 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoA: Towards Real Image Dehazing via Compression-and-Adaptation
Apr 08, 2025Learning-based image dehazing algorithms have shown remarkable success in synthetic domains. However, real image dehazing is still in suspense due to computational resource constraints and the diversity of real-world scenes. Therefore, there is an urgent need for an algorithm that excels in both efficiency and adaptability to address real image dehazing effectively. This work proposes a Compression-and-Adaptation (CoA) computational flow to tackle these challenges from a divide-and-conquer perspective. First, model compression is performed in the synthetic domain to develop a compact dehazing parameter space, satisfying efficiency demands. Then, a bilevel adaptation in the real domain is introduced to be fearless in unknown real environments by aggregating the synthetic dehazing capabilities during the learning process. Leveraging a succinct design free from additional constraints, our CoA exhibits domain-irrelevant stability and model-agnostic flexibility, effectively bridging the model chasm between synthetic and real domains to further improve its practical utility. Extensive evaluations and analyses underscore the approach's superiority and effectiveness. The code is publicly available at https://github.com/fyxnl/COA.
Towards Multimodal Metaphor Understanding: A Chinese Dataset and Model for Metaphor Mapping Identification
Jan 05, 2025



Metaphors play a crucial role in human communication, yet their comprehension remains a significant challenge for natural language processing (NLP) due to the cognitive complexity involved. According to Conceptual Metaphor Theory (CMT), metaphors map a target domain onto a source domain, and understanding this mapping is essential for grasping the nature of metaphors. While existing NLP research has focused on tasks like metaphor detection and sentiment analysis of metaphorical expressions, there has been limited attention to the intricate process of identifying the mappings between source and target domains. Moreover, non-English multimodal metaphor resources remain largely neglected in the literature, hindering a deeper understanding of the key elements involved in metaphor interpretation. To address this gap, we developed a Chinese multimodal metaphor advertisement dataset (namely CM3D) that includes annotations of specific target and source domains. This dataset aims to foster further research into metaphor comprehension, particularly in non-English languages. Furthermore, we propose a Chain-of-Thought (CoT) Prompting-based Metaphor Mapping Identification Model (CPMMIM), which simulates the human cognitive process for identifying these mappings. Drawing inspiration from CoT reasoning and Bi-Level Optimization (BLO), we treat the task as a hierarchical identification problem, enabling more accurate and interpretable metaphor mapping. Our experimental results demonstrate the effectiveness of CPMMIM, highlighting its potential for advancing metaphor comprehension in NLP. Our dataset and code are both publicly available to encourage further advancements in this field.
FairGP: A Scalable and Fair Graph Transformer Using Graph Partitioning
Dec 14, 2024Recent studies have highlighted significant fairness issues in Graph Transformer (GT) models, particularly against subgroups defined by sensitive features. Additionally, GTs are computationally intensive and memory-demanding, limiting their application to large-scale graphs. Our experiments demonstrate that graph partitioning can enhance the fairness of GT models while reducing computational complexity. To understand this improvement, we conducted a theoretical investigation into the root causes of fairness issues in GT models. We found that the sensitive features of higher-order nodes disproportionately influence lower-order nodes, resulting in sensitive feature bias. We propose Fairness-aware scalable GT based on Graph Partitioning (FairGP), which partitions the graph to minimize the negative impact of higher-order nodes. By optimizing attention mechanisms, FairGP mitigates the bias introduced by global attention, thereby enhancing fairness. Extensive empirical evaluations on six real-world datasets validate the superior performance of FairGP in achieving fairness compared to state-of-the-art methods. The codes are available at https://github.com/LuoRenqiang/FairGP.
Millimeter Wave Radar-based Human Activity Recognition for Healthcare Monitoring Robot
May 03, 2024Healthcare monitoring is crucial, especially for the daily care of elderly individuals living alone. It can detect dangerous occurrences, such as falls, and provide timely alerts to save lives. Non-invasive millimeter wave (mmWave) radar-based healthcare monitoring systems using advanced human activity recognition (HAR) models have recently gained significant attention. However, they encounter challenges in handling sparse point clouds, achieving real-time continuous classification, and coping with limited monitoring ranges when statically mounted. To overcome these limitations, we propose RobHAR, a movable robot-mounted mmWave radar system with lightweight deep neural networks for real-time monitoring of human activities. Specifically, we first propose a sparse point cloud-based global embedding to learn the features of point clouds using the light-PointNet (LPN) backbone. Then, we learn the temporal pattern with a bidirectional lightweight LSTM model (BiLiLSTM). In addition, we implement a transition optimization strategy, integrating the Hidden Markov Model (HMM) with Connectionist Temporal Classification (CTC) to improve the accuracy and robustness of the continuous HAR. Our experiments on three datasets indicate that our method significantly outperforms the previous studies in both discrete and continuous HAR tasks. Finally, we deploy our system on a movable robot-mounted edge computing platform, achieving flexible healthcare monitoring in real-world scenarios.
MorphText: Deep Morphology Regularized Arbitrary-shape Scene Text Detection
Apr 26, 2024

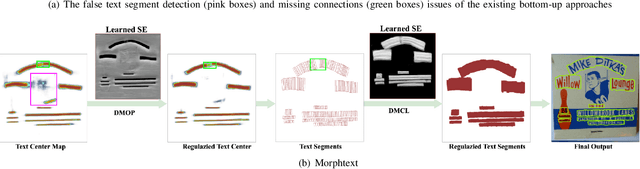
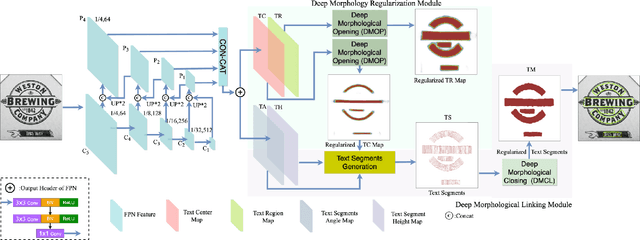
Bottom-up text detection methods play an important role in arbitrary-shape scene text detection but there are two restrictions preventing them from achieving their great potential, i.e., 1) the accumulation of false text segment detections, which affects subsequent processing, and 2) the difficulty of building reliable connections between text segments. Targeting these two problems, we propose a novel approach, named ``MorphText", to capture the regularity of texts by embedding deep morphology for arbitrary-shape text detection. Towards this end, two deep morphological modules are designed to regularize text segments and determine the linkage between them. First, a Deep Morphological Opening (DMOP) module is constructed to remove false text segment detections generated in the feature extraction process. Then, a Deep Morphological Closing (DMCL) module is proposed to allow text instances of various shapes to stretch their morphology along their most significant orientation while deriving their connections. Extensive experiments conducted on four challenging benchmark datasets (CTW1500, Total-Text, MSRA-TD500 and ICDAR2017) demonstrate that our proposed MorphText outperforms both top-down and bottom-up state-of-the-art arbitrary-shape scene text detection approaches.
Algorithmic Fairness: A Tolerance Perspective
Apr 26, 2024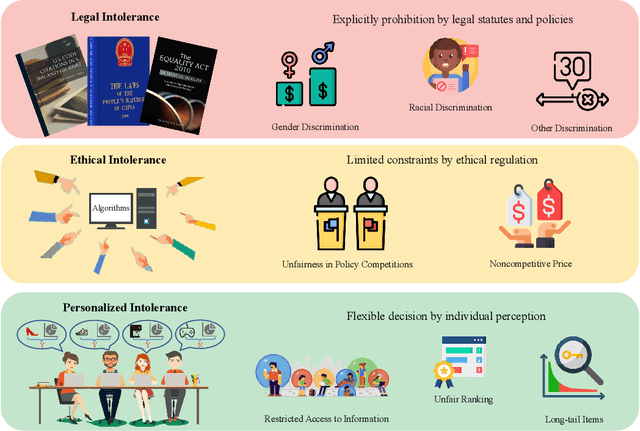

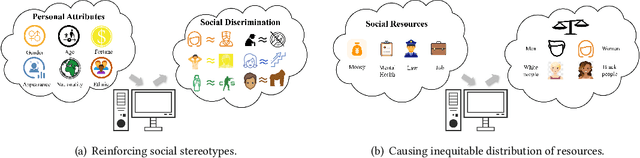

Recent advancements in machine learning and deep learning have brought algorithmic fairness into sharp focus, illuminating concerns over discriminatory decision making that negatively impacts certain individuals or groups. These concerns have manifested in legal, ethical, and societal challenges, including the erosion of trust in intelligent systems. In response, this survey delves into the existing literature on algorithmic fairness, specifically highlighting its multifaceted social consequences. We introduce a novel taxonomy based on 'tolerance', a term we define as the degree to which variations in fairness outcomes are acceptable, providing a structured approach to understanding the subtleties of fairness within algorithmic decisions. Our systematic review covers diverse industries, revealing critical insights into the balance between algorithmic decision making and social equity. By synthesizing these insights, we outline a series of emerging challenges and propose strategic directions for future research and policy making, with the goal of advancing the field towards more equitable algorithmic systems.
Seeing Text in the Dark: Algorithm and Benchmark
Apr 13, 2024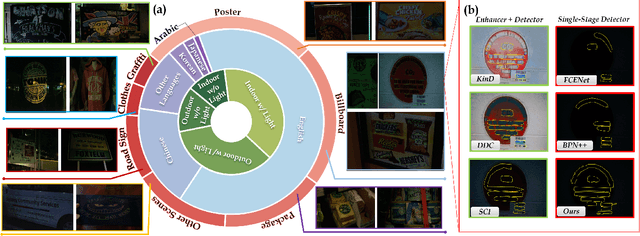

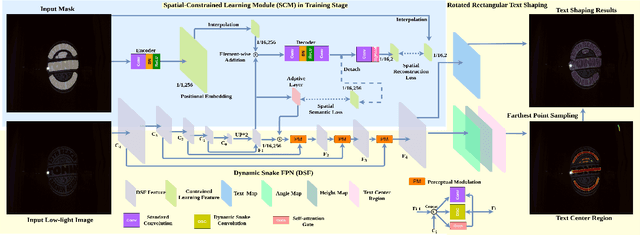

Localizing text in low-light environments is challenging due to visual degradations. Although a straightforward solution involves a two-stage pipeline with low-light image enhancement (LLE) as the initial step followed by detector, LLE is primarily designed for human vision instead of machine and can accumulate errors. In this work, we propose an efficient and effective single-stage approach for localizing text in dark that circumvents the need for LLE. We introduce a constrained learning module as an auxiliary mechanism during the training stage of the text detector. This module is designed to guide the text detector in preserving textual spatial features amidst feature map resizing, thus minimizing the loss of spatial information in texts under low-light visual degradations. Specifically, we incorporate spatial reconstruction and spatial semantic constraints within this module to ensure the text detector acquires essential positional and contextual range knowledge. Our approach enhances the original text detector's ability to identify text's local topological features using a dynamic snake feature pyramid network and adopts a bottom-up contour shaping strategy with a novel rectangular accumulation technique for accurate delineation of streamlined text features. In addition, we present a comprehensive low-light dataset for arbitrary-shaped text, encompassing diverse scenes and languages. Notably, our method achieves state-of-the-art results on this low-light dataset and exhibits comparable performance on standard normal light datasets. The code and dataset will be released.
V2VSSC: A 3D Semantic Scene Completion Benchmark for Perception with Vehicle to Vehicle Communication
Feb 07, 2024Semantic scene completion (SSC) has recently gained popularity because it can provide both semantic and geometric information that can be used directly for autonomous vehicle navigation. However, there are still challenges to overcome. SSC is often hampered by occlusion and short-range perception due to sensor limitations, which can pose safety risks. This paper proposes a fundamental solution to this problem by leveraging vehicle-to-vehicle (V2V) communication. We propose the first generalized collaborative SSC framework that allows autonomous vehicles to share sensing information from different sensor views to jointly perform SSC tasks. To validate the proposed framework, we further build V2VSSC, the first V2V SSC benchmark, on top of the large-scale V2V perception dataset OPV2V. Extensive experiments demonstrate that by leveraging V2V communication, the SSC performance can be increased by 8.3% on geometric metric IoU and 6.0% mIOU.