 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniAudio: Generating Spatial Audio from 360-Degree Video
Apr 21, 2025
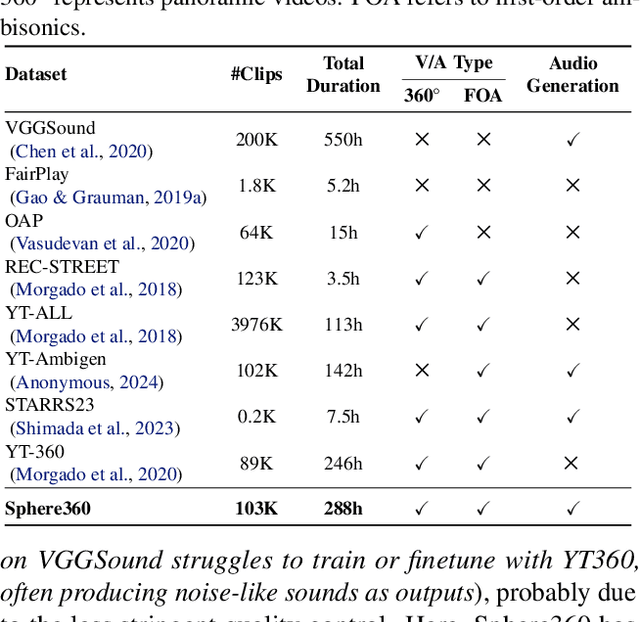
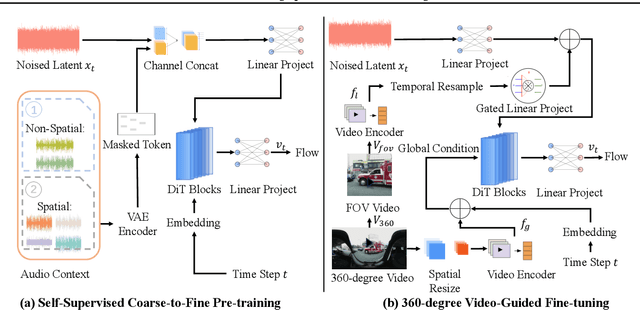
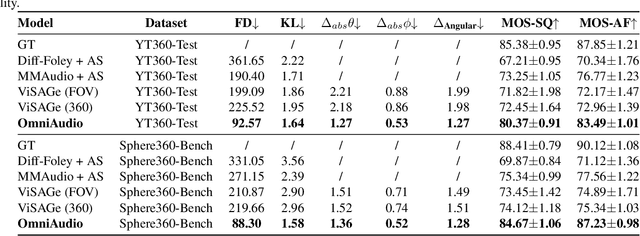
Traditional video-to-audio generation techniques primarily focus on field-of-view (FoV) video and non-spatial audio, often missing the spatial cues necessary for accurately representing sound sources in 3D environments. To address this limitation, we introduce a novel task, 360V2SA, to generate spatial audio from 360-degree videos, specifically producing First-order Ambisonics (FOA) audio - a standard format for representing 3D spatial audio that captures sound directionality and enables realistic 3D audio reproduction. We first create Sphere360, a novel dataset tailored for this task that is curated from real-world data. We also design an efficient semi-automated pipeline for collecting and cleaning paired video-audio data. To generate spatial audio from 360-degree video, we propose a novel framework OmniAudio, which leverages self-supervised pre-training using both spatial audio data (in FOA format) and large-scale non-spatial data. Furthermore, OmniAudio features a dual-branch framework that utilizes both panoramic and FoV video inputs to capture comprehensive local and global information from 360-degree videos. Experimental results demonstrate that OmniAudio achieves state-of-the-art performance across both objective and subjective metrics on Sphere360. Code and datasets will be released at https://github.com/liuhuadai/OmniAudio. The demo page is available at https://OmniAudio-360V2SA.github.io.
MinMo: A Multimodal Large Language Model for Seamless Voice Interaction
Jan 10, 2025



Recent advancements in large language models (LLMs) and multimodal speech-text models have laid the groundwork for seamless voice interactions, enabling real-time, natural, and human-like conversations. Previous models for voice interactions are categorized as native and aligned. Native models integrate speech and text processing in one framework but struggle with issues like differing sequence lengths and insufficient pre-training. Aligned models maintain text LLM capabilities but are often limited by small datasets and a narrow focus on speech tasks. In this work, we introduce MinMo, a Multimodal Large Language Model with approximately 8B parameters for seamless voice interaction. We address the main limitations of prior aligned multimodal models. We train MinMo through multiple stages of speech-to-text alignment, text-to-speech alignment, speech-to-speech alignment, and duplex interaction alignment, on 1.4 million hours of diverse speech data and a broad range of speech tasks. After the multi-stage training, MinMo achieves state-of-the-art performance across various benchmarks for voice comprehension and generation while maintaining the capabilities of text LLMs, and also facilitates full-duplex conversation, that is, simultaneous two-way communication between the user and the system. Moreover, we propose a novel and simple voice decoder that outperforms prior models in voice generation. The enhanced instruction-following capabilities of MinMo supports controlling speech generation based on user instructions, with various nuances including emotions, dialects, and speaking rates, and mimicking specific voices. For MinMo, the speech-to-text latency is approximately 100ms, full-duplex latency is approximately 600ms in theory and 800ms in practice. The MinMo project web page is https://funaudiollm.github.io/minmo, and the code and models will be released soon.
CosyVoice 2: Scalable Streaming Speech Synthesis with Large Language Models
Dec 13, 2024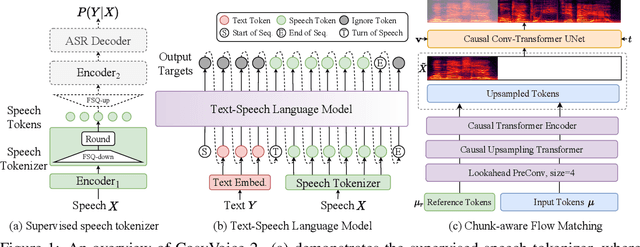

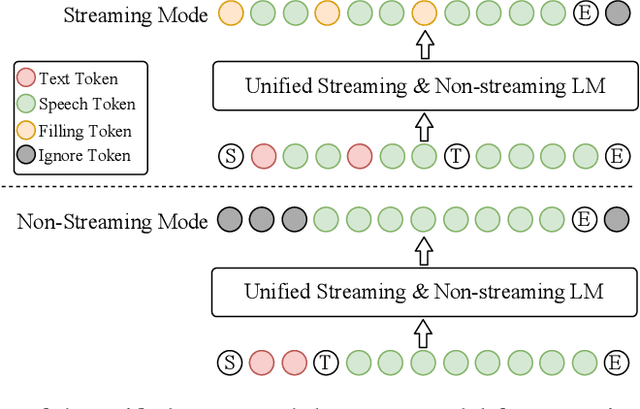

In our previous work, we introduced CosyVoice, a multilingual speech synthesis model based on supervised discrete speech tokens. By employing progressive semantic decoding with two popular generative models, language models (LMs) and Flow Matching, CosyVoice demonstrated high prosody naturalness, content consistency, and speaker similarity in speech in-context learning. Recently, significant progress has been made in multi-modal large language models (LLMs), where the response latency and real-time factor of speech synthesis play a crucial role in the interactive experience. Therefore, in this report, we present an improved streaming speech synthesis model, CosyVoice 2, which incorporates comprehensive and systematic optimizations. Specifically, we introduce finite-scalar quantization to improve the codebook utilization of speech tokens. For the text-speech LM, we streamline the model architecture to allow direct use of a pre-trained LLM as the backbone. In addition, we develop a chunk-aware causal flow matching model to support various synthesis scenarios, enabling both streaming and non-streaming synthesis within a single model. By training on a large-scale multilingual dataset, CosyVoice 2 achieves human-parity naturalness, minimal response latency, and virtually lossless synthesis quality in the streaming mode. We invite readers to listen to the demos at https://funaudiollm.github.io/cosyvoice2.
Dynamic Open-Vocabulary 3D Scene Graphs for Long-term Language-Guided Mobile Manipulation
Oct 17, 2024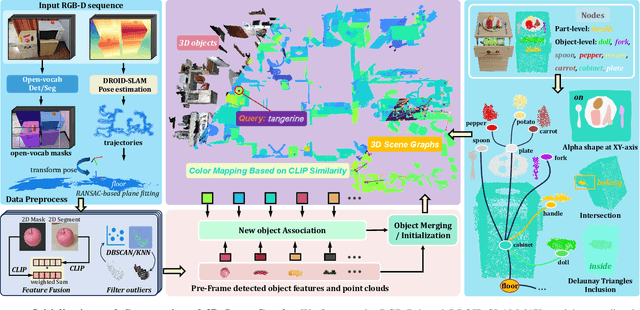
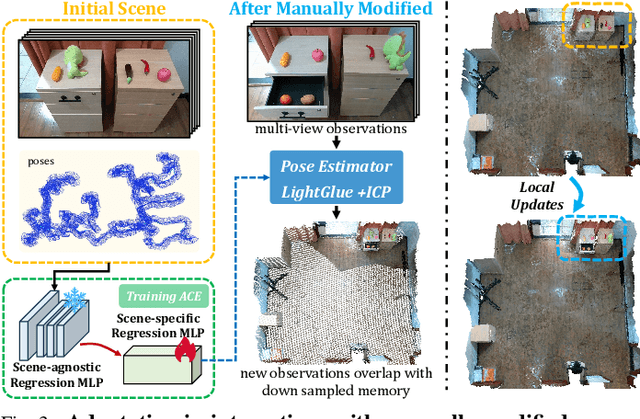
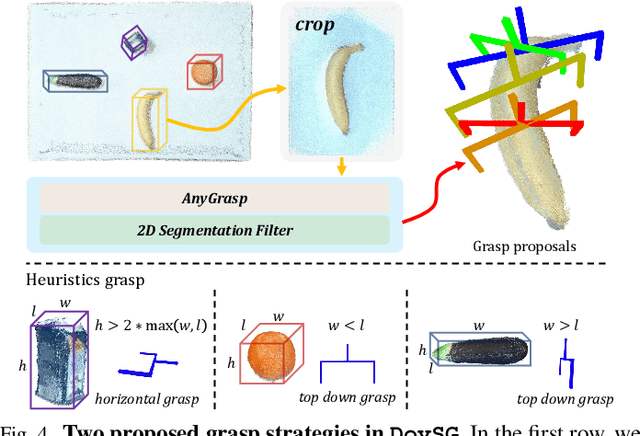

Enabling mobile robots to perform long-term tasks in dynamic real-world environments is a formidable challenge, especially when the environment changes frequently due to human-robot interactions or the robot's own actions. Traditional methods typically assume static scenes, which limits their applicability in the continuously changing real world. To overcome these limitations, we present DovSG, a novel mobile manipulation framework that leverages dynamic open-vocabulary 3D scene graphs and a language-guided task planning module for long-term task execution. DovSG takes RGB-D sequences as input and utilizes vision-language models (VLMs) for object detection to obtain high-level object semantic features. Based on the segmented objects, a structured 3D scene graph is generated for low-level spatial relationships. Furthermore, an efficient mechanism for locally updating the scene graph, allows the robot to adjust parts of the graph dynamically during interactions without the need for full scene reconstruction. This mechanism is particularly valuable in dynamic environments, enabling the robot to continually adapt to scene changes and effectively support the execution of long-term tasks. We validated our system in real-world environments with varying degrees of manual modifications, demonstrating its effectiveness and superior performance in long-term tasks. Our project page is available at: https://BJHYZJ.github.io/DoviSG.
Are Transformers in Pre-trained LM A Good ASR Encoder? An Empirical Study
Sep 26, 2024

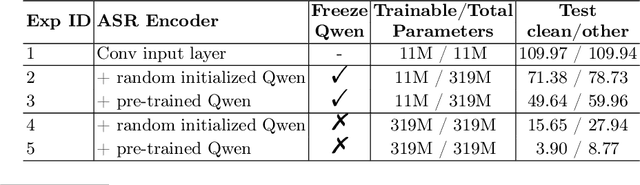

In this study, we delve into the efficacy of transformers within pre-trained language models (PLMs) when repurposed as encoders for Automatic Speech Recognition (ASR). Our underlying hypothesis posits that, despite being initially trained on text-based corpora, these transformers possess a remarkable capacity to extract effective features from the input sequence. This inherent capability, we argue, is transferrable to speech data, thereby augmenting the acoustic modeling ability of ASR. Through rigorous empirical analysis, our findings reveal a notable improvement in Character Error Rate (CER) and Word Error Rate (WER) across diverse ASR tasks when transformers from pre-trained LMs are incorporated. Particularly, they serve as an advantageous starting point for initializing ASR encoders. Furthermore, we uncover that these transformers, when integrated into a well-established ASR encoder, can significantly boost performance, especially in scenarios where profound semantic comprehension is pivotal. This underscores the potential of leveraging the semantic prowess embedded within pre-trained transformers to advance ASR systems' capabilities.
CosyVoice: A Scalable Multilingual Zero-shot Text-to-speech Synthesizer based on Supervised Semantic Tokens
Jul 09, 2024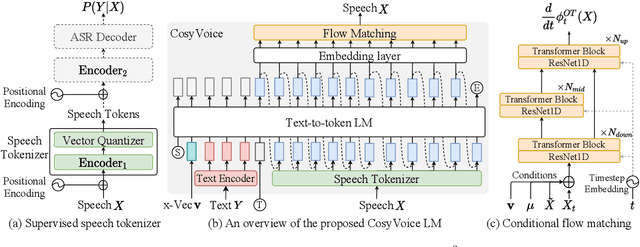

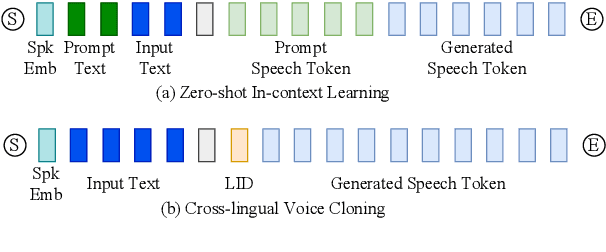
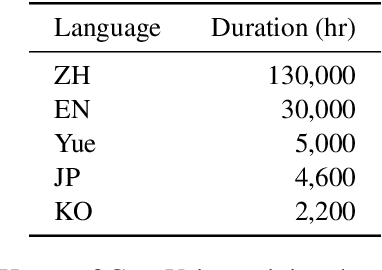
Recent years have witnessed a trend that large language model (LLM) based text-to-speech (TTS) emerges into the mainstream due to their high naturalness and zero-shot capacity. In this paradigm, speech signals are discretized into token sequences, which are modeled by an LLM with text as prompts and reconstructed by a token-based vocoder to waveforms. Obviously, speech tokens play a critical role in LLM-based TTS models. Current speech tokens are learned in an unsupervised manner, which lacks explicit semantic information and alignment to the text. In this paper, we propose to represent speech with supervised semantic tokens, which are derived from a multilingual speech recognition model by inserting vector quantization into the encoder. Based on the tokens, we further propose a scalable zero-shot TTS synthesizer, CosyVoice, which consists of an LLM for text-to-token generation and a conditional flow matching model for token-to-speech synthesis. Experimental results show that supervised semantic tokens significantly outperform existing unsupervised tokens in terms of content consistency and speaker similarity for zero-shot voice cloning. Moreover, we find that utilizing large-scale data further improves the synthesis performance, indicating the scalable capacity of CosyVoice. To the best of our knowledge, this is the first attempt to involve supervised speech tokens into TTS models.
TOD3Cap: Towards 3D Dense Captioning in Outdoor Scenes
Mar 28, 2024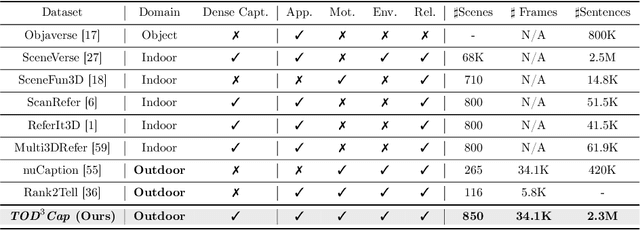
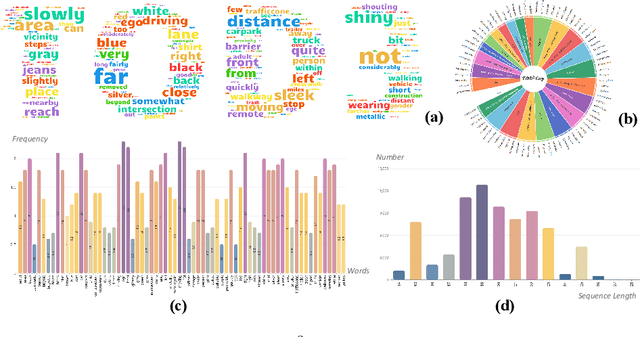

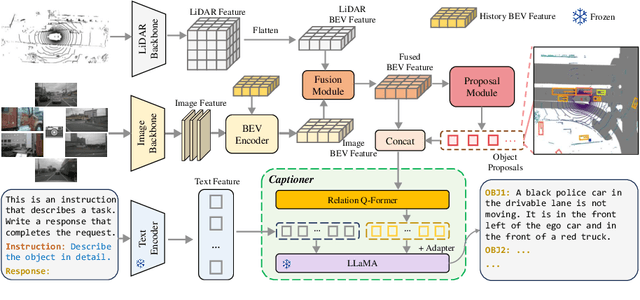
3D dense captioning stands as a cornerstone in achieving a comprehensive understanding of 3D scenes through natural language. It has recently witnessed remarkable achievements, particularly in indoor settings. However, the exploration of 3D dense captioning in outdoor scenes is hindered by two major challenges: 1) the \textbf{domain gap} between indoor and outdoor scenes, such as dynamics and sparse visual inputs, makes it difficult to directly adapt existing indoor methods; 2) the \textbf{lack of data} with comprehensive box-caption pair annotations specifically tailored for outdoor scenes. To this end, we introduce the new task of outdoor 3D dense captioning. As input, we assume a LiDAR point cloud and a set of RGB images captured by the panoramic camera rig. The expected output is a set of object boxes with captions. To tackle this task, we propose the TOD3Cap network, which leverages the BEV representation to generate object box proposals and integrates Relation Q-Former with LLaMA-Adapter to generate rich captions for these objects. We also introduce the TOD3Cap dataset, the largest one to our knowledge for 3D dense captioning in outdoor scenes, which contains 2.3M descriptions of 64.3K outdoor objects from 850 scenes. Notably, our TOD3Cap network can effectively localize and caption 3D objects in outdoor scenes, which outperforms baseline methods by a significant margin (+9.6 CiDEr@0.5IoU). Code, data, and models are publicly available at https://github.com/jxbbb/TOD3Cap.
Large Language Models Powered Context-aware Motion Prediction
Mar 17, 2024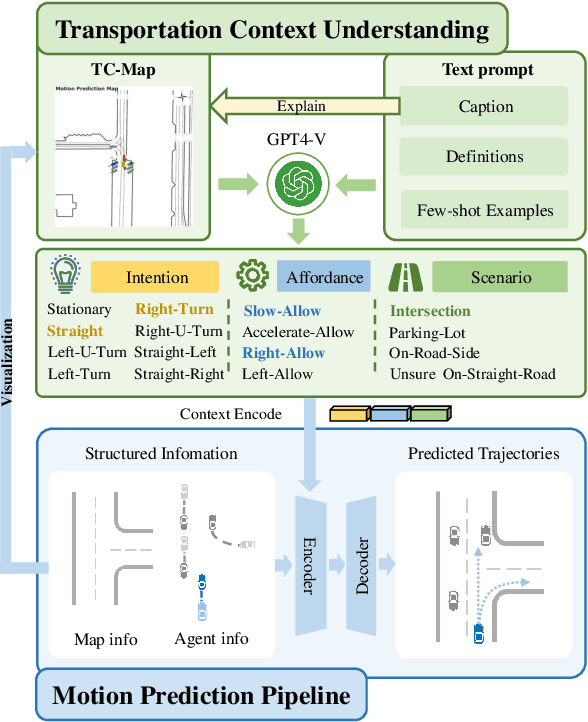
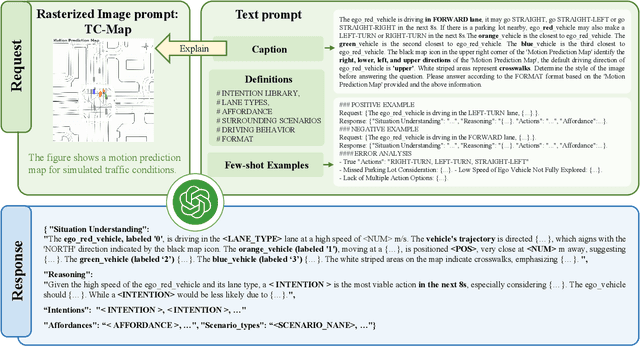
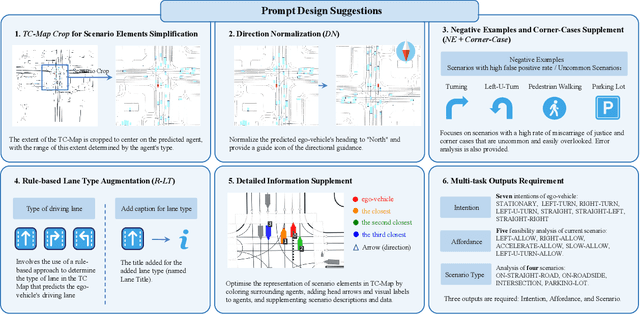
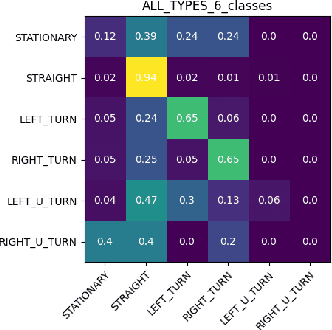
Motion prediction is among the most fundamental tasks in autonomous driving. Traditional methods of motion forecasting primarily encode vector information of maps and historical trajectory data of traffic participants, lacking a comprehensive understanding of overall traffic semantics, which in turn affects the performance of prediction tasks. In this paper, we utilized Large Language Models (LLMs) to enhance the global traffic context understanding for motion prediction tasks. We first conducted systematic prompt engineering, visualizing complex traffic environments and historical trajectory information of traffic participants into image prompts -- Transportation Context Map (TC-Map), accompanied by corresponding text prompts. Through this approach, we obtained rich traffic context information from the LLM. By integrating this information into the motion prediction model, we demonstrate that such context can enhance the accuracy of motion predictions. Furthermore, considering the cost associated with LLMs, we propose a cost-effective deployment strategy: enhancing the accuracy of motion prediction tasks at scale with 0.7\% LLM-augmented datasets. Our research offers valuable insights into enhancing the understanding of traffic scenes of LLMs and the motion prediction performance of autonomous driving.
Advancing VAD Systems Based on Multi-Task Learning with Improved Model Structures
Dec 19, 2023In a speech recognition system, voice activity detection (VAD) is a crucial frontend module. Addressing the issues of poor noise robustness in traditional binary VAD systems based on DFSMN, the paper further proposes semantic VAD based on multi-task learning with improved models for real-time and offline systems, to meet specific application requirements. Evaluations on internal datasets show that, compared to the real-time VAD system based on DFSMN, the real-time semantic VAD system based on RWKV achieves relative decreases in CER of 7.0\%, DCF of 26.1\% and relative improvement in NRR of 19.2\%. Similarly, when compared to the offline VAD system based on DFSMN, the offline VAD system based on SAN-M demonstrates relative decreases in CER of 4.4\%, DCF of 18.6\% and relative improvement in NRR of 3.5\%.
Qwen-Audio: Advancing Universal Audio Understanding via Unified Large-Scale Audio-Language Models
Nov 14, 2023



Recently, instruction-following audio-language models have received broad attention for audio interaction with humans. However, the absence of pre-trained audio models capable of handling diverse audio types and tasks has hindered progress in this field. Consequently, most existing works have only been able to support a limited range of interaction capabilities. In this paper, we develop the Qwen-Audio model and address this limitation by scaling up audio-language pre-training to cover over 30 tasks and various audio types, such as human speech, natural sounds, music, and songs, to facilitate universal audio understanding abilities. However, directly co-training all tasks and datasets can lead to interference issues, as the textual labels associated with different datasets exhibit considerable variations due to differences in task focus, language, granularity of annotation, and text structure. To overcome the one-to-many interference, we carefully design a multi-task training framework by conditioning on a sequence of hierarchical tags to the decoder for encouraging knowledge sharing and avoiding interference through shared and specified tags respectively. Remarkably, Qwen-Audio achieves impressive performance across diverse benchmark tasks without requiring any task-specific fine-tuning, surpassing its counterparts. Building upon the capabilities of Qwen-Audio, we further develop Qwen-Audio-Chat, which allows for input from various audios and text inputs, enabling multi-turn dialogues and supporting various audio-central scenarios.