 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCosyVoice 3: Towards In-the-wild Speech Generation via Scaling-up and Post-training
May 23, 2025In our prior works, we introduced a scalable streaming speech synthesis model, CosyVoice 2, which integrates a large language model (LLM) and a chunk-aware flow matching (FM) model, and achieves low-latency bi-streaming speech synthesis and human-parity quality. Despite these advancements, CosyVoice 2 exhibits limitations in language coverage, domain diversity, data volume, text formats, and post-training techniques. In this paper, we present CosyVoice 3, an improved model designed for zero-shot multilingual speech synthesis in the wild, surpassing its predecessor in content consistency, speaker similarity, and prosody naturalness. Key features of CosyVoice 3 include: 1) A novel speech tokenizer to improve prosody naturalness, developed via supervised multi-task training, including automatic speech recognition, speech emotion recognition, language identification, audio event detection, and speaker analysis. 2) A new differentiable reward model for post-training applicable not only to CosyVoice 3 but also to other LLM-based speech synthesis models. 3) Dataset Size Scaling: Training data is expanded from ten thousand hours to one million hours, encompassing 9 languages and 18 Chinese dialects across various domains and text formats. 4) Model Size Scaling: Model parameters are increased from 0.5 billion to 1.5 billion, resulting in enhanced performance on our multilingual benchmark due to the larger model capacity. These advancements contribute significantly to the progress of speech synthesis in the wild. We encourage readers to listen to the demo at https://funaudiollm.github.io/cosyvoice3.
CosyVoice 2: Scalable Streaming Speech Synthesis with Large Language Models
Dec 13, 2024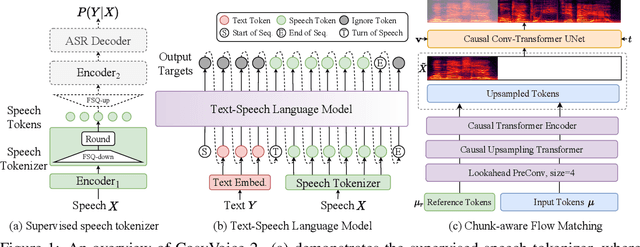

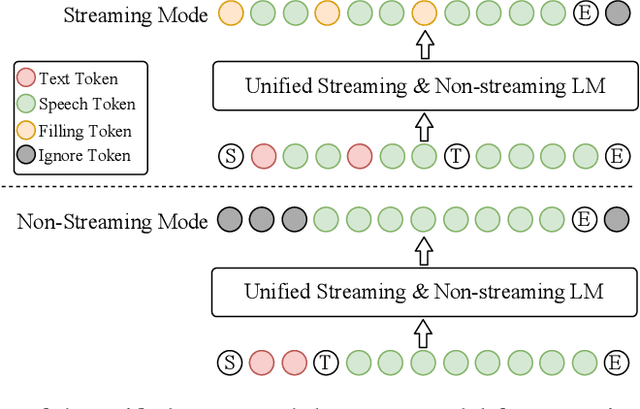

In our previous work, we introduced CosyVoice, a multilingual speech synthesis model based on supervised discrete speech tokens. By employing progressive semantic decoding with two popular generative models, language models (LMs) and Flow Matching, CosyVoice demonstrated high prosody naturalness, content consistency, and speaker similarity in speech in-context learning. Recently, significant progress has been made in multi-modal large language models (LLMs), where the response latency and real-time factor of speech synthesis play a crucial role in the interactive experience. Therefore, in this report, we present an improved streaming speech synthesis model, CosyVoice 2, which incorporates comprehensive and systematic optimizations. Specifically, we introduce finite-scalar quantization to improve the codebook utilization of speech tokens. For the text-speech LM, we streamline the model architecture to allow direct use of a pre-trained LLM as the backbone. In addition, we develop a chunk-aware causal flow matching model to support various synthesis scenarios, enabling both streaming and non-streaming synthesis within a single model. By training on a large-scale multilingual dataset, CosyVoice 2 achieves human-parity naturalness, minimal response latency, and virtually lossless synthesis quality in the streaming mode. We invite readers to listen to the demos at https://funaudiollm.github.io/cosyvoice2.
CosyVoice: A Scalable Multilingual Zero-shot Text-to-speech Synthesizer based on Supervised Semantic Tokens
Jul 09, 2024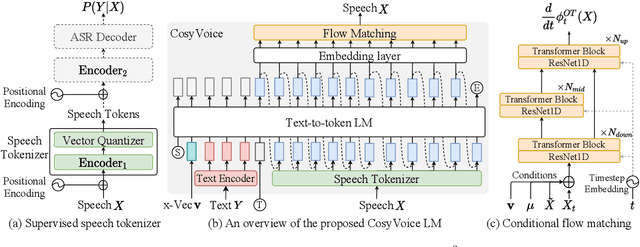

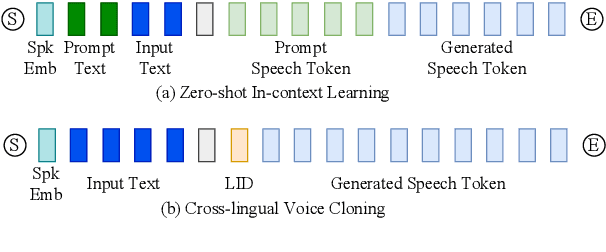
Recent years have witnessed a trend that large language model (LLM) based text-to-speech (TTS) emerges into the mainstream due to their high naturalness and zero-shot capacity. In this paradigm, speech signals are discretized into token sequences, which are modeled by an LLM with text as prompts and reconstructed by a token-based vocoder to waveforms. Obviously, speech tokens play a critical role in LLM-based TTS models. Current speech tokens are learned in an unsupervised manner, which lacks explicit semantic information and alignment to the text. In this paper, we propose to represent speech with supervised semantic tokens, which are derived from a multilingual speech recognition model by inserting vector quantization into the encoder. Based on the tokens, we further propose a scalable zero-shot TTS synthesizer, CosyVoice, which consists of an LLM for text-to-token generation and a conditional flow matching model for token-to-speech synthesis. Experimental results show that supervised semantic tokens significantly outperform existing unsupervised tokens in terms of content consistency and speaker similarity for zero-shot voice cloning. Moreover, we find that utilizing large-scale data further improves the synthesis performance, indicating the scalable capacity of CosyVoice. To the best of our knowledge, this is the first attempt to involve supervised speech tokens into TTS models.
The Effect of Predictive Formal Modelling at Runtime on Performance in Human-Swarm Interaction
Jan 22, 2024Formal Modelling is often used as part of the design and testing process of software development to ensure that components operate within suitable bounds even in unexpected circumstances. In this paper, we use predictive formal modelling (PFM) at runtime in a human-swarm mission and show that this integration can be used to improve the performance of human-swarm teams. We recruited 60 participants to operate a simulated aerial swarm to deliver parcels to target locations. In the PFM condition, operators were informed of the estimated completion times given the number of drones deployed, whereas in the No-PFM condition, operators did not have this information. The operators could control the mission by adding or removing drones from the mission and thereby, increasing or decreasing the overall mission cost. The evaluation of human-swarm performance relied on four key metrics: the time taken to complete tasks, the number of agents involved, the total number of tasks accomplished, and the overall cost associated with the human-swarm task. Our results show that PFM modelling at runtime improves mission performance without significantly affecting the operator's workload or the system's usability.
Improving Label Assignments Learning by Dynamic Sample Dropout Combined with Layer-wise Optimization in Speech Separation
Nov 20, 2023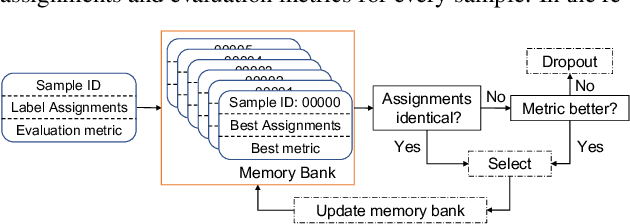
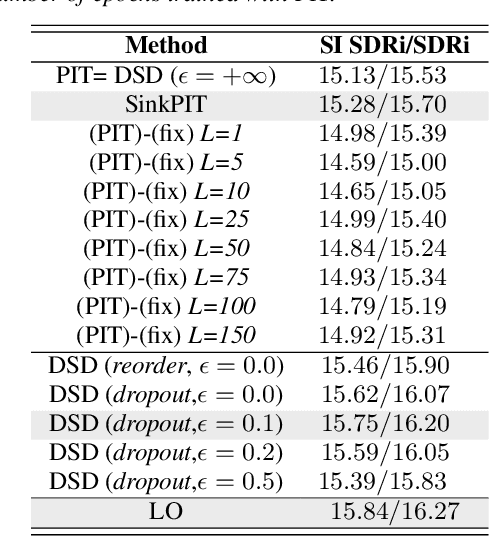
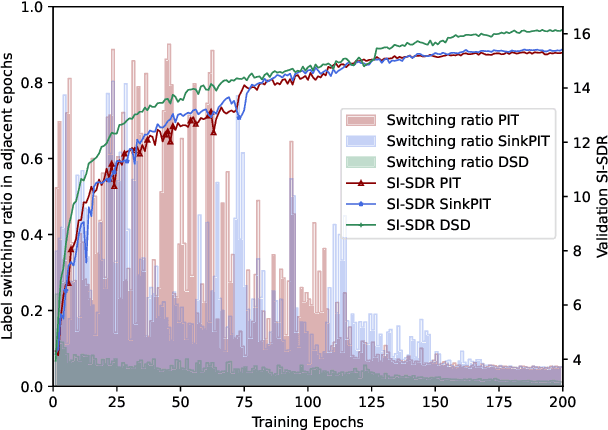
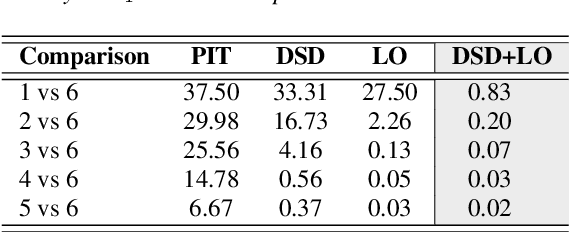
In supervised speech separation, permutation invariant training (PIT) is widely used to handle label ambiguity by selecting the best permutation to update the model. Despite its success, previous studies showed that PIT is plagued by excessive label assignment switching in adjacent epochs, impeding the model to learn better label assignments. To address this issue, we propose a novel training strategy, dynamic sample dropout (DSD), which considers previous best label assignments and evaluation metrics to exclude the samples that may negatively impact the learned label assignments during training. Additionally, we include layer-wise optimization (LO) to improve the performance by solving layer-decoupling. Our experiments showed that combining DSD and LO outperforms the baseline and solves excessive label assignment switching and layer-decoupling issues. The proposed DSD and LO approach is easy to implement, requires no extra training sets or steps, and shows generality to various speech separation tasks.
On-Device Constrained Self-Supervised Speech Representation Learning for Keyword Spotting via Knowledge Distillation
Jul 06, 2023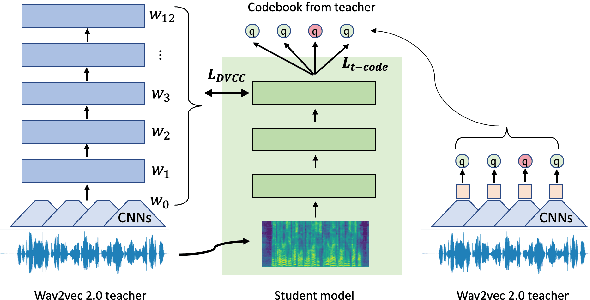

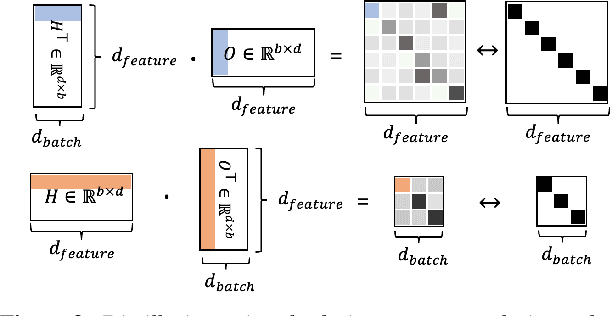
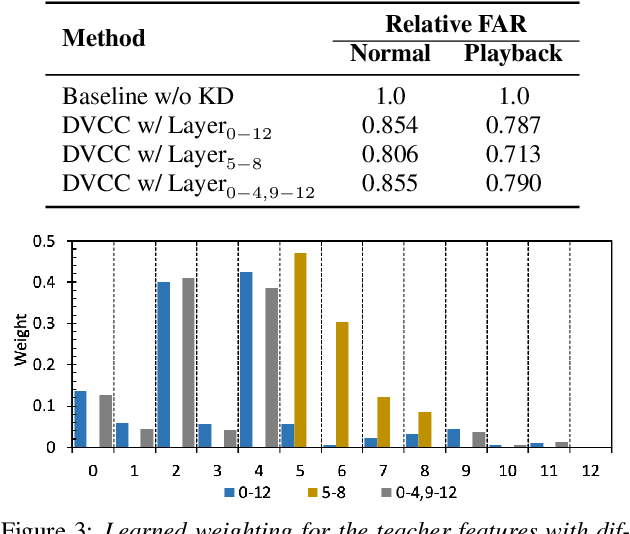
Large self-supervised models are effective feature extractors, but their application is challenging under on-device budget constraints and biased dataset collection, especially in keyword spotting. To address this, we proposed a knowledge distillation-based self-supervised speech representation learning (S3RL) architecture for on-device keyword spotting. Our approach used a teacher-student framework to transfer knowledge from a larger, more complex model to a smaller, light-weight model using dual-view cross-correlation distillation and the teacher's codebook as learning objectives. We evaluated our model's performance on an Alexa keyword spotting detection task using a 16.6k-hour in-house dataset. Our technique showed exceptional performance in normal and noisy conditions, demonstrating the efficacy of knowledge distillation methods in constructing self-supervised models for keyword spotting tasks while working within on-device resource constraints.
Self-supervised speech representation learning for keyword-spotting with light-weight transformers
Mar 07, 2023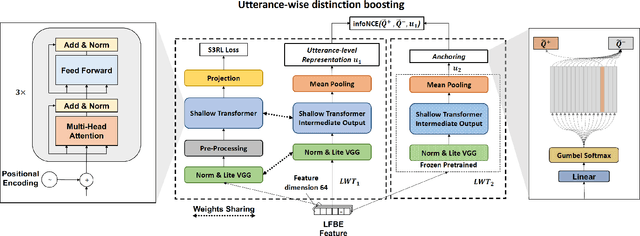
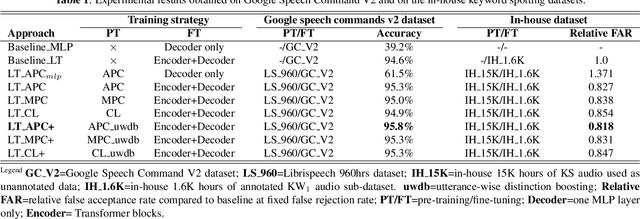
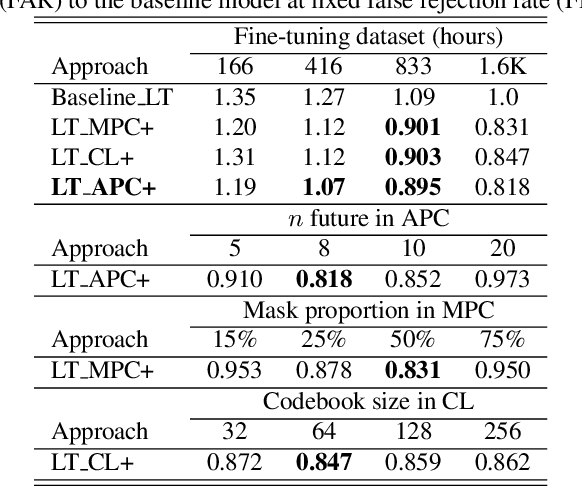
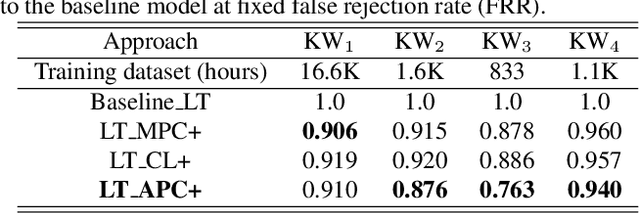
Self-supervised speech representation learning (S3RL) is revolutionizing the way we leverage the ever-growing availability of data. While S3RL related studies typically use large models, we employ light-weight networks to comply with tight memory of compute-constrained devices. We demonstrate the effectiveness of S3RL on a keyword-spotting (KS) problem by using transformers with 330k parameters and propose a mechanism to enhance utterance-wise distinction, which proves crucial for improving performance on classification tasks. On the Google speech commands v2 dataset, the proposed method applied to the Auto-Regressive Predictive Coding S3RL led to a 1.2% accuracy improvement compared to training from scratch. On an in-house KS dataset with four different keywords, it provided 6% to 23.7% relative false accept improvement at fixed false reject rate. We argue this demonstrates the applicability of S3RL approaches to light-weight models for KS and confirms S3RL is a powerful alternative to traditional supervised learning for resource-constrained applications.
Time-Domain Mapping Based Single-Channel Speech Separation With Hierarchical Constraint Training
Oct 20, 2021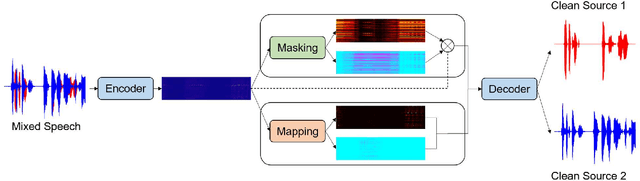
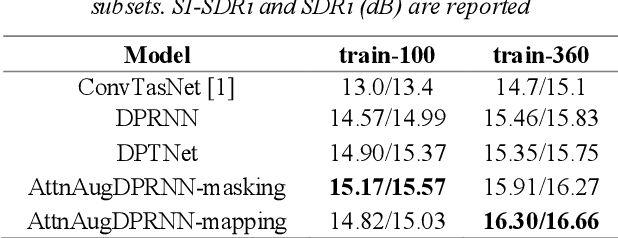

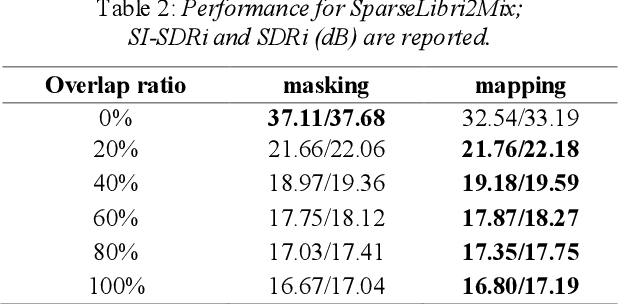
Single-channel speech separation is required for multi-speaker speech recognition. Recent deep learning-based approaches focused on time-domain audio separation net (TasNet) because it has superior performance and lower latency compared to the conventional time-frequency-based (T-F-based) approaches. Most of these works rely on the masking-based method that estimates a linear mapping function (mask) for each speaker. However, the other commonly used method, the mapping-based method that is less sensitive to SNR variations, is inadequately studied in the time domain. We explore the potential of the mapping-based method by introducing attention augmented DPRNN (AttnAugDPRNN) which directly approximates the clean sources from the mixture for speech separation. Permutation Invariant Training (PIT) has been a paradigm to solve the label ambiguity problem for speech separation but usually leads to suboptimal performance. To solve this problem, we propose an efficient training strategy called Hierarchical Constraint Training (HCT) to regularize the training, which could effectively improve the model performance. When using PIT, our results showed that mapping-based AttnAugDPRNN outperformed masking-based AttnAugDPRNN when the training corpus is large. Mapping-based AttnAugDPRNN with HCT significantly improved the SI-SDR by 10.1% compared to the masking-based AttnAugDPRNN without HCT.
Recurrent Distillation based Crowd Counting
Jun 14, 2020

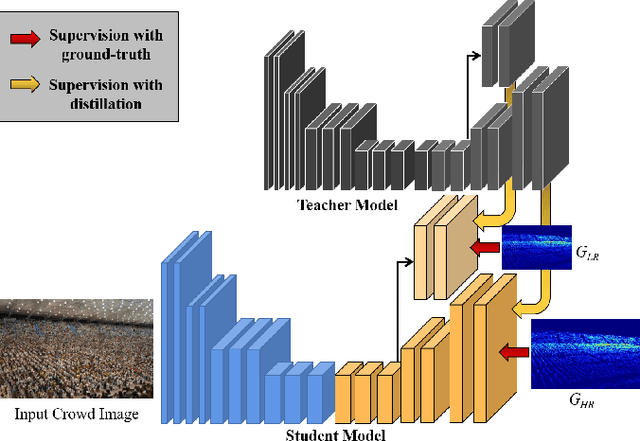

In recent years, with the progress of deep learning technologies, crowd counting has been rapidly developed. In this work, we propose a simple yet effective crowd counting framework that is able to achieve the state-of-the-art performance on various crowded scenes. In particular, we first introduce a perspective-aware density map generation method that is able to produce ground-truth density maps from point annotations to train crowd counting model to accomplish superior performance than prior density map generation techniques. Besides, leveraging our density map generation method, we propose an iterative distillation algorithm to progressively enhance our model with identical network structures, without significantly sacrificing the dimension of the output density maps. In experiments, we demonstrate that, with our simple convolutional neural network architecture strengthened by our proposed training algorithm, our model is able to outperform or be comparable with the state-of-the-art methods. Furthermore, we also evaluate our density map generation approach and distillation algorithm in ablation studies.
A Monaural Speech Enhancement Method for Robust Small-Footprint Keyword Spotting
Jun 20, 2019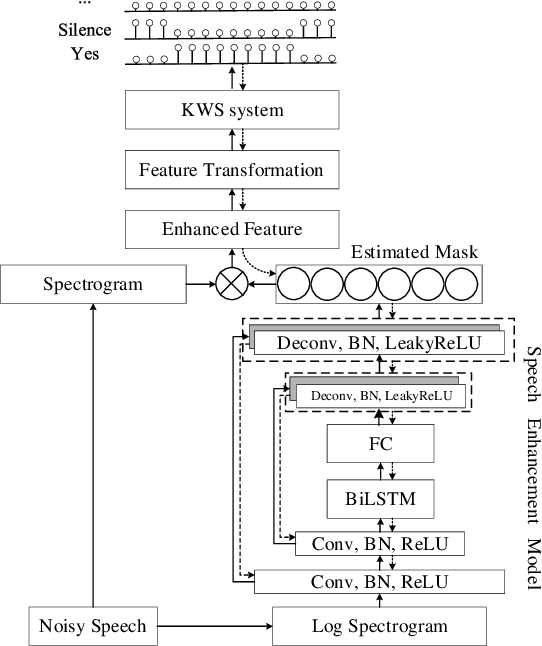

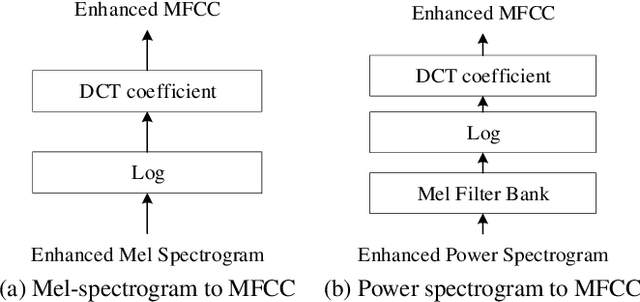
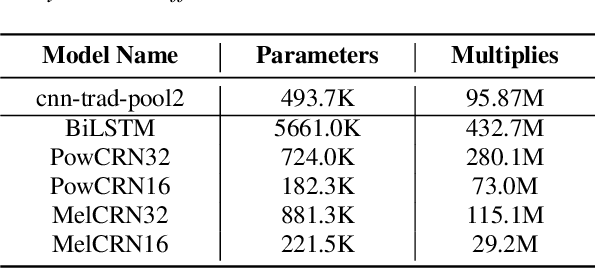
Robustness against noise is critical for keyword spotting (KWS) in real-world environments. To improve the robustness, a speech enhancement front-end is involved. Instead of treating the speech enhancement as a separated preprocessing before the KWS system, in this study, a pre-trained speech enhancement front-end and a convolutional neural networks (CNNs) based KWS system are concatenated, where a feature transformation block is used to transform the output from the enhancement front-end into the KWS system's input. The whole model is trained jointly, thus the linguistic and other useful information from the KWS system can be back-propagated to the enhancement front-end to improve its performance. To fit the small-footprint device, a novel convolution recurrent network is proposed, which needs fewer parameters and computation and does not degrade performance. Furthermore, by changing the input features from the power spectrogram to Mel-spectrogram, less computation and better performance are obtained. our experimental results demonstrate that the proposed method significantly improves the KWS system with respect to noise robustness.