 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmni-Captioner: Data Pipeline, Models, and Benchmark for Omni Detailed Perception
Oct 14, 2025Fine-grained perception of multimodal information is critical for advancing human-AI interaction. With recent progress in audio-visual technologies, Omni Language Models (OLMs), capable of processing audio and video signals in parallel, have emerged as a promising paradigm for achieving richer understanding and reasoning. However, their capacity to capture and describe fine-grained details remains limited explored. In this work, we present a systematic and comprehensive investigation of omni detailed perception from the perspectives of the data pipeline, models, and benchmark. We first identify an inherent "co-growth" between detail and hallucination in current OLMs. To address this, we propose Omni-Detective, an agentic data generation pipeline integrating tool-calling, to autonomously produce highly detailed yet minimally hallucinatory multimodal data. Based on the data generated with Omni-Detective, we train two captioning models: Audio-Captioner for audio-only detailed perception, and Omni-Captioner for audio-visual detailed perception. Under the cascade evaluation protocol, Audio-Captioner achieves the best performance on MMAU and MMAR among all open-source models, surpassing Gemini 2.5 Flash and delivering performance comparable to Gemini 2.5 Pro. On existing detailed captioning benchmarks, Omni-Captioner sets a new state-of-the-art on VDC and achieves the best trade-off between detail and hallucination on the video-SALMONN 2 testset. Given the absence of a dedicated benchmark for omni detailed perception, we design Omni-Cloze, a novel cloze-style evaluation for detailed audio, visual, and audio-visual captioning that ensures stable, efficient, and reliable assessment. Experimental results and analysis demonstrate the effectiveness of Omni-Detective in generating high-quality detailed captions, as well as the superiority of Omni-Cloze in evaluating such detailed captions.
Qwen2.5-Omni Technical Report
Mar 26, 2025



In this report, we present Qwen2.5-Omni, an end-to-end multimodal model designed to perceive diverse modalities, including text, images, audio, and video, while simultaneously generating text and natural speech responses in a streaming manner. To enable the streaming of multimodal information inputs, both audio and visual encoders utilize a block-wise processing approach. To synchronize the timestamps of video inputs with audio, we organize the audio and video sequentially in an interleaved manner and propose a novel position embedding approach, named TMRoPE(Time-aligned Multimodal RoPE). To concurrently generate text and speech while avoiding interference between the two modalities, we propose \textbf{Thinker-Talker} architecture. In this framework, Thinker functions as a large language model tasked with text generation, while Talker is a dual-track autoregressive model that directly utilizes the hidden representations from the Thinker to produce audio tokens as output. Both the Thinker and Talker models are designed to be trained and inferred in an end-to-end manner. For decoding audio tokens in a streaming manner, we introduce a sliding-window DiT that restricts the receptive field, aiming to reduce the initial package delay. Qwen2.5-Omni is comparable with the similarly sized Qwen2.5-VL and outperforms Qwen2-Audio. Furthermore, Qwen2.5-Omni achieves state-of-the-art performance on multimodal benchmarks like Omni-Bench. Notably, Qwen2.5-Omni's performance in end-to-end speech instruction following is comparable to its capabilities with text inputs, as evidenced by benchmarks such as MMLU and GSM8K. As for speech generation, Qwen2.5-Omni's streaming Talker outperforms most existing streaming and non-streaming alternatives in robustness and naturalness.
WavChat: A Survey of Spoken Dialogue Models
Nov 26, 2024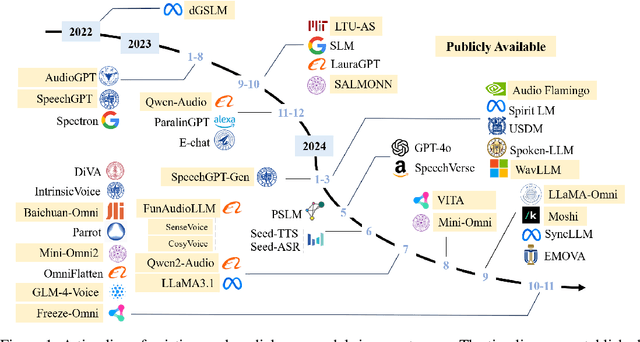

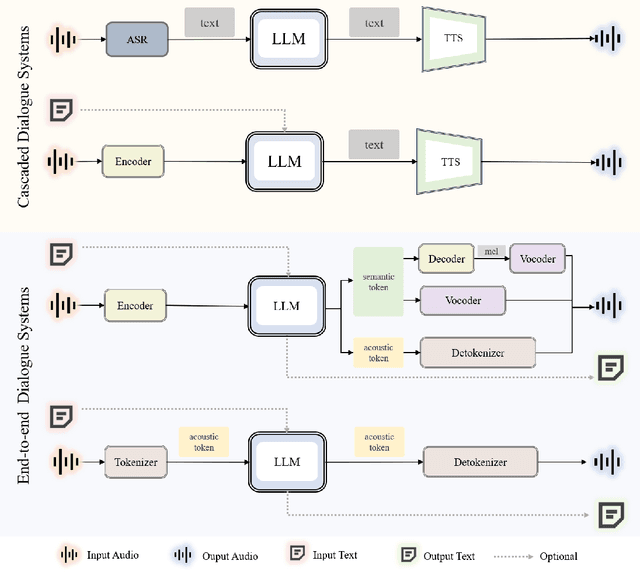
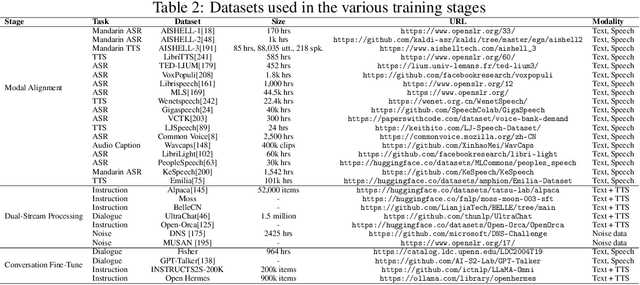
Recent advancements in spoken dialogue models, exemplified by systems like GPT-4o, have captured significant attention in the speech domain. Compared to traditional three-tier cascaded spoken dialogue models that comprise speech recognition (ASR), large language models (LLMs), and text-to-speech (TTS), modern spoken dialogue models exhibit greater intelligence. These advanced spoken dialogue models not only comprehend audio, music, and other speech-related features, but also capture stylistic and timbral characteristics in speech. Moreover, they generate high-quality, multi-turn speech responses with low latency, enabling real-time interaction through simultaneous listening and speaking capability. Despite the progress in spoken dialogue systems, there is a lack of comprehensive surveys that systematically organize and analyze these systems and the underlying technologies. To address this, we have first compiled existing spoken dialogue systems in the chronological order and categorized them into the cascaded and end-to-end paradigms. We then provide an in-depth overview of the core technologies in spoken dialogue models, covering aspects such as speech representation, training paradigm, streaming, duplex, and interaction capabilities. Each section discusses the limitations of these technologies and outlines considerations for future research. Additionally, we present a thorough review of relevant datasets, evaluation metrics, and benchmarks from the perspectives of training and evaluating spoken dialogue systems. We hope this survey will contribute to advancing both academic research and industrial applications in the field of spoken dialogue systems. The related material is available at https://github.com/jishengpeng/WavChat.
Analyzing and Mitigating Inconsistency in Discrete Audio Tokens for Neural Codec Language Models
Sep 28, 2024



Building upon advancements in Large Language Models (LLMs), the field of audio processing has seen increased interest in training audio generation tasks with discrete audio token sequences. However, directly discretizing audio by neural audio codecs often results in sequences that fundamentally differ from text sequences. Unlike text, where text token sequences are deterministic, discrete audio tokens can exhibit significant variability based on contextual factors, while still producing perceptually identical audio segments. We refer to this phenomenon as \textbf{Discrete Representation Inconsistency (DRI)}. This inconsistency can lead to a single audio segment being represented by multiple divergent sequences, which creates confusion in neural codec language models and results in omissions and repetitions during speech generation. In this paper, we quantitatively analyze the DRI phenomenon within popular audio tokenizers such as EnCodec. Our approach effectively mitigates the DRI phenomenon of the neural audio codec. Furthermore, extensive experiments on the neural codec language model over LibriTTS and large-scale MLS datases (44,000 hours) demonstrate the effectiveness and generality of our method. The demo of audio samples is available online~\footnote{\url{https://consistencyinneuralcodec.github.io}}.
Qwen2 Technical Report
Jul 16, 2024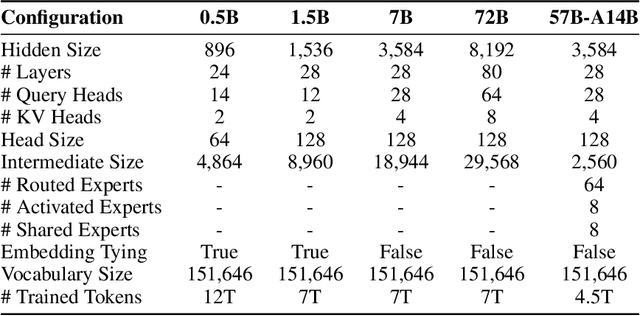
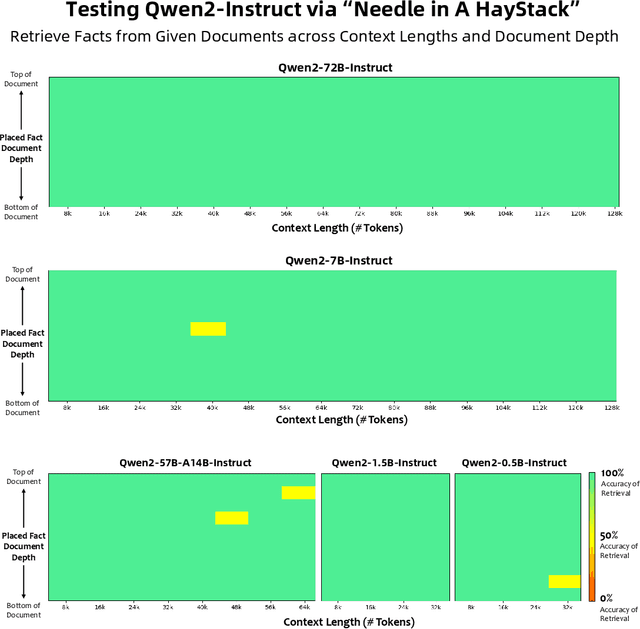
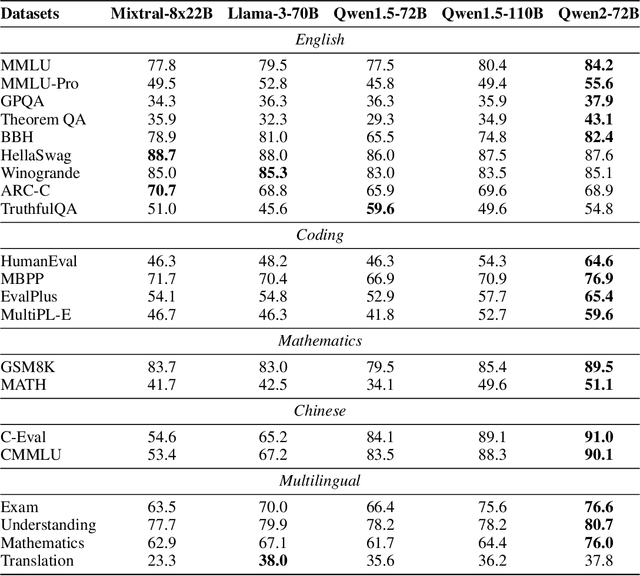
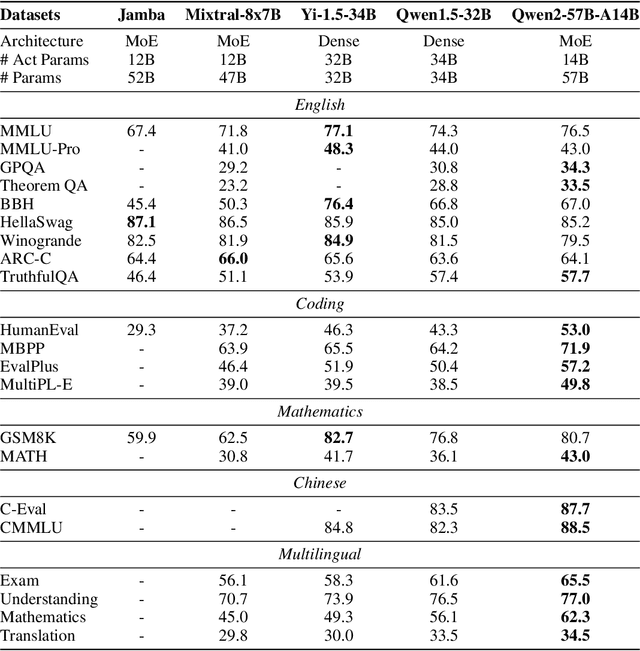
This report introduces the Qwen2 series, the latest addition to our large language models and large multimodal models. We release a comprehensive suite of foundational and instruction-tuned language models, encompassing a parameter range from 0.5 to 72 billion, featuring dense models and a Mixture-of-Experts model. Qwen2 surpasses most prior open-weight models, including its predecessor Qwen1.5, and exhibits competitive performance relative to proprietary models across diverse benchmarks on language understanding, generation, multilingual proficiency, coding, mathematics, and reasoning. The flagship model, Qwen2-72B, showcases remarkable performance: 84.2 on MMLU, 37.9 on GPQA, 64.6 on HumanEval, 89.5 on GSM8K, and 82.4 on BBH as a base language model. The instruction-tuned variant, Qwen2-72B-Instruct, attains 9.1 on MT-Bench, 48.1 on Arena-Hard, and 35.7 on LiveCodeBench. Moreover, Qwen2 demonstrates robust multilingual capabilities, proficient in approximately 30 languages, spanning English, Chinese, Spanish, French, German, Arabic, Russian, Korean, Japanese, Thai, Vietnamese, and more, underscoring its versatility and global reach. To foster community innovation and accessibility, we have made the Qwen2 model weights openly available on Hugging Face and ModelScope, and the supplementary materials including example code on GitHub. These platforms also include resources for quantization, fine-tuning, and deployment, facilitating a wide range of applications and research endeavors.
Qwen2-Audio Technical Report
Jul 15, 2024We introduce the latest progress of Qwen-Audio, a large-scale audio-language model called Qwen2-Audio, which is capable of accepting various audio signal inputs and performing audio analysis or direct textual responses with regard to speech instructions. In contrast to complex hierarchical tags, we have simplified the pre-training process by utilizing natural language prompts for different data and tasks, and have further expanded the data volume. We have boosted the instruction-following capability of Qwen2-Audio and implemented two distinct audio interaction modes for voice chat and audio analysis. In the voice chat mode, users can freely engage in voice interactions with Qwen2-Audio without text input. In the audio analysis mode, users could provide audio and text instructions for analysis during the interaction. Note that we do not use any system prompts to switch between voice chat and audio analysis modes. Qwen2-Audio is capable of intelligently comprehending the content within audio and following voice commands to respond appropriately. For instance, in an audio segment that simultaneously contains sounds, multi-speaker conversations, and a voice command, Qwen2-Audio can directly understand the command and provide an interpretation and response to the audio. Additionally, DPO has optimized the model's performance in terms of factuality and adherence to desired behavior. According to the evaluation results from AIR-Bench, Qwen2-Audio outperformed previous SOTAs, such as Gemini-1.5-pro, in tests focused on audio-centric instruction-following capabilities. Qwen2-Audio is open-sourced with the aim of fostering the advancement of the multi-modal language community.
AIR-Bench: Benchmarking Large Audio-Language Models via Generative Comprehension
Feb 12, 2024



Recently, instruction-following audio-language models have received broad attention for human-audio interaction. However, the absence of benchmarks capable of evaluating audio-centric interaction capabilities has impeded advancements in this field. Previous models primarily focus on assessing different fundamental tasks, such as Automatic Speech Recognition (ASR), and lack an assessment of the open-ended generative capabilities centered around audio. Thus, it is challenging to track the progression in the Large Audio-Language Models (LALMs) domain and to provide guidance for future improvement. In this paper, we introduce AIR-Bench (\textbf{A}udio \textbf{I}nst\textbf{R}uction \textbf{Bench}mark), the first benchmark designed to evaluate the ability of LALMs to understand various types of audio signals (including human speech, natural sounds, and music), and furthermore, to interact with humans in the textual format. AIR-Bench encompasses two dimensions: \textit{foundation} and \textit{chat} benchmarks. The former consists of 19 tasks with approximately 19k single-choice questions, intending to inspect the basic single-task ability of LALMs. The latter one contains 2k instances of open-ended question-and-answer data, directly assessing the comprehension of the model on complex audio and its capacity to follow instructions. Both benchmarks require the model to generate hypotheses directly. We design a unified framework that leverages advanced language models, such as GPT-4, to evaluate the scores of generated hypotheses given the meta-information of the audio. Experimental results demonstrate a high level of consistency between GPT-4-based evaluation and human evaluation. By revealing the limitations of existing LALMs through evaluation results, AIR-Bench can provide insights into the direction of future research.
An Adaptive Framework of Geographical Group-Specific Network on O2O Recommendation
Dec 28, 2023



Online to offline recommendation strongly correlates with the user and service's spatiotemporal information, therefore calling for a higher degree of model personalization. The traditional methodology is based on a uniform model structure trained by collected centralized data, which is unlikely to capture all user patterns over different geographical areas or time periods. To tackle this challenge, we propose a geographical group-specific modeling method called GeoGrouse, which simultaneously studies the common knowledge as well as group-specific knowledge of user preferences. An automatic grouping paradigm is employed and verified based on users' geographical grouping indicators. Offline and online experiments are conducted to verify the effectiveness of our approach, and substantial business improvement is achieved.
Qwen-Audio: Advancing Universal Audio Understanding via Unified Large-Scale Audio-Language Models
Nov 14, 2023



Recently, instruction-following audio-language models have received broad attention for audio interaction with humans. However, the absence of pre-trained audio models capable of handling diverse audio types and tasks has hindered progress in this field. Consequently, most existing works have only been able to support a limited range of interaction capabilities. In this paper, we develop the Qwen-Audio model and address this limitation by scaling up audio-language pre-training to cover over 30 tasks and various audio types, such as human speech, natural sounds, music, and songs, to facilitate universal audio understanding abilities. However, directly co-training all tasks and datasets can lead to interference issues, as the textual labels associated with different datasets exhibit considerable variations due to differences in task focus, language, granularity of annotation, and text structure. To overcome the one-to-many interference, we carefully design a multi-task training framework by conditioning on a sequence of hierarchical tags to the decoder for encouraging knowledge sharing and avoiding interference through shared and specified tags respectively. Remarkably, Qwen-Audio achieves impressive performance across diverse benchmark tasks without requiring any task-specific fine-tuning, surpassing its counterparts. Building upon the capabilities of Qwen-Audio, we further develop Qwen-Audio-Chat, which allows for input from various audios and text inputs, enabling multi-turn dialogues and supporting various audio-central scenarios.
LauraGPT: Listen, Attend, Understand, and Regenerate Audio with GPT
Oct 11, 2023



Generative Pre-trained Transformer (GPT) models have achieved remarkable performance on various natural language processing tasks. However, there has been limited research on applying similar frameworks to audio tasks. Previously proposed large language models for audio tasks either lack sufficient quantitative evaluations, or are limited to tasks for recognizing and understanding audio content, or significantly underperform existing state-of-the-art (SOTA) models. In this paper, we propose LauraGPT, a unified GPT model for audio recognition, understanding, and generation. LauraGPT is a versatile language model that can process both audio and text inputs and generate outputs in either modalities. It can perform a wide range of tasks related to content, semantics, paralinguistics, and audio-signal analysis. Some of its noteworthy tasks include automatic speech recognition, speech-to-text translation, text-to-speech synthesis, machine translation, speech enhancement, automated audio captioning, speech emotion recognition, and spoken language understanding. To achieve this goal, we use a combination of continuous and discrete features for audio. We encode input audio into continuous representations using an audio encoder and decode output audio from discrete codec codes. We then fine-tune a large decoder-only Transformer-based language model on multiple audio-to-text, text-to-audio, audio-to-audio, and text-to-text tasks using a supervised multitask learning approach. Extensive experiments show that LauraGPT achieves competitive or superior performance compared to existing SOTA models on various audio processing benchmarks.