 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual-Guided Key-Token Regularization for Multimodal Large Language Model Unlearning
Jan 29, 2026Unlearning in Multimodal Large Language Models (MLLMs) prevents the model from revealing private information when queried about target images. Existing MLLM unlearning methods largely adopt approaches developed for LLMs. They treat all answer tokens uniformly, disregarding their varying importance in the unlearning process. Moreover, these methods focus exclusively on the language modality, disregarding visual cues that indicate key tokens in answers. In this paper, after formulating the problem of unlearning in multimodal question answering for MLLMs, we propose Visual-Guided Key-Token Regularization (ViKeR). We leverage irrelevant visual inputs to predict ideal post-unlearning token-level distributions and use these distributions to regularize the unlearning process, thereby prioritizing key tokens. Further, we define key tokens in unlearning via information entropy and discuss ViKeR's effectiveness through token-level gradient reweighting, which amplifies updates on key tokens. Experiments on MLLMU and CLEAR benchmarks demonstrate that our method effectively performs unlearning while mitigating forgetting and maintaining response coherence.
Per-parameter Task Arithmetic for Unlearning in Large Language Models
Jan 29, 2026In large language model (LLM) unlearning, private information is required to be removed. Task arithmetic unlearns by subtracting a specific task vector (TV)--defined as the parameter difference between a privacy-information-tuned model and the original model. While efficient, it can cause over-forgetting by disrupting parameters essential for retaining other information. Motivated by the observation that each parameter exhibits different importance for forgetting versus retention, we propose a per-parameter task arithmetic (PerTA) mechanism to rescale the TV, allowing per-parameter adjustment. These weights quantify the relative importance of each parameter for forgetting versus retention, estimated via gradients (i.e., PerTA-grad) or the diagonal Fisher information approximation (i.e., PerTA-fisher). Moreover, we discuss the effectiveness of PerTA, extend it to a more general form, and provide further analysis. Extensive experiments demonstrate that PerTA consistently improves upon standard TV, and in many cases surpasses widely used training-based unlearning methods in both forgetting effectiveness and overall model utility. By retaining the efficiency of task arithmetic while mitigating over-forgetting, PerTA offers a principled and practical framework for LLM unlearning.
Beyond Linearization: Attributed Table Graphs for Table Reasoning
Jan 13, 2026Table reasoning, a task to answer questions by reasoning over data presented in tables, is an important topic due to the prevalence of knowledge stored in tabular formats. Recent solutions use Large Language Models (LLMs), exploiting the semantic understanding and reasoning capabilities of LLMs. A common paradigm of such solutions linearizes tables to form plain texts that are served as input to LLMs. This paradigm has critical issues. It loses table structures, lacks explicit reasoning paths for result explainability, and is subject to the "lost-in-the-middle" issue. To address these issues, we propose Table Graph Reasoner (TABGR), a training-free model that represents tables as an Attributed Table Graph (ATG). The ATG explicitly preserves row-column-cell structures while enabling graph-based reasoning for explainability. We further propose a Question-Guided Personalized PageRank (QG-PPR) mechanism to rerank tabular data and mitigate the lost-in-the-middle issue. Extensive experiments on two commonly used benchmarks show that TABGR consistently outperforms state-of-the-art models by up to 9.7% in accuracy. Our code will be made publicly available upon publication.
Understanding the Geospatial Reasoning Capabilities of LLMs: A Trajectory Recovery Perspective
Oct 02, 2025We explore the geospatial reasoning capabilities of Large Language Models (LLMs), specifically, whether LLMs can read road network maps and perform navigation. We frame trajectory recovery as a proxy task, which requires models to reconstruct masked GPS traces, and introduce GLOBALTRACE, a dataset with over 4,000 real-world trajectories across diverse regions and transportation modes. Using road network as context, our prompting framework enables LLMs to generate valid paths without accessing any external navigation tools. Experiments show that LLMs outperform off-the-shelf baselines and specialized trajectory recovery models, with strong zero-shot generalization. Fine-grained analysis shows that LLMs have strong comprehension of the road network and coordinate systems, but also pose systematic biases with respect to regions and transportation modes. Finally, we demonstrate how LLMs can enhance navigation experiences by reasoning over maps in flexible ways to incorporate user preferences.
Generalising Traffic Forecasting to Regions without Traffic Observations
Aug 12, 2025Traffic forecasting is essential for intelligent transportation systems. Accurate forecasting relies on continuous observations collected by traffic sensors. However, due to high deployment and maintenance costs, not all regions are equipped with such sensors. This paper aims to forecast for regions without traffic sensors, where the lack of historical traffic observations challenges the generalisability of existing models. We propose a model named GenCast, the core idea of which is to exploit external knowledge to compensate for the missing observations and to enhance generalisation. We integrate physics-informed neural networks into GenCast, enabling physical principles to regularise the learning process. We introduce an external signal learning module to explore correlations between traffic states and external signals such as weather conditions, further improving model generalisability. Additionally, we design a spatial grouping module to filter localised features that hinder model generalisability. Extensive experiments show that GenCast consistently reduces forecasting errors on multiple real-world datasets.
Neural Network Reprogrammability: A Unified Theme on Model Reprogramming, Prompt Tuning, and Prompt Instruction
Jun 05, 2025As large-scale pre-trained foundation models continue to expand in size and capability, efficiently adapting them to specific downstream tasks has become increasingly critical. Despite substantial progress, existing adaptation approaches have evolved largely in isolation, without a clear understanding of their interrelationships. This survey introduces neural network reprogrammability as a unifying framework that bridges mainstream model adaptation techniques--model reprogramming, prompt tuning, and prompt instruction--previously fragmented research areas yet converges on a shared principle: repurposing a pre-trained model by manipulating information at the interfaces while keeping the model parameters frozen. These methods exploit neural networks' sensitivity to manipulation on different interfaces, be it through perturbing inputs, inserting tokens into intermediate layers, or providing task-specific examples in context, to redirect model behaviors towards desired outcomes. We then present a taxonomy that categorizes such information manipulation-based adaptation approaches across four key dimensions: manipulation format (fixed or learnable), location (interfaces where manipulations occur), operator (how they are applied), and output alignment requirement (post-processing needed to align outputs with downstream tasks). Notably, this framework applies consistently across data modalities, independent of specific model architectures. Moreover, viewing established techniques like in-context learning and chain-of-thought prompting through this lens reveals both their theoretical connections and practical distinctions. We further analyze remaining technical challenges and ethical considerations, positioning neural network reprogrammability as a fundamental paradigm for efficient model adaptation. We lastly identify promising research directions emerging from this integrative viewpoint.
ACE: A Cardinality Estimator for Set-Valued Queries
Mar 19, 2025Cardinality estimation is a fundamental functionality in database systems. Most existing cardinality estimators focus on handling predicates over numeric or categorical data. They have largely omitted an important data type, set-valued data, which frequently occur in contemporary applications such as information retrieval and recommender systems. The few existing estimators for such data either favor high-frequency elements or rely on a partial independence assumption, which limits their practical applicability. We propose ACE, an Attention-based Cardinality Estimator for estimating the cardinality of queries over set-valued data. We first design a distillation-based data encoder to condense the dataset into a compact matrix. We then design an attention-based query analyzer to capture correlations among query elements. To handle variable-sized queries, a pooling module is introduced, followed by a regression model (MLP) to generate final cardinality estimates. We evaluate ACE on three datasets with varying query element distributions, demonstrating that ACE outperforms the state-of-the-art competitors in terms of both accuracy and efficiency.
Urban Region Representation Learning: A Flexible Approach
Mar 12, 2025



The increasing availability of urban data offers new opportunities for learning region representations, which can be used as input to machine learning models for downstream tasks such as check-in or crime prediction. While existing solutions have produced promising results, an issue is their fixed formation of regions and fixed input region features, which may not suit the needs of different downstream tasks. To address this limitation, we propose a model named FlexiReg for urban region representation learning that is flexible with both the formation of urban regions and the input region features. FlexiReg is based on a spatial grid partitioning over the spatial area of interest. It learns representations for the grid cells, leveraging publicly accessible data, including POI, land use, satellite imagery, and street view imagery. We propose adaptive aggregation to fuse the cell representations and prompt learning techniques to tailor the representations towards different tasks, addressing the needs of varying formations of urban regions and downstream tasks. Extensive experiments on five real-world datasets demonstrate that FlexiReg outperforms state-of-the-art models by up to 202% in term of the accuracy of four diverse downstream tasks using the produced urban region representations.
CtrTab: Tabular Data Synthesis with High-Dimensional and Limited Data
Mar 09, 2025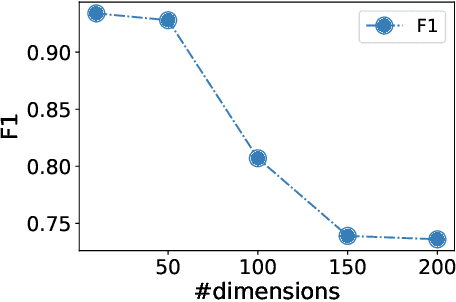
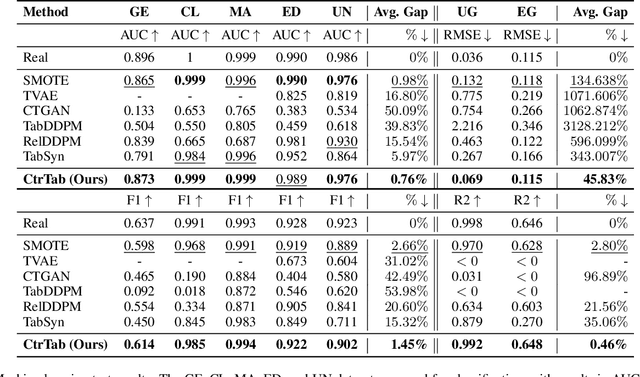
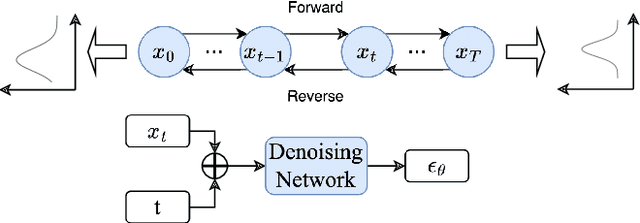
Diffusion-based tabular data synthesis models have yielded promising results. However, we observe that when the data dimensionality increases, existing models tend to degenerate and may perform even worse than simpler, non-diffusion-based models. This is because limited training samples in high-dimensional space often hinder generative models from capturing the distribution accurately. To address this issue, we propose CtrTab-a condition controlled diffusion model for tabular data synthesis-to improve the performance of diffusion-based generative models in high-dimensional, low-data scenarios. Through CtrTab, we inject samples with added Laplace noise as control signals to improve data diversity and show its resemblance to L2 regularization, which enhances model robustness. Experimental results across multiple datasets show that CtrTab outperforms state-of-the-art models, with performance gap in accuracy over 80% on average. Our source code will be released upon paper publication.
Unseen Fake News Detection Through Casual Debiasing
Mar 06, 2025The widespread dissemination of fake news on social media poses significant risks, necessitating timely and accurate detection. However, existing methods struggle with unseen news due to their reliance on training data from past events and domains, leaving the challenge of detecting novel fake news largely unresolved. To address this, we identify biases in training data tied to specific domains and propose a debiasing solution FNDCD. Originating from causal analysis, FNDCD employs a reweighting strategy based on classification confidence and propagation structure regularization to reduce the influence of domain-specific biases, enhancing the detection of unseen fake news. Experiments on real-world datasets with non-overlapping news domains demonstrate FNDCD's effectiveness in improving generalization across domains.