 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUser-Aware Conditional Generative Total Correlation Learning for Multi-Modal Recommendation
Apr 03, 2026Multi-modal recommendation (MMR) enriches item representations by introducing item content, e.g., visual and textual descriptions, to improve upon interaction-only recommenders. The success of MMR hinges on aligning these content modalities with user preferences derived from interaction data, yet dominant practices based on disentangling modality-invariant preference-driving signals from modality-specific preference-irrelevant noises are flawed. First, they assume a one-size-fits-all relevance of item content to user preferences for all users, which contradicts the user-conditional fact of preferences. Second, they optimize pairwise contrastive losses separately toward cross-modal alignment, systematically ignoring higher-order dependencies inherent when multiple content modalities jointly influence user choices. In this paper, we introduce GTC, a conditional Generative Total Correlation learning framework. We employ an interaction-guided diffusion model to perform user-aware content feature filtering, preserving only personalized features relevant to each individual user. Furthermore, to capture complete cross-modal dependencies, we optimize a tractable lower bound of the total correlation of item representations across all modalities. Experiments on standard MMR benchmarks show GTC consistently outperforms state-of-the-art, with gains of up to 28.30% in NDCG@5. Ablation studies validate both conditional preference-driven feature filtering and total correlation optimization, confirming the ability of GTC to model user-conditional relationships in MMR tasks. The code is available at: https://github.com/jingdu-cs/GTC.
Combating Data Laundering in LLM Training
Apr 02, 2026Data rights owners can detect unauthorized data use in large language model (LLM) training by querying with proprietary samples. Often, superior performance (e.g., higher confidence or lower loss) on a sample relative to the untrained data implies it was part of the training corpus, as LLMs tend to perform better on data they have seen during training. However, this detection becomes fragile under data laundering, a practice of transforming the stylistic form of proprietary data, while preserving critical information to obfuscate data provenance. When an LLM is trained exclusively on such laundered variants, it no longer performs better on originals, erasing the signals that standard detections rely on. We counter this by inferring the unknown laundering transformation from black-box access to the target LLM and, via an auxiliary LLM, synthesizing queries that mimic the laundered data, even if rights owners have only the originals. As the search space of finding true laundering transformations is infinite, we abstract such a process into a high-level transformation goal (e.g., "lyrical rewriting") and concrete details (e.g., "with vivid imagery"), and introduce synthesis data reversion (SDR) that instantiates this abstraction. SDR first identifies the most probable goal for synthesis to narrow the search; it then iteratively refines details so that synthesized queries gradually elicit stronger detection signals from the target LLM. Evaluated on the MIMIR benchmark against diverse laundering practices and target LLM families (Pythia, Llama2, and Falcon), SDR consistently strengthens data misuse detection, providing a practical countermeasure to data laundering.
Visual-Guided Key-Token Regularization for Multimodal Large Language Model Unlearning
Jan 29, 2026Unlearning in Multimodal Large Language Models (MLLMs) prevents the model from revealing private information when queried about target images. Existing MLLM unlearning methods largely adopt approaches developed for LLMs. They treat all answer tokens uniformly, disregarding their varying importance in the unlearning process. Moreover, these methods focus exclusively on the language modality, disregarding visual cues that indicate key tokens in answers. In this paper, after formulating the problem of unlearning in multimodal question answering for MLLMs, we propose Visual-Guided Key-Token Regularization (ViKeR). We leverage irrelevant visual inputs to predict ideal post-unlearning token-level distributions and use these distributions to regularize the unlearning process, thereby prioritizing key tokens. Further, we define key tokens in unlearning via information entropy and discuss ViKeR's effectiveness through token-level gradient reweighting, which amplifies updates on key tokens. Experiments on MLLMU and CLEAR benchmarks demonstrate that our method effectively performs unlearning while mitigating forgetting and maintaining response coherence.
Per-parameter Task Arithmetic for Unlearning in Large Language Models
Jan 29, 2026In large language model (LLM) unlearning, private information is required to be removed. Task arithmetic unlearns by subtracting a specific task vector (TV)--defined as the parameter difference between a privacy-information-tuned model and the original model. While efficient, it can cause over-forgetting by disrupting parameters essential for retaining other information. Motivated by the observation that each parameter exhibits different importance for forgetting versus retention, we propose a per-parameter task arithmetic (PerTA) mechanism to rescale the TV, allowing per-parameter adjustment. These weights quantify the relative importance of each parameter for forgetting versus retention, estimated via gradients (i.e., PerTA-grad) or the diagonal Fisher information approximation (i.e., PerTA-fisher). Moreover, we discuss the effectiveness of PerTA, extend it to a more general form, and provide further analysis. Extensive experiments demonstrate that PerTA consistently improves upon standard TV, and in many cases surpasses widely used training-based unlearning methods in both forgetting effectiveness and overall model utility. By retaining the efficiency of task arithmetic while mitigating over-forgetting, PerTA offers a principled and practical framework for LLM unlearning.
Let's Roll a BiFTA: Bi-refinement for Fine-grained Text-visual Alignment in Vision-Language Models
Jan 28, 2026Recent research has shown that aligning fine-grained text descriptions with localized image patches can significantly improve the zero-shot performance of pre-trained vision-language models (e.g., CLIP). However, we find that both fine-grained text descriptions and localized image patches often contain redundant information, making text-visual alignment less effective. In this paper, we tackle this issue from two perspectives: \emph{View Refinement} and \emph{Description refinement}, termed as \textit{\textbf{Bi}-refinement for \textbf{F}ine-grained \textbf{T}ext-visual \textbf{A}lignment} (BiFTA). \emph{View refinement} removes redundant image patches with high \emph{Intersection over Union} (IoU) ratios, resulting in more distinctive visual samples. \emph{Description refinement} removes redundant text descriptions with high pairwise cosine similarity, ensuring greater diversity in the remaining descriptions. BiFTA achieves superior zero-shot performance on 6 benchmark datasets for both ViT-based and ResNet-based CLIP, justifying the necessity to remove redundant information in visual-text alignment.
Sample-Specific Noise Injection For Diffusion-Based Adversarial Purification
Jun 06, 2025Diffusion-based purification (DBP) methods aim to remove adversarial noise from the input sample by first injecting Gaussian noise through a forward diffusion process, and then recovering the clean example through a reverse generative process. In the above process, how much Gaussian noise is injected to the input sample is key to the success of DBP methods, which is controlled by a constant noise level $t^*$ for all samples in existing methods. In this paper, we discover that an optimal $t^*$ for each sample indeed could be different. Intuitively, the cleaner a sample is, the less the noise it should be injected, and vice versa. Motivated by this finding, we propose a new framework, called Sample-specific Score-aware Noise Injection (SSNI). Specifically, SSNI uses a pre-trained score network to estimate how much a data point deviates from the clean data distribution (i.e., score norms). Then, based on the magnitude of score norms, SSNI applies a reweighting function to adaptively adjust $t^*$ for each sample, achieving sample-specific noise injections. Empirically, incorporating our framework with existing DBP methods results in a notable improvement in both accuracy and robustness on CIFAR-10 and ImageNet-1K, highlighting the necessity to allocate distinct noise levels to different samples in DBP methods. Our code is available at: https://github.com/tmlr-group/SSNI.
Neural Network Reprogrammability: A Unified Theme on Model Reprogramming, Prompt Tuning, and Prompt Instruction
Jun 05, 2025As large-scale pre-trained foundation models continue to expand in size and capability, efficiently adapting them to specific downstream tasks has become increasingly critical. Despite substantial progress, existing adaptation approaches have evolved largely in isolation, without a clear understanding of their interrelationships. This survey introduces neural network reprogrammability as a unifying framework that bridges mainstream model adaptation techniques--model reprogramming, prompt tuning, and prompt instruction--previously fragmented research areas yet converges on a shared principle: repurposing a pre-trained model by manipulating information at the interfaces while keeping the model parameters frozen. These methods exploit neural networks' sensitivity to manipulation on different interfaces, be it through perturbing inputs, inserting tokens into intermediate layers, or providing task-specific examples in context, to redirect model behaviors towards desired outcomes. We then present a taxonomy that categorizes such information manipulation-based adaptation approaches across four key dimensions: manipulation format (fixed or learnable), location (interfaces where manipulations occur), operator (how they are applied), and output alignment requirement (post-processing needed to align outputs with downstream tasks). Notably, this framework applies consistently across data modalities, independent of specific model architectures. Moreover, viewing established techniques like in-context learning and chain-of-thought prompting through this lens reveals both their theoretical connections and practical distinctions. We further analyze remaining technical challenges and ethical considerations, positioning neural network reprogrammability as a fundamental paradigm for efficient model adaptation. We lastly identify promising research directions emerging from this integrative viewpoint.
Membership Inference Attack Should Move On to Distributional Statistics for Distilled Generative Models
Feb 05, 2025



Membership inference attacks (MIAs) determine whether certain data instances were used to train a model by exploiting the differences in how the model responds to seen versus unseen instances. This capability makes MIAs important in assessing privacy leakage within modern generative AI systems. However, this paper reveals an oversight in existing MIAs against \emph{distilled generative models}: attackers can no longer detect a teacher model's training instances individually when targeting the distilled student model, as the student learns from the teacher-generated data rather than its original member data, preventing direct instance-level memorization. Nevertheless, we find that student-generated samples exhibit a significantly stronger distributional alignment with teacher's member data than non-member data. This leads us to posit that MIAs \emph{on distilled generative models should shift from instance-level to distribution-level statistics}. We thereby introduce a \emph{set-based} MIA framework that measures \emph{relative} distributional discrepancies between student-generated data\emph{sets} and potential member/non-member data\emph{sets}, Empirically, distributional statistics reliably distinguish a teacher's member data from non-member data through the distilled model. Finally, we discuss scenarios in which our setup faces limitations.
Towards Robust Cross-Domain Recommendation with Joint Identifiability of User Preference
Nov 26, 2024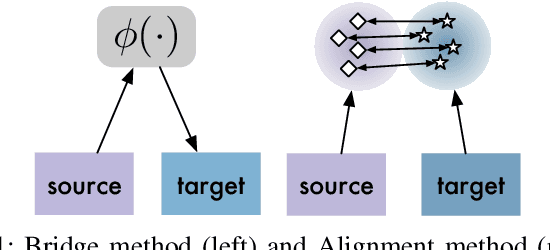
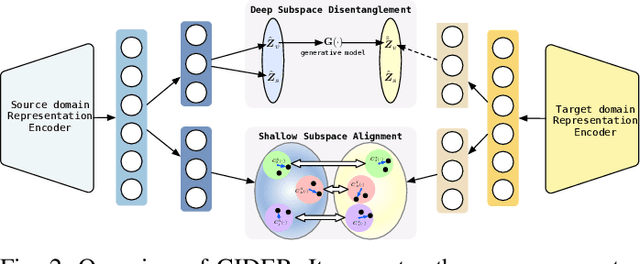
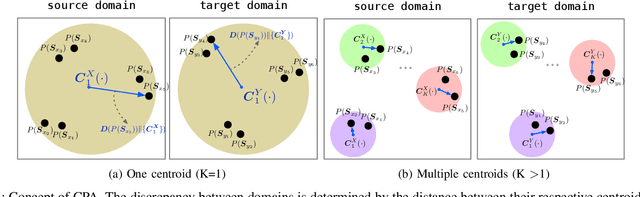
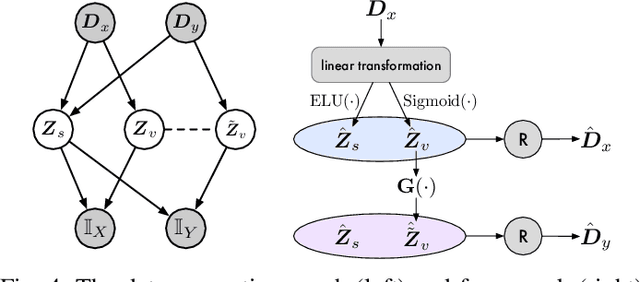
Recent cross-domain recommendation (CDR) studies assume that disentangled domain-shared and domain-specific user representations can mitigate domain gaps and facilitate effective knowledge transfer. However, achieving perfect disentanglement is challenging in practice, because user behaviors in CDR are highly complex, and the true underlying user preferences cannot be fully captured through observed user-item interactions alone. Given this impracticability, we instead propose to model {\it joint identifiability} that establishes unique correspondence of user representations across domains, ensuring consistent preference modeling even when user behaviors exhibit shifts in different domains. To achieve this, we introduce a hierarchical user preference modeling framework that organizes user representations by the neural network encoder's depth, allowing separate treatment of shallow and deeper subspaces. In the shallow subspace, our framework models the interest centroids for each user within each domain, probabilistically determining the users' interest belongings and selectively aligning these centroids across domains to ensure fine-grained consistency in domain-irrelevant features. For deeper subspace representations, we enforce joint identifiability by decomposing it into a shared cross-domain stable component and domain-variant components, linked by a bijective transformation for unique correspondence. Empirical studies on real-world CDR tasks with varying domain correlations demonstrate that our method consistently surpasses state-of-the-art, even with weakly correlated tasks, highlighting the importance of joint identifiability in achieving robust CDR.
Bayesian-guided Label Mapping for Visual Reprogramming
Oct 31, 2024



Visual reprogramming (VR) leverages the intrinsic capabilities of pretrained vision models by adapting their input or output interfaces to solve downstream tasks whose labels (i.e., downstream labels) might be totally different from the labels associated with the pretrained models (i.e., pretrained labels). When adapting the output interface, label mapping methods transform the pretrained labels to downstream labels by establishing a gradient-free one-to-one correspondence between the two sets of labels. However, in this paper, we reveal that one-to-one mappings may overlook the complex relationship between pretrained and downstream labels. Motivated by this observation, we propose a Bayesian-guided Label Mapping (BLM) method. BLM constructs an iteratively-updated probabilistic label mapping matrix, with each element quantifying a pairwise relationship between pretrained and downstream labels. The assignment of values to the constructed matrix is guided by Bayesian conditional probability, considering the joint distribution of the downstream labels and the labels predicted by the pretrained model on downstream samples. Experiments conducted on both pretrained vision models (e.g., ResNeXt) and vision-language models (e.g., CLIP) demonstrate the superior performance of BLM over existing label mapping methods. The success of BLM also offers a probabilistic lens through which to understand and analyze the effectiveness of VR. Our code is available at https://github.com/tmlr-group/BayesianLM.