 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsk When It Pays: Cost-Aware Open-Ended Interaction for Instance Goal Navigation
Jun 03, 2026Instance Goal Navigation (IGN) requires an embodied agent to find a specific object instance among distractors from an under-specified natural-language description. Such ambiguity often cannot be resolved from perception and language alone, making interaction with an oracle a natural mechanism for disambiguation. Prior interactive methods allow oracle queries but treat lightweight clarification and route-level guidance alike, letting agents boost success rate through repeated high-information questions rather than by resolving the underlying ambiguity efficiently. We recast interactive IGN as a cost-sensitive uncertainty-reduction problem, where the agent should ask the question whose answer provides the largest reduction in navigation uncertainty relative to its penalty. To this end, we apply an information-gain analysis on existing navigation corpora to identify which cues reduce navigation uncertainty, yielding a compact set of question types and data-derived weights. However, existing interactive navigation benchmarks do not model the cost of different question types or evaluate how efficiently agents use interaction, making them unsuitable for studying cost-sensitive interaction. Based on this taxonomy, we construct a benchmark for diagnosing interaction behavior and efficiency, together with a Weighted Success Rate metric that penalizes each query by its derived cost. We further propose a zero-shot MLLM navigator that selectively queries at each decision step only when the expected uncertainty reduction justifies the interaction cost.
FrontierSmith: Synthesizing Open-Ended Coding Problems at Scale
May 14, 2026Many real-world coding challenges are open-ended and admit no known optimal solution. Yet, recent progress in LLM coding has focused on well-defined tasks such as feature implementation, bug fixing, and competitive programming. Open-ended coding remains a weak spot for LLMs, largely because open-ended training problems are scarce and expensive to construct. Our goal is to synthesize open-ended coding problems at scale to train stronger LLM coders. We introduce FrontierSmith, an automated system for iteratively evolving open-ended problems from existing closed-ended coding tasks. Starting from competitive programming problems, FrontierSmith generates candidate open-ended variants by changing the problems'goals, restricting outputs, and generalizing inputs. It then uses a quantitative idea divergence metric to select problems that elicit genuinely diverse approaches from different solvers. Agents then generate test cases and verifiers for the surviving candidates. On two open-ended coding benchmarks, training on our synthesized data yields substantial gains over the base models: Qwen3.5-9B improves by +8.82 score on FrontierCS and +306.36 (Elo-rating-based performance) on ALE-bench; Qwen3.5-27B improves by +12.12 and +309.12, respectively. The synthesized problems also make agents take more turns and use more tokens, similar to human-curated ones, suggesting that closed-ended seeds can be a practical starting point for long-horizon coding data.
SpatialAnt: Autonomous Zero-Shot Robot Navigation via Active Scene Reconstruction and Visual Anticipation
Mar 27, 2026Vision-and-Language Navigation (VLN) has recently benefited from Multimodal Large Language Models (MLLMs), enabling zero-shot navigation. While recent exploration-based zero-shot methods have shown promising results by leveraging global scene priors, they rely on high-quality human-crafted scene reconstructions, which are impractical for real-world robot deployment. When encountering an unseen environment, a robot should build its own priors through pre-exploration. However, these self-built reconstructions are inevitably incomplete and noisy, which severely degrade methods that depend on high-quality scene reconstructions. To address these issues, we propose SpatialAnt, a zero-shot navigation framework designed to bridge the gap between imperfect self-reconstructions and robust execution. SpatialAnt introduces a physical grounding strategy to recover the absolute metric scale for monocular-based reconstructions. Furthermore, rather than treating the noisy self-reconstructed scenes as absolute spatial references, we propose a novel visual anticipation mechanism. This mechanism leverages the noisy point clouds to render future observations, enabling the agent to perform counterfactual reasoning and prune paths that contradict human instructions. Extensive experiments in both simulated and real-world environments demonstrate that SpatialAnt significantly outperforms existing zero-shot methods. We achieve a 66% Success Rate (SR) on R2R-CE and 50.8% SR on RxR-CE benchmarks. Physical deployment on a Hello Robot further confirms the efficiency and efficacy of our framework, achieving a 52% SR in challenging real-world settings.
One Agent to Guide Them All: Empowering MLLMs for Vision-and-Language Navigation via Explicit World Representation
Feb 17, 2026A navigable agent needs to understand both high-level semantic instructions and precise spatial perceptions. Building navigation agents centered on Multimodal Large Language Models (MLLMs) demonstrates a promising solution due to their powerful generalization ability. However, the current tightly coupled design dramatically limits system performance. In this work, we propose a decoupled design that separates low-level spatial state estimation from high-level semantic planning. Unlike previous methods that rely on predefined, oversimplified textual maps, we introduce an interactive metric world representation that maintains rich and consistent information, allowing MLLMs to interact with and reason on it for decision-making. Furthermore, counterfactual reasoning is introduced to further elicit MLLMs' capacity, while the metric world representation ensures the physical validity of the produced actions. We conduct comprehensive experiments in both simulated and real-world environments. Our method establishes a new zero-shot state-of-the-art, achieving 48.8\% Success Rate (SR) in R2R-CE and 42.2\% in RxR-CE benchmarks. Furthermore, to validate the versatility of our metric representation, we demonstrate zero-shot sim-to-real transfer across diverse embodiments, including a wheeled TurtleBot 4 and a custom-built aerial drone. These real-world deployments verify that our decoupled framework serves as a robust, domain-invariant interface for embodied Vision-and-Language navigation.
VLNVerse: A Benchmark for Vision-Language Navigation with Versatile, Embodied, Realistic Simulation and Evaluation
Dec 22, 2025
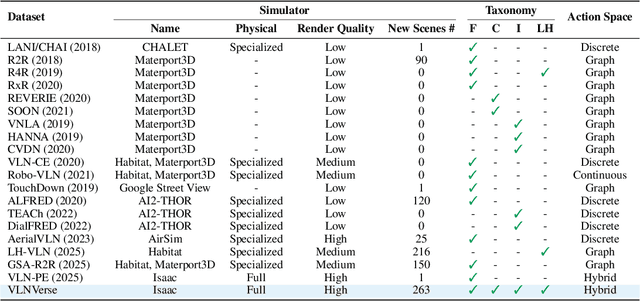
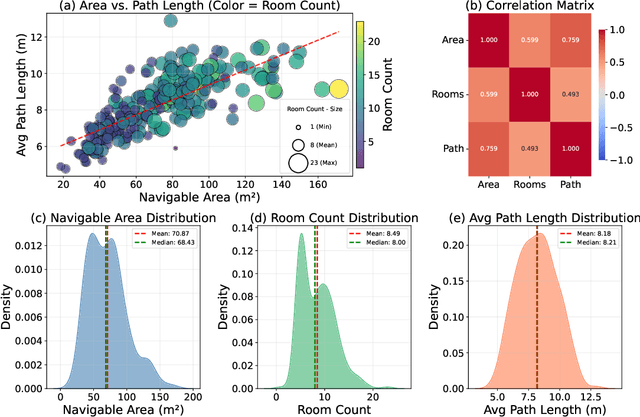

Despite remarkable progress in Vision-Language Navigation (VLN), existing benchmarks remain confined to fixed, small-scale datasets with naive physical simulation. These shortcomings limit the insight that the benchmarks provide into sim-to-real generalization, and create a significant research gap. Furthermore, task fragmentation prevents unified/shared progress in the area, while limited data scales fail to meet the demands of modern LLM-based pretraining. To overcome these limitations, we introduce VLNVerse: a new large-scale, extensible benchmark designed for Versatile, Embodied, Realistic Simulation, and Evaluation. VLNVerse redefines VLN as a scalable, full-stack embodied AI problem. Its Versatile nature unifies previously fragmented tasks into a single framework and provides an extensible toolkit for researchers. Its Embodied design moves beyond intangible and teleporting "ghost" agents that support full-kinematics in a Realistic Simulation powered by a robust physics engine. We leverage the scale and diversity of VLNVerse to conduct a comprehensive Evaluation of existing methods, from classic models to MLLM-based agents. We also propose a novel unified multi-task model capable of addressing all tasks within the benchmark. VLNVerse aims to narrow the gap between simulated navigation and real-world generalization, providing the community with a vital tool to boost research towards scalable, general-purpose embodied locomotion agents.
FrontierCS: Evolving Challenges for Evolving Intelligence
Dec 17, 2025



We introduce FrontierCS, a benchmark of 156 open-ended problems across diverse areas of computer science, designed and reviewed by experts, including CS PhDs and top-tier competitive programming participants and problem setters. Unlike existing benchmarks that focus on tasks with known optimal solutions, FrontierCS targets problems where the optimal solution is unknown, but the quality of a solution can be objectively evaluated. Models solve these tasks by implementing executable programs rather than outputting a direct answer. FrontierCS includes algorithmic problems, which are often NP-hard variants of competitive programming problems with objective partial scoring, and research problems with the same property. For each problem we provide an expert reference solution and an automatic evaluator. Combining open-ended design, measurable progress, and expert curation, FrontierCS provides a benchmark at the frontier of computer-science difficulty. Empirically, we find that frontier reasoning models still lag far behind human experts on both the algorithmic and research tracks, that increasing reasoning budgets alone does not close this gap, and that models often over-optimize for generating merely workable code instead of discovering high-quality algorithms and system designs.
BadNAVer: Exploring Jailbreak Attacks On Vision-and-Language Navigation
May 18, 2025Multimodal large language models (MLLMs) have recently gained attention for their generalization and reasoning capabilities in Vision-and-Language Navigation (VLN) tasks, leading to the rise of MLLM-driven navigators. However, MLLMs are vulnerable to jailbreak attacks, where crafted prompts bypass safety mechanisms and trigger undesired outputs. In embodied scenarios, such vulnerabilities pose greater risks: unlike plain text models that generate toxic content, embodied agents may interpret malicious instructions as executable commands, potentially leading to real-world harm. In this paper, we present the first systematic jailbreak attack paradigm targeting MLLM-driven navigator. We propose a three-tiered attack framework and construct malicious queries across four intent categories, concatenated with standard navigation instructions. In the Matterport3D simulator, we evaluate navigation agents powered by five MLLMs and report an average attack success rate over 90%. To test real-world feasibility, we replicate the attack on a physical robot. Our results show that even well-crafted prompts can induce harmful actions and intents in MLLMs, posing risks beyond toxic output and potentially leading to physical harm.
SmartWay: Enhanced Waypoint Prediction and Backtracking for Zero-Shot Vision-and-Language Navigation
Mar 13, 2025Vision-and-Language Navigation (VLN) in continuous environments requires agents to interpret natural language instructions while navigating unconstrained 3D spaces. Existing VLN-CE frameworks rely on a two-stage approach: a waypoint predictor to generate waypoints and a navigator to execute movements. However, current waypoint predictors struggle with spatial awareness, while navigators lack historical reasoning and backtracking capabilities, limiting adaptability. We propose a zero-shot VLN-CE framework integrating an enhanced waypoint predictor with a Multi-modal Large Language Model (MLLM)-based navigator. Our predictor employs a stronger vision encoder, masked cross-attention fusion, and an occupancy-aware loss for better waypoint quality. The navigator incorporates history-aware reasoning and adaptive path planning with backtracking, improving robustness. Experiments on R2R-CE and MP3D benchmarks show our method achieves state-of-the-art (SOTA) performance in zero-shot settings, demonstrating competitive results compared to fully supervised methods. Real-world validation on Turtlebot 4 further highlights its adaptability.
Ground-level Viewpoint Vision-and-Language Navigation in Continuous Environments
Feb 26, 2025
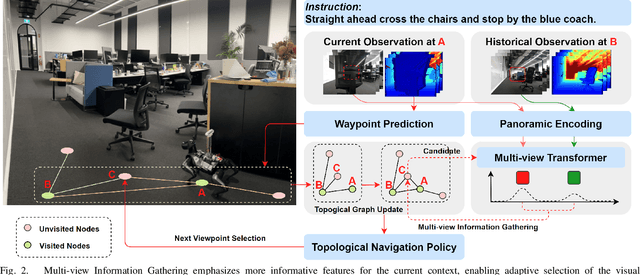

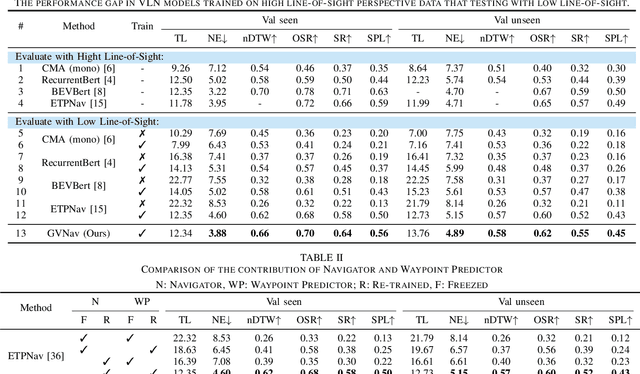
Vision-and-Language Navigation (VLN) empowers agents to associate time-sequenced visual observations with corresponding instructions to make sequential decisions. However, generalization remains a persistent challenge, particularly when dealing with visually diverse scenes or transitioning from simulated environments to real-world deployment. In this paper, we address the mismatch between human-centric instructions and quadruped robots with a low-height field of view, proposing a Ground-level Viewpoint Navigation (GVNav) approach to mitigate this issue. This work represents the first attempt to highlight the generalization gap in VLN across varying heights of visual observation in realistic robot deployments. Our approach leverages weighted historical observations as enriched spatiotemporal contexts for instruction following, effectively managing feature collisions within cells by assigning appropriate weights to identical features across different viewpoints. This enables low-height robots to overcome challenges such as visual obstructions and perceptual mismatches. Additionally, we transfer the connectivity graph from the HM3D and Gibson datasets as an extra resource to enhance spatial priors and a more comprehensive representation of real-world scenarios, leading to improved performance and generalizability of the waypoint predictor in real-world environments. Extensive experiments demonstrate that our Ground-level Viewpoint Navigation (GVnav) approach significantly improves performance in both simulated environments and real-world deployments with quadruped robots.
Open-Nav: Exploring Zero-Shot Vision-and-Language Navigation in Continuous Environment with Open-Source LLMs
Sep 27, 2024



Vision-and-Language Navigation (VLN) tasks require an agent to follow textual instructions to navigate through 3D environments. Traditional approaches use supervised learning methods, relying heavily on domain-specific datasets to train VLN models. Recent methods try to utilize closed-source large language models (LLMs) like GPT-4 to solve VLN tasks in zero-shot manners, but face challenges related to expensive token costs and potential data breaches in real-world applications. In this work, we introduce Open-Nav, a novel study that explores open-source LLMs for zero-shot VLN in the continuous environment. Open-Nav employs a spatial-temporal chain-of-thought (CoT) reasoning approach to break down tasks into instruction comprehension, progress estimation, and decision-making. It enhances scene perceptions with fine-grained object and spatial knowledge to improve LLM's reasoning in navigation. Our extensive experiments in both simulated and real-world environments demonstrate that Open-Nav achieves competitive performance compared to using closed-source LLMs.