 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning A Zero-shot Occupancy Network from Vision Foundation Models via Self-supervised Adaptation
Mar 10, 2025Estimating the 3D world from 2D monocular images is a fundamental yet challenging task due to the labour-intensive nature of 3D annotations. To simplify label acquisition, this work proposes a novel approach that bridges 2D vision foundation models (VFMs) with 3D tasks by decoupling 3D supervision into an ensemble of image-level primitives, e.g., semantic and geometric components. As a key motivator, we leverage the zero-shot capabilities of vision-language models for image semantics. However, due to the notorious ill-posed problem - multiple distinct 3D scenes can produce identical 2D projections, directly inferring metric depth from a monocular image in a zero-shot manner is unsuitable. In contrast, 2D VFMs provide promising sources of relative depth, which theoretically aligns with metric depth when properly scaled and offset. Thus, we adapt the relative depth derived from VFMs into metric depth by optimising the scale and offset using temporal consistency, also known as novel view synthesis, without access to ground-truth metric depth. Consequently, we project the semantics into 3D space using the reconstructed metric depth, thereby providing 3D supervision. Extensive experiments on nuScenes and SemanticKITTI demonstrate the effectiveness of our framework. For instance, the proposed method surpasses the current state-of-the-art by 3.34% mIoU on nuScenes for voxel occupancy prediction.
FAS: Fast ANN-SNN Conversion for Spiking Large Language Models
Feb 06, 2025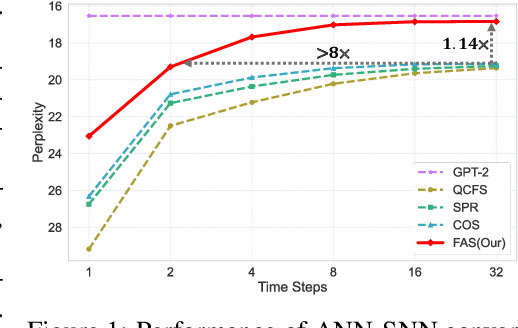
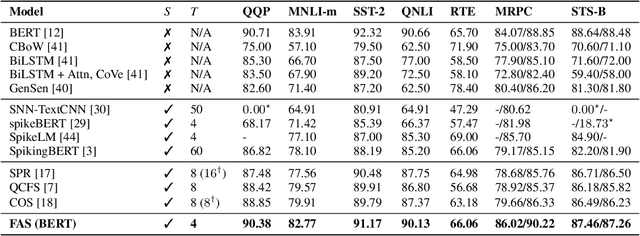
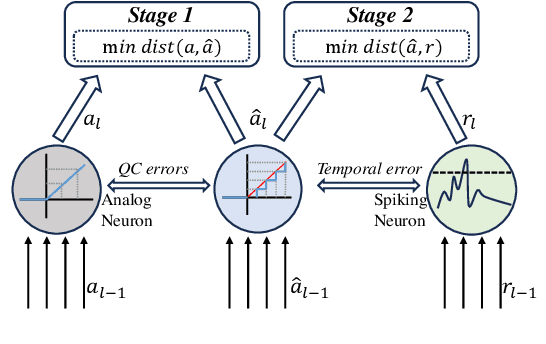
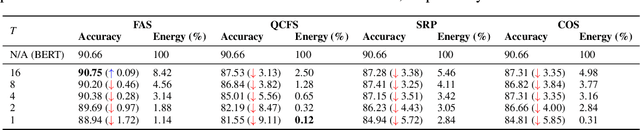
Spiking Large Language Models have been shown as a good alternative to LLMs in various scenarios. Existing methods for creating Spiking LLMs, i.e., direct training and ANN-SNN conversion, often suffer from performance degradation and relatively high computational costs. To address these issues, we propose a novel Fast ANN-SNN conversion strategy (FAS) that transforms LLMs into spiking LLMs in two stages. The first stage employs a full-parameter fine-tuning of pre-trained models, so it does not need any direct training from scratch. The second stage introduces a coarse-to-fine calibration method to reduce conversion errors and improve accuracy. Our experiments on both language and vision-language tasks across four different scales of LLMs demonstrate that FAS can achieve state-of-the-art performance yet with significantly reduced inference latency and computational costs. For example, FAS only takes 8 timesteps to achieve an accuracy of 3% higher than that of the OPT-7B model, while reducing energy consumption by 96.63%.
Membership Inference Attack Should Move On to Distributional Statistics for Distilled Generative Models
Feb 05, 2025



Membership inference attacks (MIAs) determine whether certain data instances were used to train a model by exploiting the differences in how the model responds to seen versus unseen instances. This capability makes MIAs important in assessing privacy leakage within modern generative AI systems. However, this paper reveals an oversight in existing MIAs against \emph{distilled generative models}: attackers can no longer detect a teacher model's training instances individually when targeting the distilled student model, as the student learns from the teacher-generated data rather than its original member data, preventing direct instance-level memorization. Nevertheless, we find that student-generated samples exhibit a significantly stronger distributional alignment with teacher's member data than non-member data. This leads us to posit that MIAs \emph{on distilled generative models should shift from instance-level to distribution-level statistics}. We thereby introduce a \emph{set-based} MIA framework that measures \emph{relative} distributional discrepancies between student-generated data\emph{sets} and potential member/non-member data\emph{sets}, Empirically, distributional statistics reliably distinguish a teacher's member data from non-member data through the distilled model. Finally, we discuss scenarios in which our setup faces limitations.
MLP Can Be A Good Transformer Learner
Apr 08, 2024Self-attention mechanism is the key of the Transformer but often criticized for its computation demands. Previous token pruning works motivate their methods from the view of computation redundancy but still need to load the full network and require same memory costs. This paper introduces a novel strategy that simplifies vision transformers and reduces computational load through the selective removal of non-essential attention layers, guided by entropy considerations. We identify that regarding the attention layer in bottom blocks, their subsequent MLP layers, i.e. two feed-forward layers, can elicit the same entropy quantity. Meanwhile, the accompanied MLPs are under-exploited since they exhibit smaller feature entropy compared to those MLPs in the top blocks. Therefore, we propose to integrate the uninformative attention layers into their subsequent counterparts by degenerating them into identical mapping, yielding only MLP in certain transformer blocks. Experimental results on ImageNet-1k show that the proposed method can remove 40% attention layer of DeiT-B, improving throughput and memory bound without performance compromise. Code is available at https://github.com/sihaoevery/lambda_vit.
SWAP-NAS: Sample-Wise Activation Patterns for Ultra-fast NAS
Mar 13, 2024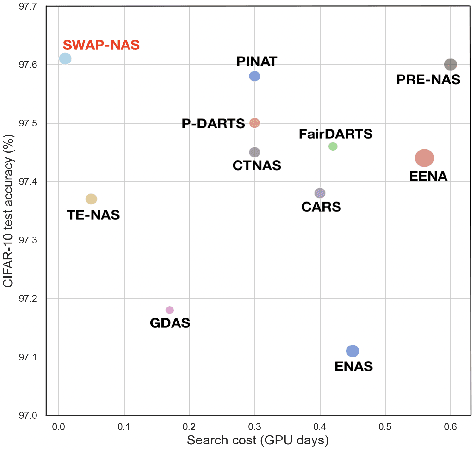
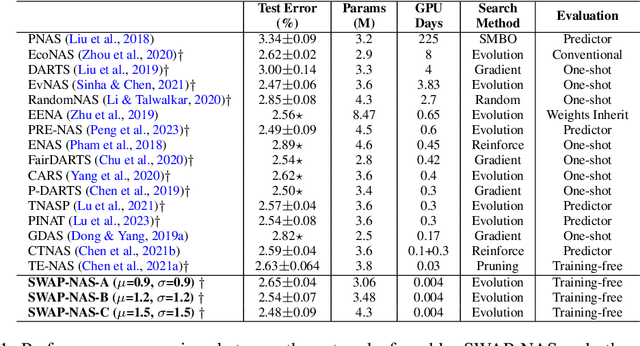

Training-free metrics (a.k.a. zero-cost proxies) are widely used to avoid resource-intensive neural network training, especially in Neural Architecture Search (NAS). Recent studies show that existing training-free metrics have several limitations, such as limited correlation and poor generalisation across different search spaces and tasks. Hence, we propose Sample-Wise Activation Patterns and its derivative, SWAP-Score, a novel high-performance training-free metric. It measures the expressivity of networks over a batch of input samples. The SWAP-Score is strongly correlated with ground-truth performance across various search spaces and tasks, outperforming 15 existing training-free metrics on NAS-Bench-101/201/301 and TransNAS-Bench-101. The SWAP-Score can be further enhanced by regularisation, which leads to even higher correlations in cell-based search space and enables model size control during the search. For example, Spearman's rank correlation coefficient between regularised SWAP-Score and CIFAR-100 validation accuracies on NAS-Bench-201 networks is 0.90, significantly higher than 0.80 from the second-best metric, NWOT. When integrated with an evolutionary algorithm for NAS, our SWAP-NAS achieves competitive performance on CIFAR-10 and ImageNet in approximately 6 minutes and 9 minutes of GPU time respectively.
PRE-NAS: Predictor-assisted Evolutionary Neural Architecture Search
Apr 27, 2022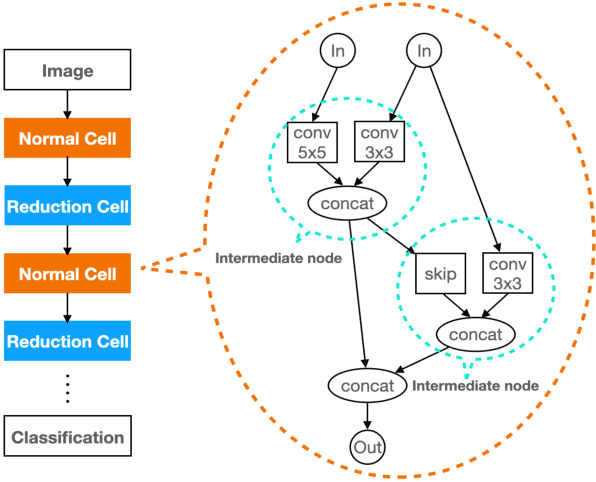
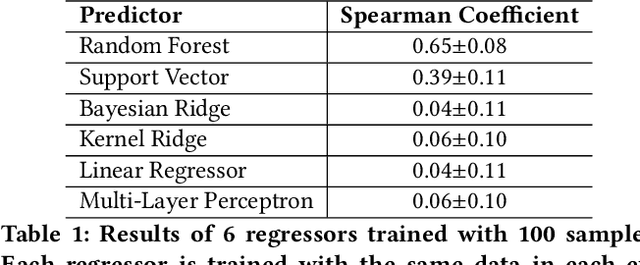
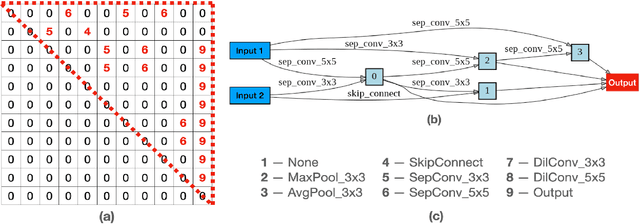
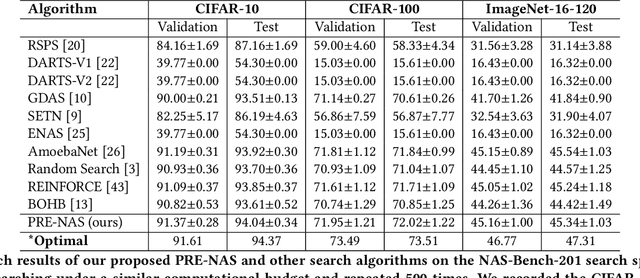
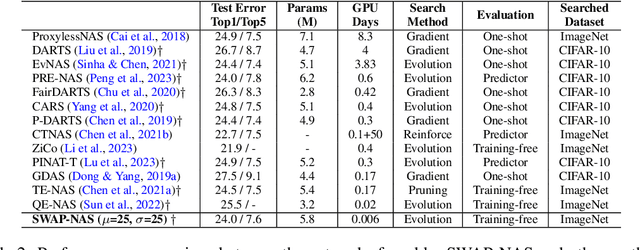
Neural architecture search (NAS) aims to automate architecture engineering in neural networks. This often requires a high computational overhead to evaluate a number of candidate networks from the set of all possible networks in the search space during the search. Prediction of the networks' performance can alleviate this high computational overhead by mitigating the need for evaluating every candidate network. Developing such a predictor typically requires a large number of evaluated architectures which may be difficult to obtain. We address this challenge by proposing a novel evolutionary-based NAS strategy, Predictor-assisted E-NAS (PRE-NAS), which can perform well even with an extremely small number of evaluated architectures. PRE-NAS leverages new evolutionary search strategies and integrates high-fidelity weight inheritance over generations. Unlike one-shot strategies, which may suffer from bias in the evaluation due to weight sharing, offspring candidates in PRE-NAS are topologically homogeneous, which circumvents bias and leads to more accurate predictions. Extensive experiments on NAS-Bench-201 and DARTS search spaces show that PRE-NAS can outperform state-of-the-art NAS methods. With only a single GPU searching for 0.6 days, competitive architecture can be found by PRE-NAS which achieves 2.40% and 24% test error rates on CIFAR-10 and ImageNet respectively.
MoParkeR : Multi-objective Parking Recommendation
Jun 10, 2021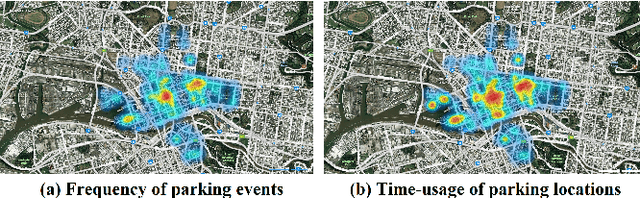
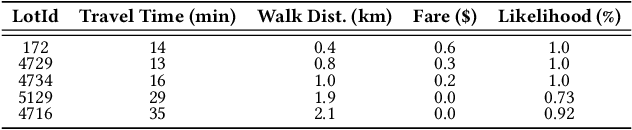

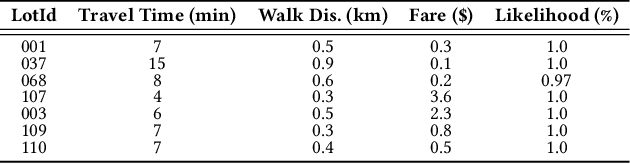
Existing parking recommendation solutions mainly focus on finding and suggesting parking spaces based on the unoccupied options only. However, there are other factors associated with parking spaces that can influence someone's choice of parking such as fare, parking rule, walking distance to destination, travel time, likelihood to be unoccupied at a given time. More importantly, these factors may change over time and conflict with each other which makes the recommendations produced by current parking recommender systems ineffective. In this paper, we propose a novel problem called multi-objective parking recommendation. We present a solution by designing a multi-objective parking recommendation engine called MoParkeR that considers various conflicting factors together. Specifically, we utilise a non-dominated sorting technique to calculate a set of Pareto-optimal solutions, consisting of recommended trade-off parking spots. We conduct extensive experiments using two real-world datasets to show the applicability of our multi-objective recommendation methodology.
FADACS: A Few-shot Adversarial Domain Adaptation Architecture for Context-Aware Parking Availability Sensing
Jul 13, 2020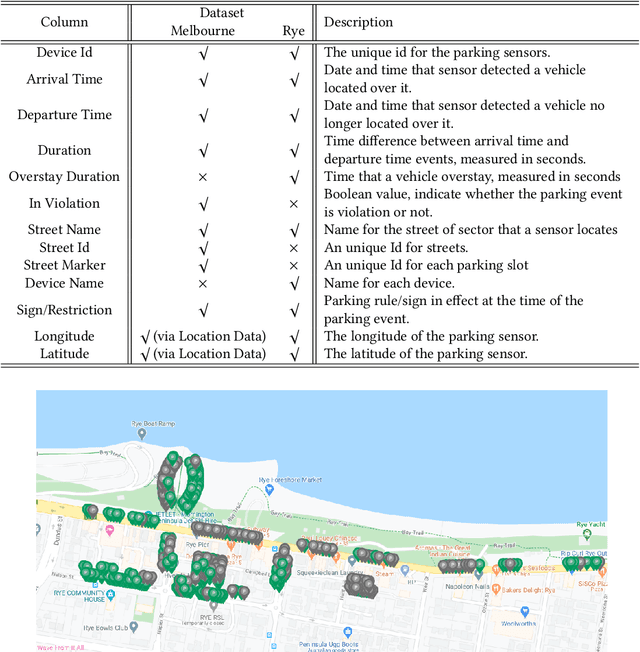
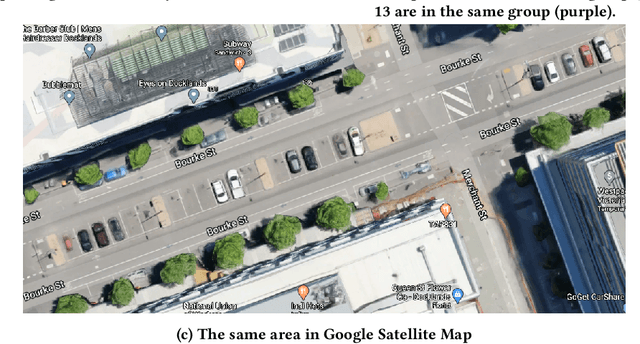

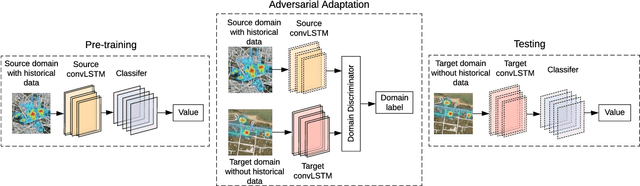
The existing research on parking availability sensing mainly relies on extensive contextual and historical information. In practice, it is challenging to have such information available as it requires continuous collection of sensory signals. In this paper, we design an end-to-end transfer learning framework for parking availability sensing to predict the parking occupancy in areas where the parking data is insufficient to feed into data-hungry models. This framework overcomes two main challenges: 1) many real-world cases cannot provide enough data for most existing data-driven models. 2) it is difficult to merge sensor data and heterogeneous contextual information due to the differing urban fabric and spatial characteristics. Our work adopts a widely-used concept called adversarial domain adaptation to predict the parking occupancy in an area without abundant sensor data by leveraging data from other areas with similar features. In this paper, we utilise more than 35 million parking data records from sensors placed in two different cities, one is a city centre, and another one is a coastal tourist town. We also utilise heterogeneous spatio-temporal contextual information from external resources including weather and point of interests. We quantify the strength of our proposed framework in different cases and compare it to the existing data-driven approaches. The results show that the proposed framework outperforms existing methods and also provide a few valuable insights for parking availability prediction.
Adaptive Re-ranking of Deep Feature for Person Re-identification
Nov 21, 2018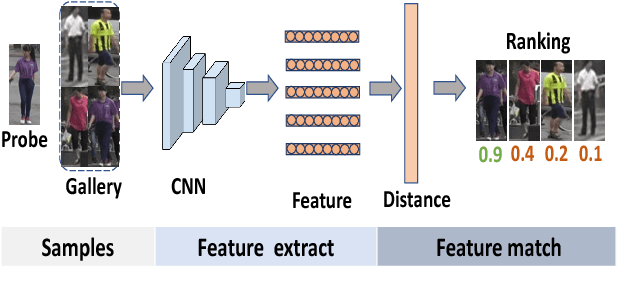
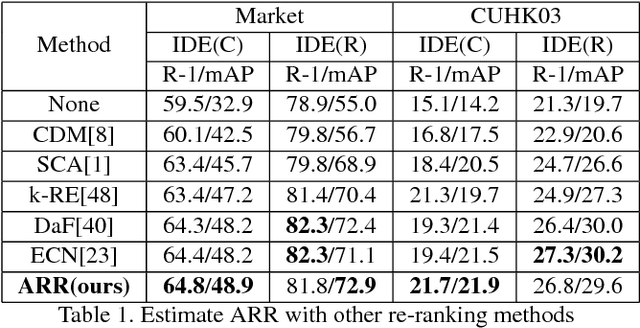
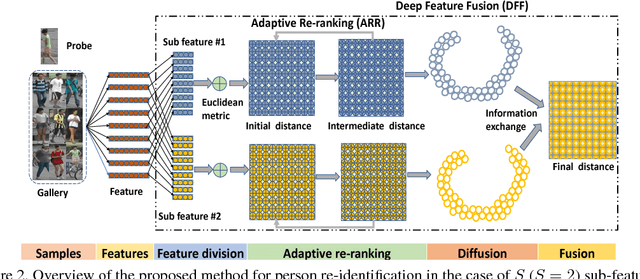
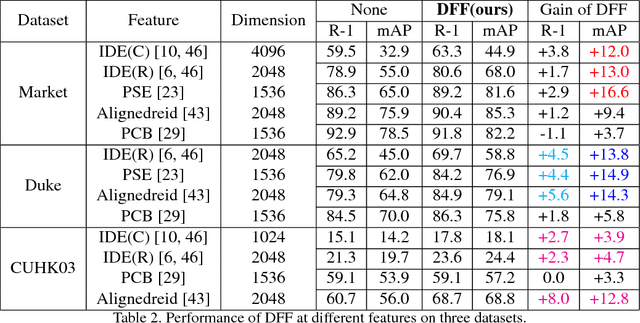
Typical person re-identification (re-ID) methods train a deep CNN to extract deep features and combine them with a distance metric for the final evaluation. In this work, we focus on exploiting the full information encoded in the deep feature to boost the re-ID performance. First, we propose a Deep Feature Fusion (DFF) method to exploit the diverse information embedded in a deep feature. DFF treats each sub-feature as an information carrier and employs a diffusion process to exchange their information. Second, we propose an Adaptive Re-Ranking (ARR) method to exploit the contextual information encoded in the features of neighbors. ARR utilizes the contextual information to re-rank the retrieval results in an iterative manner. Particularly, it adds more contextual information after each iteration automatically to consider more matches. Third, we propose a strategy that combines DFF and ARR to enhance the performance. Extensive comparative evaluations demonstrate the superiority of the proposed methods on three large benchmarks.
Background Subtraction using Compressed Low-resolution Images
Oct 24, 2018

Image processing and recognition are an important part of the modern society, with applications in fields such as advanced artificial intelligence, smart assistants, and security surveillance. The essential first step involved in almost all the visual tasks is background subtraction with a static camera. Ensuring that this critical step is performed in the most efficient manner would therefore improve all aspects related to objects recognition and tracking, behavior comprehension, etc.. Although background subtraction method has been applied for many years, its application suffers from real-time requirement. In this letter, we present a novel approach in implementing the background subtraction. The proposed method uses compressed, low-resolution grayscale image for the background subtraction. These low-resolution grayscale images were found to preserve the salient information very well. To verify the feasibility of our methodology, two prevalent methods, ViBe and GMM, are used in the experiment. The results of the proposed methodology confirm the effectiveness of our approach.