 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMELA-TTS: Joint transformer-diffusion model with representation alignment for speech synthesis
Sep 18, 2025This work introduces MELA-TTS, a novel joint transformer-diffusion framework for end-to-end text-to-speech synthesis. By autoregressively generating continuous mel-spectrogram frames from linguistic and speaker conditions, our architecture eliminates the need for speech tokenization and multi-stage processing pipelines. To address the inherent difficulties of modeling continuous features, we propose a representation alignment module that aligns output representations of the transformer decoder with semantic embeddings from a pretrained ASR encoder during training. This mechanism not only speeds up training convergence, but also enhances cross-modal coherence between the textual and acoustic domains. Comprehensive experiments demonstrate that MELA-TTS achieves state-of-the-art performance across multiple evaluation metrics while maintaining robust zero-shot voice cloning capabilities, in both offline and streaming synthesis modes. Our results establish a new benchmark for continuous feature generation approaches in TTS, offering a compelling alternative to discrete-token-based paradigms.
CosyVoice 3: Towards In-the-wild Speech Generation via Scaling-up and Post-training
May 23, 2025In our prior works, we introduced a scalable streaming speech synthesis model, CosyVoice 2, which integrates a large language model (LLM) and a chunk-aware flow matching (FM) model, and achieves low-latency bi-streaming speech synthesis and human-parity quality. Despite these advancements, CosyVoice 2 exhibits limitations in language coverage, domain diversity, data volume, text formats, and post-training techniques. In this paper, we present CosyVoice 3, an improved model designed for zero-shot multilingual speech synthesis in the wild, surpassing its predecessor in content consistency, speaker similarity, and prosody naturalness. Key features of CosyVoice 3 include: 1) A novel speech tokenizer to improve prosody naturalness, developed via supervised multi-task training, including automatic speech recognition, speech emotion recognition, language identification, audio event detection, and speaker analysis. 2) A new differentiable reward model for post-training applicable not only to CosyVoice 3 but also to other LLM-based speech synthesis models. 3) Dataset Size Scaling: Training data is expanded from ten thousand hours to one million hours, encompassing 9 languages and 18 Chinese dialects across various domains and text formats. 4) Model Size Scaling: Model parameters are increased from 0.5 billion to 1.5 billion, resulting in enhanced performance on our multilingual benchmark due to the larger model capacity. These advancements contribute significantly to the progress of speech synthesis in the wild. We encourage readers to listen to the demo at https://funaudiollm.github.io/cosyvoice3.
EmoVoice: LLM-based Emotional Text-To-Speech Model with Freestyle Text Prompting
Apr 22, 2025Human speech goes beyond the mere transfer of information; it is a profound exchange of emotions and a connection between individuals. While Text-to-Speech (TTS) models have made huge progress, they still face challenges in controlling the emotional expression in the generated speech. In this work, we propose EmoVoice, a novel emotion-controllable TTS model that exploits large language models (LLMs) to enable fine-grained freestyle natural language emotion control, and a phoneme boost variant design that makes the model output phoneme tokens and audio tokens in parallel to enhance content consistency, inspired by chain-of-thought (CoT) and chain-of-modality (CoM) techniques. Besides, we introduce EmoVoice-DB, a high-quality 40-hour English emotion dataset featuring expressive speech and fine-grained emotion labels with natural language descriptions. EmoVoice achieves state-of-the-art performance on the English EmoVoice-DB test set using only synthetic training data, and on the Chinese Secap test set using our in-house data. We further investigate the reliability of existing emotion evaluation metrics and their alignment with human perceptual preferences, and explore using SOTA multimodal LLMs GPT-4o-audio and Gemini to assess emotional speech. Demo samples are available at https://yanghaha0908.github.io/EmoVoice/. Dataset, code, and checkpoints will be released.
Unispeaker: A Unified Approach for Multimodality-driven Speaker Generation
Jan 11, 2025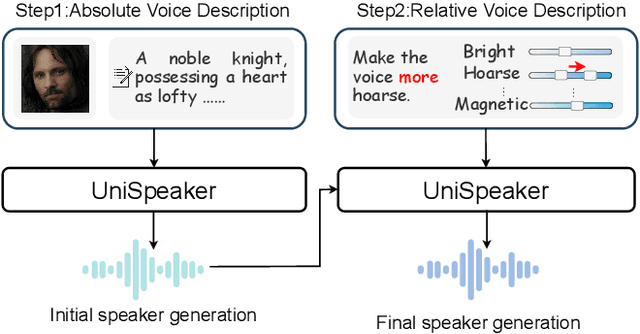
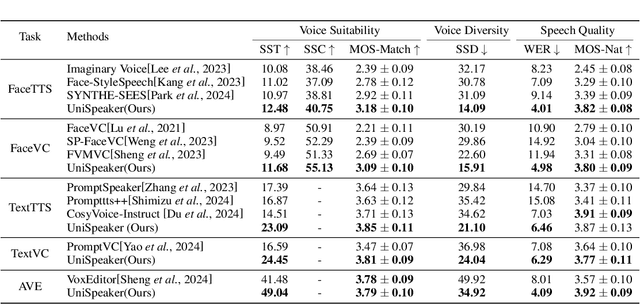
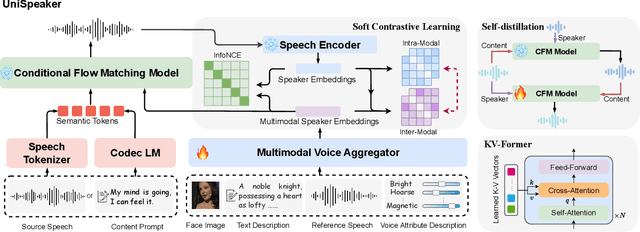
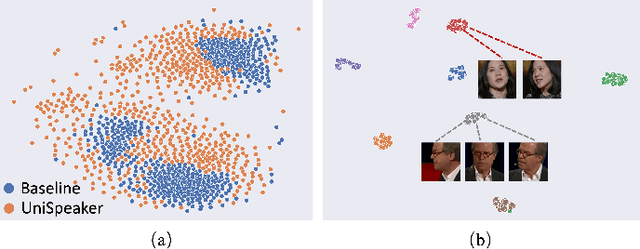
Recent advancements in personalized speech generation have brought synthetic speech increasingly close to the realism of target speakers' recordings, yet multimodal speaker generation remains on the rise. This paper introduces UniSpeaker, a unified approach for multimodality-driven speaker generation. Specifically, we propose a unified voice aggregator based on KV-Former, applying soft contrastive loss to map diverse voice description modalities into a shared voice space, ensuring that the generated voice aligns more closely with the input descriptions. To evaluate multimodality-driven voice control, we build the first multimodality-based voice control (MVC) benchmark, focusing on voice suitability, voice diversity, and speech quality. UniSpeaker is evaluated across five tasks using the MVC benchmark, and the experimental results demonstrate that UniSpeaker outperforms previous modality-specific models. Speech samples are available at \url{https://UniSpeaker.github.io}.
MinMo: A Multimodal Large Language Model for Seamless Voice Interaction
Jan 10, 2025



Recent advancements in large language models (LLMs) and multimodal speech-text models have laid the groundwork for seamless voice interactions, enabling real-time, natural, and human-like conversations. Previous models for voice interactions are categorized as native and aligned. Native models integrate speech and text processing in one framework but struggle with issues like differing sequence lengths and insufficient pre-training. Aligned models maintain text LLM capabilities but are often limited by small datasets and a narrow focus on speech tasks. In this work, we introduce MinMo, a Multimodal Large Language Model with approximately 8B parameters for seamless voice interaction. We address the main limitations of prior aligned multimodal models. We train MinMo through multiple stages of speech-to-text alignment, text-to-speech alignment, speech-to-speech alignment, and duplex interaction alignment, on 1.4 million hours of diverse speech data and a broad range of speech tasks. After the multi-stage training, MinMo achieves state-of-the-art performance across various benchmarks for voice comprehension and generation while maintaining the capabilities of text LLMs, and also facilitates full-duplex conversation, that is, simultaneous two-way communication between the user and the system. Moreover, we propose a novel and simple voice decoder that outperforms prior models in voice generation. The enhanced instruction-following capabilities of MinMo supports controlling speech generation based on user instructions, with various nuances including emotions, dialects, and speaking rates, and mimicking specific voices. For MinMo, the speech-to-text latency is approximately 100ms, full-duplex latency is approximately 600ms in theory and 800ms in practice. The MinMo project web page is https://funaudiollm.github.io/minmo, and the code and models will be released soon.
CosyVoice 2: Scalable Streaming Speech Synthesis with Large Language Models
Dec 13, 2024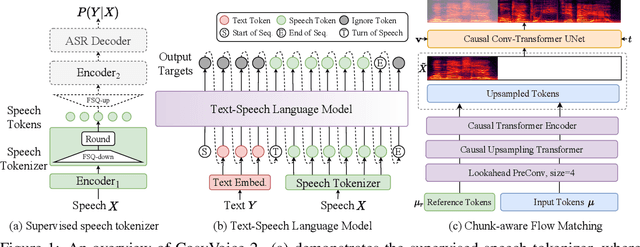

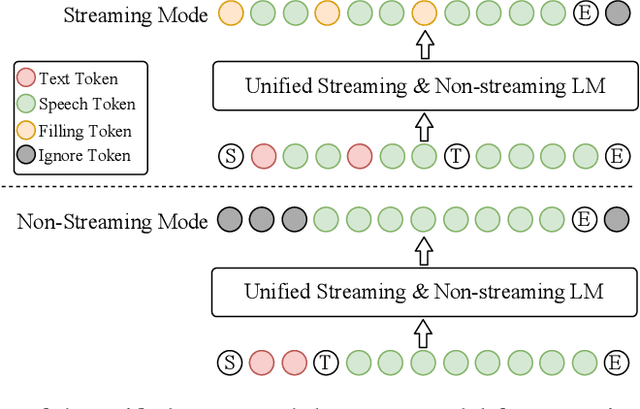

In our previous work, we introduced CosyVoice, a multilingual speech synthesis model based on supervised discrete speech tokens. By employing progressive semantic decoding with two popular generative models, language models (LMs) and Flow Matching, CosyVoice demonstrated high prosody naturalness, content consistency, and speaker similarity in speech in-context learning. Recently, significant progress has been made in multi-modal large language models (LLMs), where the response latency and real-time factor of speech synthesis play a crucial role in the interactive experience. Therefore, in this report, we present an improved streaming speech synthesis model, CosyVoice 2, which incorporates comprehensive and systematic optimizations. Specifically, we introduce finite-scalar quantization to improve the codebook utilization of speech tokens. For the text-speech LM, we streamline the model architecture to allow direct use of a pre-trained LLM as the backbone. In addition, we develop a chunk-aware causal flow matching model to support various synthesis scenarios, enabling both streaming and non-streaming synthesis within a single model. By training on a large-scale multilingual dataset, CosyVoice 2 achieves human-parity naturalness, minimal response latency, and virtually lossless synthesis quality in the streaming mode. We invite readers to listen to the demos at https://funaudiollm.github.io/cosyvoice2.
Enhancing Low-Resource ASR through Versatile TTS: Bridging the Data Gap
Oct 22, 2024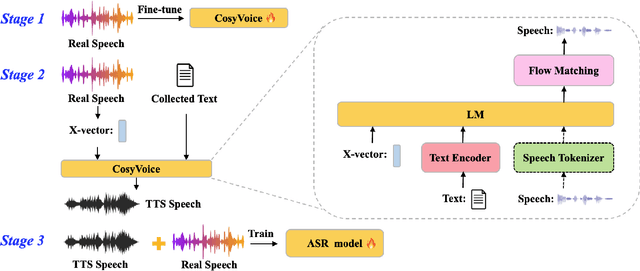
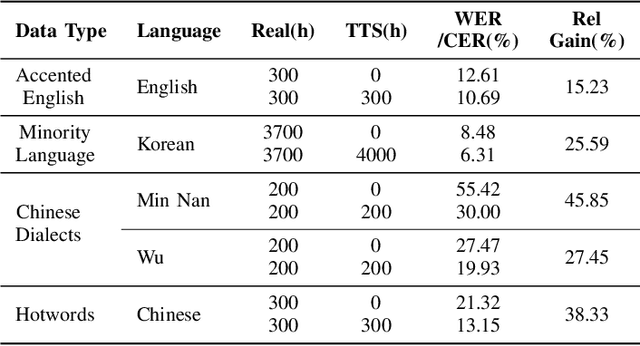

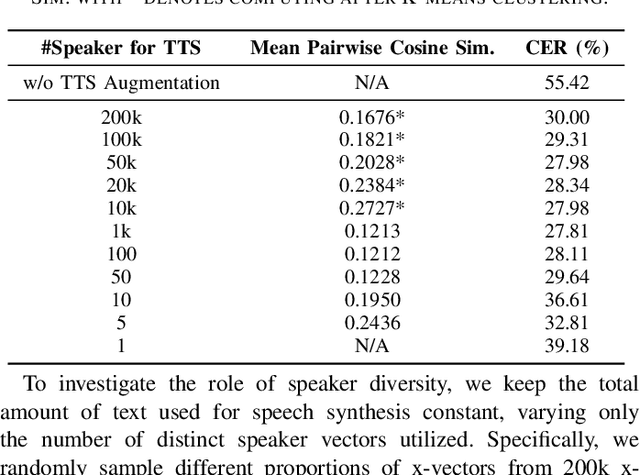
While automatic speech recognition (ASR) systems have achieved remarkable performance with large-scale datasets, their efficacy remains inadequate in low-resource settings, encompassing dialects, accents, minority languages, and long-tail hotwords, domains with significant practical relevance. With the advent of versatile and powerful text-to-speech (TTS) models, capable of generating speech with human-level naturalness, expressiveness, and diverse speaker profiles, leveraging TTS for ASR data augmentation provides a cost-effective and practical approach to enhancing ASR performance. Comprehensive experiments on an unprecedentedly rich variety of low-resource datasets demonstrate consistent and substantial performance improvements, proving that the proposed method of enhancing low-resource ASR through a versatile TTS model is highly effective and has broad application prospects. Furthermore, we delve deeper into key characteristics of synthesized speech data that contribute to ASR improvement, examining factors such as text diversity, speaker diversity, and the volume of synthesized data, with text diversity being studied for the first time in this work. We hope our findings provide helpful guidance and reference for the practical application of TTS-based data augmentation and push the advancement of low-resource ASR one step further.
IntrinsicVoice: Empowering LLMs with Intrinsic Real-time Voice Interaction Abilities
Oct 09, 2024



Current methods of building LLMs with voice interaction capabilities rely heavily on explicit text autoregressive generation before or during speech response generation to maintain content quality, which unfortunately brings computational overhead and increases latency in multi-turn interactions. To address this, we introduce IntrinsicVoic,e an LLM designed with intrinsic real-time voice interaction capabilities. IntrinsicVoice aims to facilitate the transfer of textual capabilities of pre-trained LLMs to the speech modality by mitigating the modality gap between text and speech. Our novelty architecture, GroupFormer, can reduce speech sequences to lengths comparable to text sequences while generating high-quality audio, significantly reducing the length difference between speech and text, speeding up inference, and alleviating long-text modeling issues. Additionally, we construct a multi-turn speech-to-speech dialogue dataset named \method-500k which includes nearly 500k turns of speech-to-speech dialogues, and a cross-modality training strategy to enhance the semantic alignment between speech and text. Experimental results demonstrate that IntrinsicVoice can generate high-quality speech response with latency lower than 100ms in multi-turn dialogue scenarios. Demos are available at https://instrinsicvoice.github.io/.
CosyVoice: A Scalable Multilingual Zero-shot Text-to-speech Synthesizer based on Supervised Semantic Tokens
Jul 09, 2024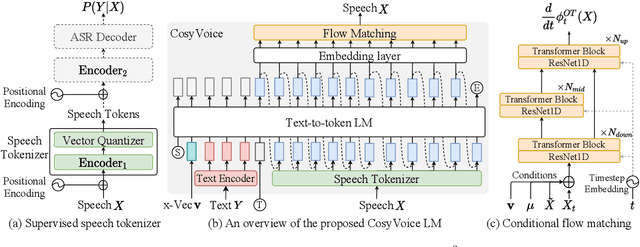

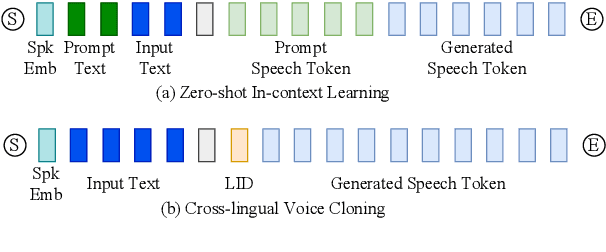
Recent years have witnessed a trend that large language model (LLM) based text-to-speech (TTS) emerges into the mainstream due to their high naturalness and zero-shot capacity. In this paradigm, speech signals are discretized into token sequences, which are modeled by an LLM with text as prompts and reconstructed by a token-based vocoder to waveforms. Obviously, speech tokens play a critical role in LLM-based TTS models. Current speech tokens are learned in an unsupervised manner, which lacks explicit semantic information and alignment to the text. In this paper, we propose to represent speech with supervised semantic tokens, which are derived from a multilingual speech recognition model by inserting vector quantization into the encoder. Based on the tokens, we further propose a scalable zero-shot TTS synthesizer, CosyVoice, which consists of an LLM for text-to-token generation and a conditional flow matching model for token-to-speech synthesis. Experimental results show that supervised semantic tokens significantly outperform existing unsupervised tokens in terms of content consistency and speaker similarity for zero-shot voice cloning. Moreover, we find that utilizing large-scale data further improves the synthesis performance, indicating the scalable capacity of CosyVoice. To the best of our knowledge, this is the first attempt to involve supervised speech tokens into TTS models.
An Embarrassingly Simple Approach for LLM with Strong ASR Capacity
Feb 13, 2024In this paper, we focus on solving one of the most important tasks in the field of speech processing, i.e., automatic speech recognition (ASR), with speech foundation encoders and large language models (LLM). Recent works have complex designs such as compressing the output temporally for the speech encoder, tackling modal alignment for the projector, and utilizing parameter-efficient fine-tuning for the LLM. We found that delicate designs are not necessary, while an embarrassingly simple composition of off-the-shelf speech encoder, LLM, and the only trainable linear projector is competent for the ASR task. To be more specific, we benchmark and explore various combinations of LLMs and speech encoders, leading to the optimal LLM-based ASR system, which we call SLAM-ASR. The proposed SLAM-ASR provides a clean setup and little task-specific design, where only the linear projector is trained. To the best of our knowledge, SLAM-ASR achieves the best performance on the Librispeech benchmark among LLM-based ASR models and even outperforms the latest LLM-based audio-universal model trained on massive pair data. Finally, we explore the capability emergence of LLM-based ASR in the process of modal alignment. We hope that our study can facilitate the research on extending LLM with cross-modality capacity and shed light on the LLM-based ASR community.