 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsk When It Pays: Cost-Aware Open-Ended Interaction for Instance Goal Navigation
Jun 03, 2026Instance Goal Navigation (IGN) requires an embodied agent to find a specific object instance among distractors from an under-specified natural-language description. Such ambiguity often cannot be resolved from perception and language alone, making interaction with an oracle a natural mechanism for disambiguation. Prior interactive methods allow oracle queries but treat lightweight clarification and route-level guidance alike, letting agents boost success rate through repeated high-information questions rather than by resolving the underlying ambiguity efficiently. We recast interactive IGN as a cost-sensitive uncertainty-reduction problem, where the agent should ask the question whose answer provides the largest reduction in navigation uncertainty relative to its penalty. To this end, we apply an information-gain analysis on existing navigation corpora to identify which cues reduce navigation uncertainty, yielding a compact set of question types and data-derived weights. However, existing interactive navigation benchmarks do not model the cost of different question types or evaluate how efficiently agents use interaction, making them unsuitable for studying cost-sensitive interaction. Based on this taxonomy, we construct a benchmark for diagnosing interaction behavior and efficiency, together with a Weighted Success Rate metric that penalizes each query by its derived cost. We further propose a zero-shot MLLM navigator that selectively queries at each decision step only when the expected uncertainty reduction justifies the interaction cost.
IntentionNav: A Benchmark for Intent-Driven Object Navigation from Implicit Human Instruction
May 22, 2026Existing object navigation benchmarks usually tell an embodied agent which object category to find, such as microwave or chair. Human-facing embodied AI is often asked something less direct: "I need something to warm this food" or "the room feels stuffy." The agent must infer the object that can satisfy the need, find a scene-grounded instance, and decide whether the goal has been reached. We study this setting as intent-driven object navigation and introduce IntentionNav, a diagnostic benchmark for active object search from implicit human instructions. Each episode provides a free-text intent, RGB-D observations, and pose, but withholds the target object name. IntentionNav contains 500 intents over 176 Isaac Sim scenes and 64 target categories. Each intent is rewritten in four controlled instruction styles and annotated with one of four intent modes, separating surface phrasing from semantic cue type under matched geometry. This paired design supports analysis of target inference, language robustness, neighborhood reachability, and terminal success rather than only aggregate success. We evaluated three VLMs using a fixed active-navigation agent. Models identify the intended target in 48.3 percent of episodes and enter its 2 m neighborhood in 68.7 percent, but terminate successfully in only 24.9 percent and achieve grounded 1 m success in 5.5 percent. Success is highest for event-script intents (28.7 percent) and lower for physical-state and affordance intents (19.2 percent and 18.5 percent), showing that indirect human intent remains a bottleneck for target selection, visual verification, and terminal localization in active embodied search.
One Agent to Guide Them All: Empowering MLLMs for Vision-and-Language Navigation via Explicit World Representation
Feb 17, 2026A navigable agent needs to understand both high-level semantic instructions and precise spatial perceptions. Building navigation agents centered on Multimodal Large Language Models (MLLMs) demonstrates a promising solution due to their powerful generalization ability. However, the current tightly coupled design dramatically limits system performance. In this work, we propose a decoupled design that separates low-level spatial state estimation from high-level semantic planning. Unlike previous methods that rely on predefined, oversimplified textual maps, we introduce an interactive metric world representation that maintains rich and consistent information, allowing MLLMs to interact with and reason on it for decision-making. Furthermore, counterfactual reasoning is introduced to further elicit MLLMs' capacity, while the metric world representation ensures the physical validity of the produced actions. We conduct comprehensive experiments in both simulated and real-world environments. Our method establishes a new zero-shot state-of-the-art, achieving 48.8\% Success Rate (SR) in R2R-CE and 42.2\% in RxR-CE benchmarks. Furthermore, to validate the versatility of our metric representation, we demonstrate zero-shot sim-to-real transfer across diverse embodiments, including a wheeled TurtleBot 4 and a custom-built aerial drone. These real-world deployments verify that our decoupled framework serves as a robust, domain-invariant interface for embodied Vision-and-Language navigation.
VLNVerse: A Benchmark for Vision-Language Navigation with Versatile, Embodied, Realistic Simulation and Evaluation
Dec 22, 2025
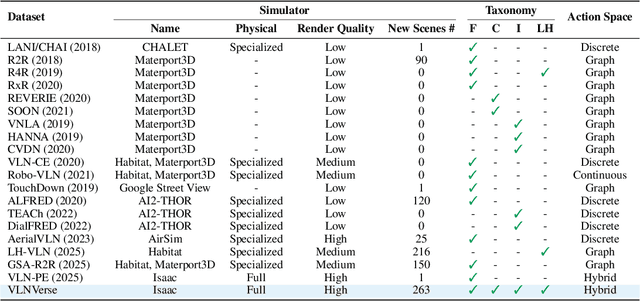
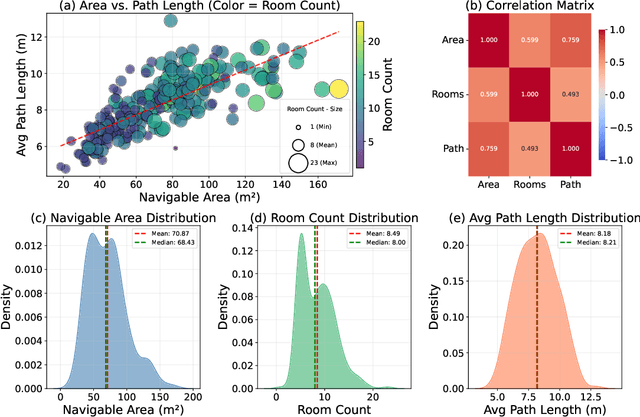

Despite remarkable progress in Vision-Language Navigation (VLN), existing benchmarks remain confined to fixed, small-scale datasets with naive physical simulation. These shortcomings limit the insight that the benchmarks provide into sim-to-real generalization, and create a significant research gap. Furthermore, task fragmentation prevents unified/shared progress in the area, while limited data scales fail to meet the demands of modern LLM-based pretraining. To overcome these limitations, we introduce VLNVerse: a new large-scale, extensible benchmark designed for Versatile, Embodied, Realistic Simulation, and Evaluation. VLNVerse redefines VLN as a scalable, full-stack embodied AI problem. Its Versatile nature unifies previously fragmented tasks into a single framework and provides an extensible toolkit for researchers. Its Embodied design moves beyond intangible and teleporting "ghost" agents that support full-kinematics in a Realistic Simulation powered by a robust physics engine. We leverage the scale and diversity of VLNVerse to conduct a comprehensive Evaluation of existing methods, from classic models to MLLM-based agents. We also propose a novel unified multi-task model capable of addressing all tasks within the benchmark. VLNVerse aims to narrow the gap between simulated navigation and real-world generalization, providing the community with a vital tool to boost research towards scalable, general-purpose embodied locomotion agents.
Decoupled Action Head: Confining Task Knowledge to Conditioning Layers
Nov 15, 2025Behavior Cloning (BC) is a data-driven supervised learning approach that has gained increasing attention with the success of scaling laws in language and vision domains. Among its implementations in robotic manipulation, Diffusion Policy (DP), with its two variants DP-CNN (DP-C) and DP-Transformer (DP-T), is one of the most effective and widely adopted models, demonstrating the advantages of predicting continuous action sequences. However, both DP and other BC methods remain constrained by the scarcity of paired training data, and the internal mechanisms underlying DP's effectiveness remain insufficiently understood, leading to limited generalization and a lack of principled design in model development. In this work, we propose a decoupled training recipe that leverages nearly cost-free kinematics-generated trajectories as observation-free data to pretrain a general action head (action generator). The pretrained action head is then frozen and adapted to novel tasks through feature modulation. Our experiments demonstrate the feasibility of this approach in both in-distribution and out-of-distribution scenarios. As an additional benefit, decoupling improves training efficiency; for instance, DP-C achieves up to a 41% speedup. Furthermore, the confinement of task-specific knowledge to the conditioning components under decoupling, combined with the near-identical performance of DP-C in both normal and decoupled training, indicates that the action generation backbone plays a limited role in robotic manipulation. Motivated by this observation, we introduce DP-MLP, which replaces the 244M-parameter U-Net backbone of DP-C with only 4M parameters of simple MLP blocks, achieving a 83.9% faster training speed under normal training and 89.1% under decoupling.
Learning A Zero-shot Occupancy Network from Vision Foundation Models via Self-supervised Adaptation
Mar 10, 2025

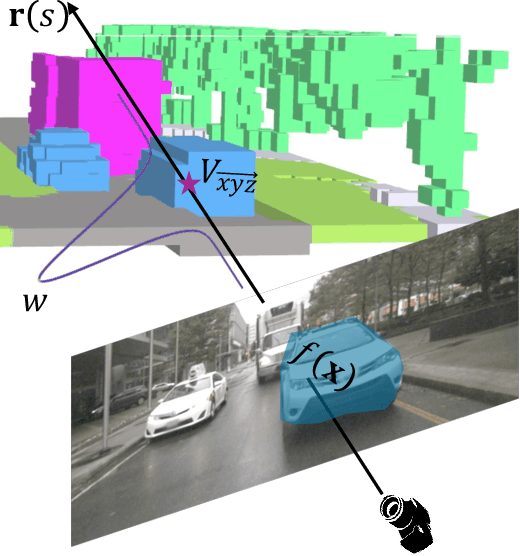

Estimating the 3D world from 2D monocular images is a fundamental yet challenging task due to the labour-intensive nature of 3D annotations. To simplify label acquisition, this work proposes a novel approach that bridges 2D vision foundation models (VFMs) with 3D tasks by decoupling 3D supervision into an ensemble of image-level primitives, e.g., semantic and geometric components. As a key motivator, we leverage the zero-shot capabilities of vision-language models for image semantics. However, due to the notorious ill-posed problem - multiple distinct 3D scenes can produce identical 2D projections, directly inferring metric depth from a monocular image in a zero-shot manner is unsuitable. In contrast, 2D VFMs provide promising sources of relative depth, which theoretically aligns with metric depth when properly scaled and offset. Thus, we adapt the relative depth derived from VFMs into metric depth by optimising the scale and offset using temporal consistency, also known as novel view synthesis, without access to ground-truth metric depth. Consequently, we project the semantics into 3D space using the reconstructed metric depth, thereby providing 3D supervision. Extensive experiments on nuScenes and SemanticKITTI demonstrate the effectiveness of our framework. For instance, the proposed method surpasses the current state-of-the-art by 3.34% mIoU on nuScenes for voxel occupancy prediction.
TransMamba: Fast Universal Architecture Adaption from Transformers to Mamba
Feb 21, 2025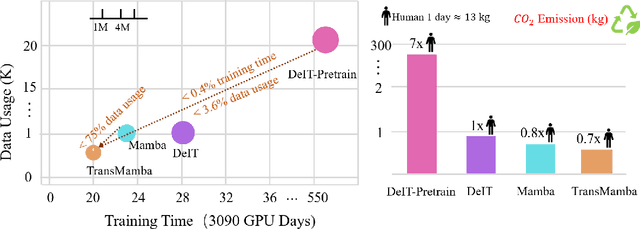
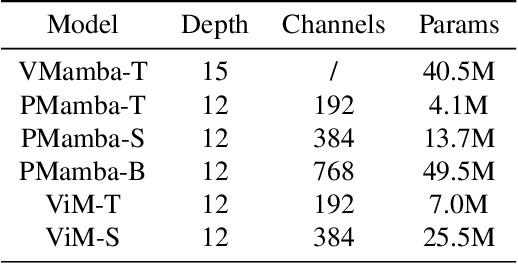
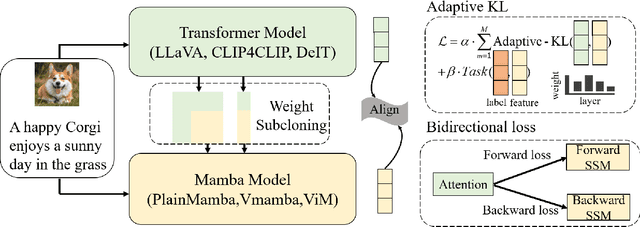
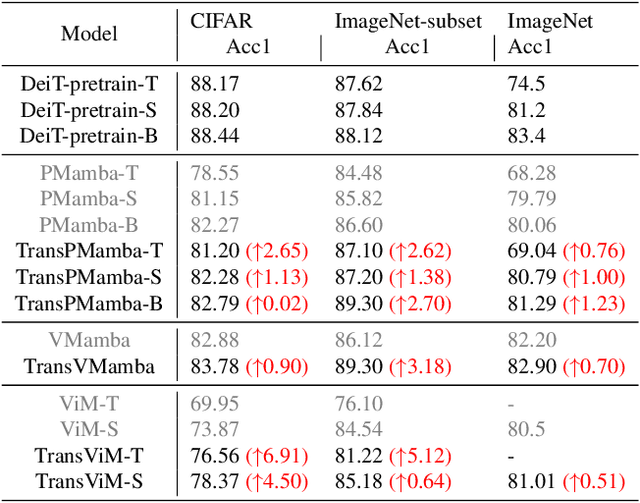
Transformers have been favored in both uni-modal and multi-modal foundation models for their flexible scalability in attention modules. Consequently, a number of pre-trained Transformer models, e.g., LLaVA, CLIP, and DEIT, are publicly available. Recent research has introduced subquadratic architectures like Mamba, which enables global awareness with linear complexity. Nevertheless, training specialized subquadratic architectures from scratch for certain tasks is both resource-intensive and time-consuming. As a motivator, we explore cross-architecture training to transfer the ready knowledge in existing Transformer models to alternative architecture Mamba, termed TransMamba. Our approach employs a two-stage strategy to expedite training new Mamba models, ensuring effectiveness in across uni-modal and cross-modal tasks. Concerning architecture disparities, we project the intermediate features into an aligned latent space before transferring knowledge. On top of that, a Weight Subcloning and Adaptive Bidirectional distillation method (WSAB) is introduced for knowledge transfer without limitations on varying layer counts. For cross-modal learning, we propose a cross-Mamba module that integrates language awareness into Mamba's visual features, enhancing the cross-modal interaction capabilities of Mamba architecture. Despite using less than 75% of the training data typically required for training from scratch, TransMamba boasts substantially stronger performance across various network architectures and downstream tasks, including image classification, visual question answering, and text-video retrieval. The code will be publicly available.
Making Large Language Models Better Planners with Reasoning-Decision Alignment
Aug 25, 2024Data-driven approaches for autonomous driving (AD) have been widely adopted in the past decade but are confronted with dataset bias and uninterpretability. Inspired by the knowledge-driven nature of human driving, recent approaches explore the potential of large language models (LLMs) to improve understanding and decision-making in traffic scenarios. They find that the pretrain-finetune paradigm of LLMs on downstream data with the Chain-of-Thought (CoT) reasoning process can enhance explainability and scene understanding. However, such a popular strategy proves to suffer from the notorious problems of misalignment between the crafted CoTs against the consequent decision-making, which remains untouched by previous LLM-based AD methods. To address this problem, we motivate an end-to-end decision-making model based on multimodality-augmented LLM, which simultaneously executes CoT reasoning and carries out planning results. Furthermore, we propose a reasoning-decision alignment constraint between the paired CoTs and planning results, imposing the correspondence between reasoning and decision-making. Moreover, we redesign the CoTs to enable the model to comprehend complex scenarios and enhance decision-making performance. We dub our proposed large language planners with reasoning-decision alignment as RDA-Driver. Experimental evaluations on the nuScenes and DriveLM-nuScenes benchmarks demonstrate the effectiveness of our RDA-Driver in enhancing the performance of end-to-end AD systems. Specifically, our RDA-Driver achieves state-of-the-art planning performance on the nuScenes dataset with 0.80 L2 error and 0.32 collision rate, and also achieves leading results on challenging DriveLM-nuScenes benchmarks with 0.82 L2 error and 0.38 collision rate.
MLP Can Be A Good Transformer Learner
Apr 08, 2024Self-attention mechanism is the key of the Transformer but often criticized for its computation demands. Previous token pruning works motivate their methods from the view of computation redundancy but still need to load the full network and require same memory costs. This paper introduces a novel strategy that simplifies vision transformers and reduces computational load through the selective removal of non-essential attention layers, guided by entropy considerations. We identify that regarding the attention layer in bottom blocks, their subsequent MLP layers, i.e. two feed-forward layers, can elicit the same entropy quantity. Meanwhile, the accompanied MLPs are under-exploited since they exhibit smaller feature entropy compared to those MLPs in the top blocks. Therefore, we propose to integrate the uninformative attention layers into their subsequent counterparts by degenerating them into identical mapping, yielding only MLP in certain transformer blocks. Experimental results on ImageNet-1k show that the proposed method can remove 40% attention layer of DeiT-B, improving throughput and memory bound without performance compromise. Code is available at https://github.com/sihaoevery/lambda_vit.
Self-Supervised Multi-Frame Neural Scene Flow
Mar 24, 2024



Neural Scene Flow Prior (NSFP) and Fast Neural Scene Flow (FNSF) have shown remarkable adaptability in the context of large out-of-distribution autonomous driving. Despite their success, the underlying reasons for their astonishing generalization capabilities remain unclear. Our research addresses this gap by examining the generalization capabilities of NSFP through the lens of uniform stability, revealing that its performance is inversely proportional to the number of input point clouds. This finding sheds light on NSFP's effectiveness in handling large-scale point cloud scene flow estimation tasks. Motivated by such theoretical insights, we further explore the improvement of scene flow estimation by leveraging historical point clouds across multiple frames, which inherently increases the number of point clouds. Consequently, we propose a simple and effective method for multi-frame point cloud scene flow estimation, along with a theoretical evaluation of its generalization abilities. Our analysis confirms that the proposed method maintains a limited generalization error, suggesting that adding multiple frames to the scene flow optimization process does not detract from its generalizability. Extensive experimental results on large-scale autonomous driving Waymo Open and Argoverse lidar datasets demonstrate that the proposed method achieves state-of-the-art performance.