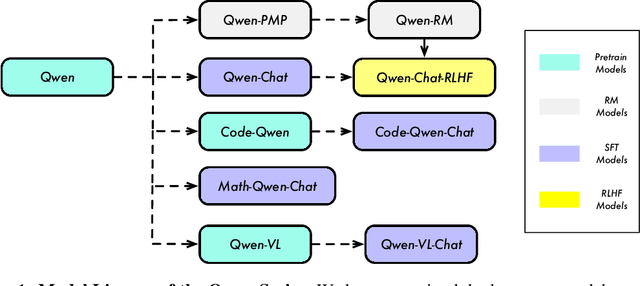

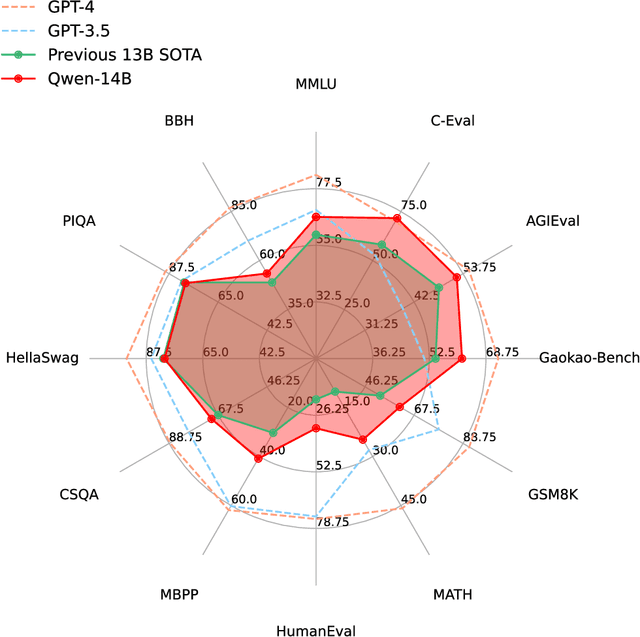
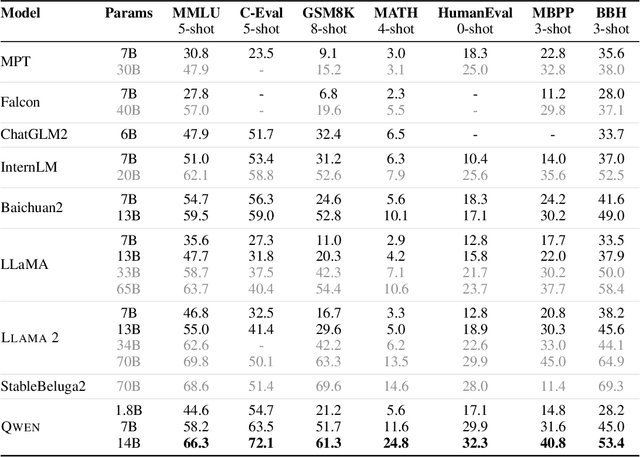
Large language models (LLMs) have revolutionized the field of artificial intelligence, enabling natural language processing tasks that were previously thought to be exclusive to humans. In this work, we introduce Qwen, the first installment of our large language model series. Qwen is a comprehensive language model series that encompasses distinct models with varying parameter counts. It includes Qwen, the base pretrained language models, and Qwen-Chat, the chat models finetuned with human alignment techniques. The base language models consistently demonstrate superior performance across a multitude of downstream tasks, and the chat models, particularly those trained using Reinforcement Learning from Human Feedback (RLHF), are highly competitive. The chat models possess advanced tool-use and planning capabilities for creating agent applications, showcasing impressive performance even when compared to bigger models on complex tasks like utilizing a code interpreter. Furthermore, we have developed coding-specialized models, Code-Qwen and Code-Qwen-Chat, as well as mathematics-focused models, Math-Qwen-Chat, which are built upon base language models. These models demonstrate significantly improved performance in comparison with open-source models, and slightly fall behind the proprietary models.