 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightMover: Generative Light Movement with Color and Intensity Controls
Mar 28, 2026We present LightMover, a framework for controllable light manipulation in single images that leverages video diffusion priors to produce physically plausible illumination changes without re-rendering the scene. We formulate light editing as a sequence-to-sequence prediction problem in visual token space: given an image and light-control tokens, the model adjusts light position, color, and intensity together with resulting reflections, shadows, and falloff from a single view. This unified treatment of spatial (movement) and appearance (color, intensity) controls improves both manipulation and illumination understanding. We further introduce an adaptive token-pruning mechanism that preserves spatially informative tokens while compactly encoding non-spatial attributes, reducing control sequence length by 41% while maintaining editing fidelity. To train our framework, we construct a scalable rendering pipeline that generates large numbers of image pairs across varied light positions, colors, and intensities while keeping the scene content consistent with the original image. LightMover enables precise, independent control over light position, color, and intensity, and achieves high PSNR and strong semantic consistency (DINO, CLIP) across different tasks.
VLN-MME: Diagnosing MLLMs as Language-guided Visual Navigation agents
Dec 31, 2025Multimodal Large Language Models (MLLMs) have demonstrated remarkable capabilities across a wide range of vision-language tasks. However, their performance as embodied agents, which requires multi-round dialogue spatial reasoning and sequential action prediction, needs further exploration. Our work investigates this potential in the context of Vision-and-Language Navigation (VLN) by introducing a unified and extensible evaluation framework to probe MLLMs as zero-shot agents by bridging traditional navigation datasets into a standardized benchmark, named VLN-MME. We simplify the evaluation with a highly modular and accessible design. This flexibility streamlines experiments, enabling structured comparisons and component-level ablations across diverse MLLM architectures, agent designs, and navigation tasks. Crucially, enabled by our framework, we observe that enhancing our baseline agent with Chain-of-Thought (CoT) reasoning and self-reflection leads to an unexpected performance decrease. This suggests MLLMs exhibit poor context awareness in embodied navigation tasks; although they can follow instructions and structure their output, their 3D spatial reasoning fidelity is low. VLN-MME lays the groundwork for systematic evaluation of general-purpose MLLMs in embodied navigation settings and reveals limitations in their sequential decision-making capabilities. We believe these findings offer crucial guidance for MLLM post-training as embodied agents.
VLNVerse: A Benchmark for Vision-Language Navigation with Versatile, Embodied, Realistic Simulation and Evaluation
Dec 22, 2025
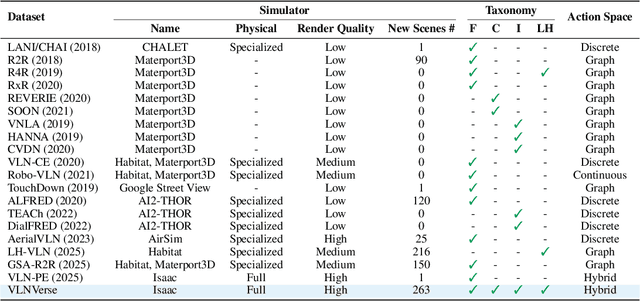
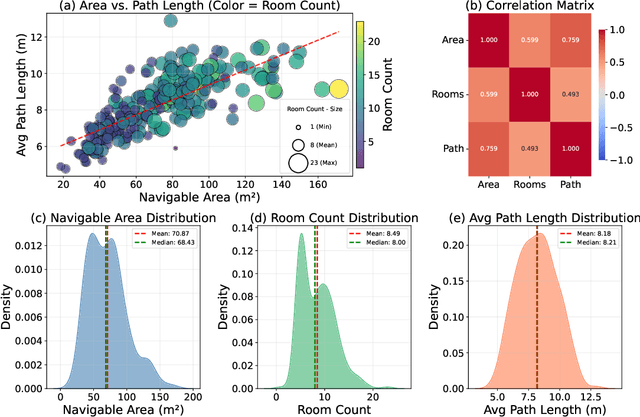

Despite remarkable progress in Vision-Language Navigation (VLN), existing benchmarks remain confined to fixed, small-scale datasets with naive physical simulation. These shortcomings limit the insight that the benchmarks provide into sim-to-real generalization, and create a significant research gap. Furthermore, task fragmentation prevents unified/shared progress in the area, while limited data scales fail to meet the demands of modern LLM-based pretraining. To overcome these limitations, we introduce VLNVerse: a new large-scale, extensible benchmark designed for Versatile, Embodied, Realistic Simulation, and Evaluation. VLNVerse redefines VLN as a scalable, full-stack embodied AI problem. Its Versatile nature unifies previously fragmented tasks into a single framework and provides an extensible toolkit for researchers. Its Embodied design moves beyond intangible and teleporting "ghost" agents that support full-kinematics in a Realistic Simulation powered by a robust physics engine. We leverage the scale and diversity of VLNVerse to conduct a comprehensive Evaluation of existing methods, from classic models to MLLM-based agents. We also propose a novel unified multi-task model capable of addressing all tasks within the benchmark. VLNVerse aims to narrow the gap between simulated navigation and real-world generalization, providing the community with a vital tool to boost research towards scalable, general-purpose embodied locomotion agents.
MMGR: Multi-Modal Generative Reasoning
Dec 17, 2025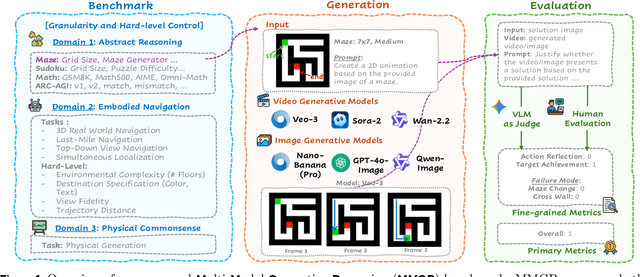
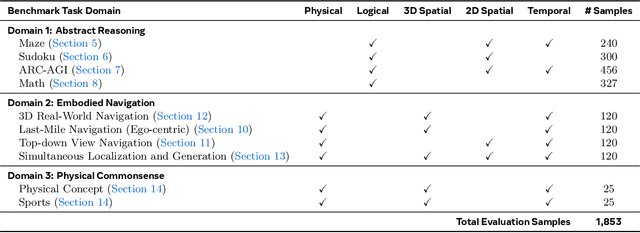

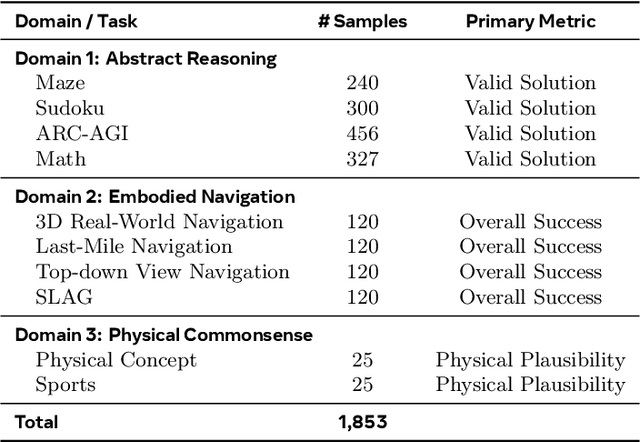
Video foundation models generate visually realistic and temporally coherent content, but their reliability as world simulators depends on whether they capture physical, logical, and spatial constraints. Existing metrics such as Frechet Video Distance (FVD) emphasize perceptual quality and overlook reasoning failures, including violations of causality, physics, and global consistency. We introduce MMGR (Multi-Modal Generative Reasoning Evaluation and Benchmark), a principled evaluation framework based on five reasoning abilities: Physical, Logical, 3D Spatial, 2D Spatial, and Temporal. MMGR evaluates generative reasoning across three domains: Abstract Reasoning (ARC-AGI, Sudoku), Embodied Navigation (real-world 3D navigation and localization), and Physical Commonsense (sports and compositional interactions). MMGR applies fine-grained metrics that require holistic correctness across both video and image generation. We benchmark leading video models (Veo-3, Sora-2, Wan-2.2) and image models (Nano-banana, Nano-banana Pro, GPT-4o-image, Qwen-image), revealing strong performance gaps across domains. Models show moderate success on Physical Commonsense tasks but perform poorly on Abstract Reasoning (below 10 percent accuracy on ARC-AGI) and struggle with long-horizon spatial planning in embodied settings. Our analysis highlights key limitations in current models, including overreliance on perceptual data, weak global state consistency, and objectives that reward visual plausibility over causal correctness. MMGR offers a unified diagnostic benchmark and a path toward reasoning-aware generative world models.
Ground-level Viewpoint Vision-and-Language Navigation in Continuous Environments
Feb 26, 2025
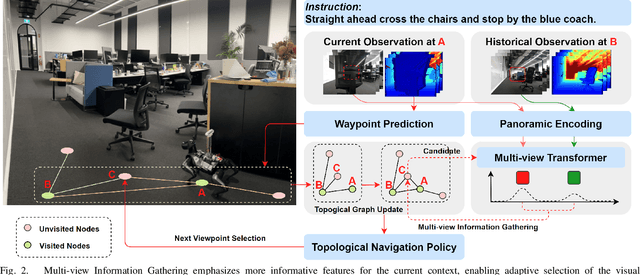

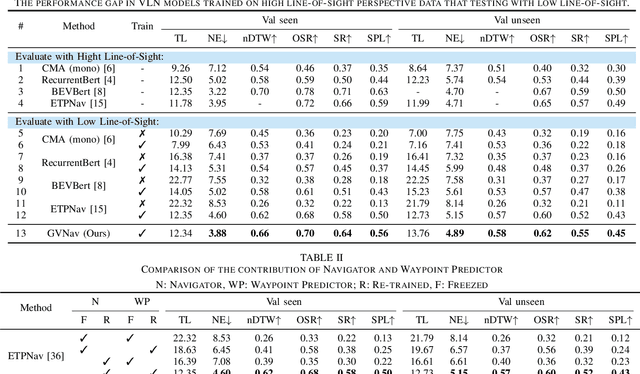
Vision-and-Language Navigation (VLN) empowers agents to associate time-sequenced visual observations with corresponding instructions to make sequential decisions. However, generalization remains a persistent challenge, particularly when dealing with visually diverse scenes or transitioning from simulated environments to real-world deployment. In this paper, we address the mismatch between human-centric instructions and quadruped robots with a low-height field of view, proposing a Ground-level Viewpoint Navigation (GVNav) approach to mitigate this issue. This work represents the first attempt to highlight the generalization gap in VLN across varying heights of visual observation in realistic robot deployments. Our approach leverages weighted historical observations as enriched spatiotemporal contexts for instruction following, effectively managing feature collisions within cells by assigning appropriate weights to identical features across different viewpoints. This enables low-height robots to overcome challenges such as visual obstructions and perceptual mismatches. Additionally, we transfer the connectivity graph from the HM3D and Gibson datasets as an extra resource to enhance spatial priors and a more comprehensive representation of real-world scenarios, leading to improved performance and generalizability of the waypoint predictor in real-world environments. Extensive experiments demonstrate that our Ground-level Viewpoint Navigation (GVnav) approach significantly improves performance in both simulated environments and real-world deployments with quadruped robots.
SAME: Learning Generic Language-Guided Visual Navigation with State-Adaptive Mixture of Experts
Dec 07, 2024The academic field of learning instruction-guided visual navigation can be generally categorized into high-level category-specific search and low-level language-guided navigation, depending on the granularity of language instruction, in which the former emphasizes the exploration process, while the latter concentrates on following detailed textual commands. Despite the differing focuses of these tasks, the underlying requirements of interpreting instructions, comprehending the surroundings, and inferring action decisions remain consistent. This paper consolidates diverse navigation tasks into a unified and generic framework -- we investigate the core difficulties of sharing general knowledge and exploiting task-specific capabilities in learning navigation and propose a novel State-Adaptive Mixture of Experts (SAME) model that effectively enables an agent to infer decisions based on different-granularity language and dynamic observations. Powered by SAME, we present a versatile agent capable of addressing seven navigation tasks simultaneously that outperforms or achieves highly comparable performance to task-specific agents.
NavGPT-2: Unleashing Navigational Reasoning Capability for Large Vision-Language Models
Jul 17, 2024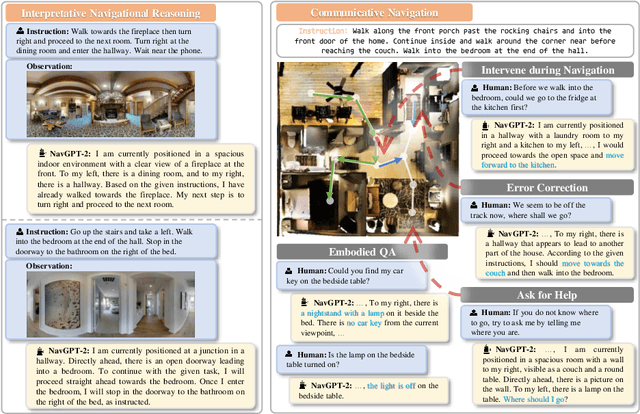
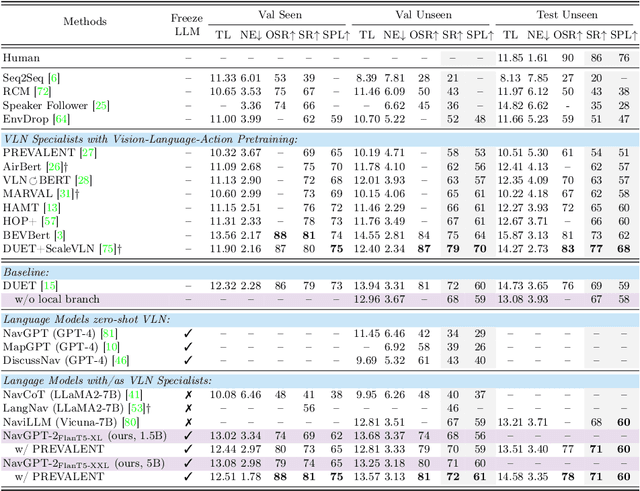
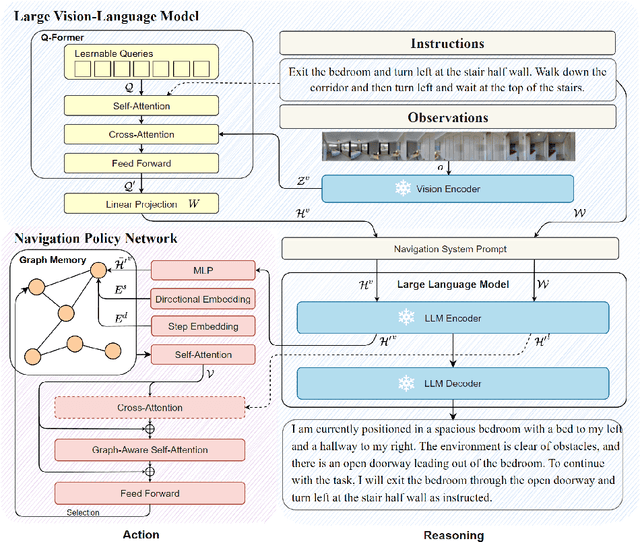

Capitalizing on the remarkable advancements in Large Language Models (LLMs), there is a burgeoning initiative to harness LLMs for instruction following robotic navigation. Such a trend underscores the potential of LLMs to generalize navigational reasoning and diverse language understanding. However, a significant discrepancy in agent performance is observed when integrating LLMs in the Vision-and-Language navigation (VLN) tasks compared to previous downstream specialist models. Furthermore, the inherent capacity of language to interpret and facilitate communication in agent interactions is often underutilized in these integrations. In this work, we strive to bridge the divide between VLN-specialized models and LLM-based navigation paradigms, while maintaining the interpretative prowess of LLMs in generating linguistic navigational reasoning. By aligning visual content in a frozen LLM, we encompass visual observation comprehension for LLMs and exploit a way to incorporate LLMs and navigation policy networks for effective action predictions and navigational reasoning. We demonstrate the data efficiency of the proposed methods and eliminate the gap between LM-based agents and state-of-the-art VLN specialists.
NaVid: Video-based VLM Plans the Next Step for Vision-and-Language Navigation
Mar 01, 2024



Vision-and-Language Navigation (VLN) stands as a key research problem of Embodied AI, aiming at enabling agents to navigate in unseen environments following linguistic instructions. In this field, generalization is a long-standing challenge, either to out-of-distribution scenes or from Sim to Real. In this paper, we propose NaVid, a video-based large vision language model (VLM), to mitigate such a generalization gap. NaVid makes the first endeavour to showcase the capability of VLMs to achieve state-of-the-art level navigation performance without any maps, odometer and depth inputs. Following human instruction, NaVid only requires an on-the-fly video stream from a monocular RGB camera equipped on the robot to output the next-step action. Our formulation mimics how humans navigate and naturally gets rid of the problems introduced by odometer noises, and the Sim2Real gaps from map or depth inputs. Moreover, our video-based approach can effectively encode the historical observations of robots as spatio-temporal contexts for decision-making and instruction following. We train NaVid with 550k navigation samples collected from VLN-CE trajectories, including action-planning and instruction-reasoning samples, along with 665k large-scale web data. Extensive experiments show that NaVid achieves SOTA performance in simulation environments and the real world, demonstrating superior cross-dataset and Sim2Real transfer. We thus believe our proposed VLM approach plans the next step for not only the navigation agents but also this research field.
WebVLN: Vision-and-Language Navigation on Websites
Dec 25, 2023Vision-and-Language Navigation (VLN) task aims to enable AI agents to accurately understand and follow natural language instructions to navigate through real-world environments, ultimately reaching specific target locations. We recognise a promising opportunity to extend VLN to a comparable navigation task that holds substantial significance in our daily lives, albeit within the virtual realm: navigating websites on the Internet. This paper proposes a new task named Vision-and-Language Navigation on Websites (WebVLN), where we use question-based instructions to train an agent, emulating how users naturally browse websites. Unlike the existing VLN task that only pays attention to vision and instruction (language), the WebVLN agent further considers underlying web-specific content like HTML, which could not be seen on the rendered web pages yet contains rich visual and textual information. Toward this goal, we contribute a dataset, WebVLN-v1, and introduce a novel approach called Website-aware VLN Network (WebVLN-Net), which is built upon the foundation of state-of-the-art VLN techniques. Experimental results show that WebVLN-Net outperforms current VLN and web-related navigation methods. We believe that the introduction of the new WebVLN task and its dataset will establish a new dimension within the VLN domain and contribute to the broader vision-and-language research community. The code is available at: https://github.com/WebVLN/WebVLN.
NavGPT: Explicit Reasoning in Vision-and-Language Navigation with Large Language Models
May 29, 2023



Trained with an unprecedented scale of data, large language models (LLMs) like ChatGPT and GPT-4 exhibit the emergence of significant reasoning abilities from model scaling. Such a trend underscored the potential of training LLMs with unlimited language data, advancing the development of a universal embodied agent. In this work, we introduce the NavGPT, a purely LLM-based instruction-following navigation agent, to reveal the reasoning capability of GPT models in complex embodied scenes by performing zero-shot sequential action prediction for vision-and-language navigation (VLN). At each step, NavGPT takes the textual descriptions of visual observations, navigation history, and future explorable directions as inputs to reason the agent's current status, and makes the decision to approach the target. Through comprehensive experiments, we demonstrate NavGPT can explicitly perform high-level planning for navigation, including decomposing instruction into sub-goal, integrating commonsense knowledge relevant to navigation task resolution, identifying landmarks from observed scenes, tracking navigation progress, and adapting to exceptions with plan adjustment. Furthermore, we show that LLMs is capable of generating high-quality navigational instructions from observations and actions along a path, as well as drawing accurate top-down metric trajectory given the agent's navigation history. Despite the performance of using NavGPT to zero-shot R2R tasks still falling short of trained models, we suggest adapting multi-modality inputs for LLMs to use as visual navigation agents and applying the explicit reasoning of LLMs to benefit learning-based models.