 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMillimeter Wave Radar-based Human Activity Recognition for Healthcare Monitoring Robot
May 03, 2024Healthcare monitoring is crucial, especially for the daily care of elderly individuals living alone. It can detect dangerous occurrences, such as falls, and provide timely alerts to save lives. Non-invasive millimeter wave (mmWave) radar-based healthcare monitoring systems using advanced human activity recognition (HAR) models have recently gained significant attention. However, they encounter challenges in handling sparse point clouds, achieving real-time continuous classification, and coping with limited monitoring ranges when statically mounted. To overcome these limitations, we propose RobHAR, a movable robot-mounted mmWave radar system with lightweight deep neural networks for real-time monitoring of human activities. Specifically, we first propose a sparse point cloud-based global embedding to learn the features of point clouds using the light-PointNet (LPN) backbone. Then, we learn the temporal pattern with a bidirectional lightweight LSTM model (BiLiLSTM). In addition, we implement a transition optimization strategy, integrating the Hidden Markov Model (HMM) with Connectionist Temporal Classification (CTC) to improve the accuracy and robustness of the continuous HAR. Our experiments on three datasets indicate that our method significantly outperforms the previous studies in both discrete and continuous HAR tasks. Finally, we deploy our system on a movable robot-mounted edge computing platform, achieving flexible healthcare monitoring in real-world scenarios.
Exploring Diverse Sounds: Identifying Outliers in a Music Corpus
Apr 09, 2024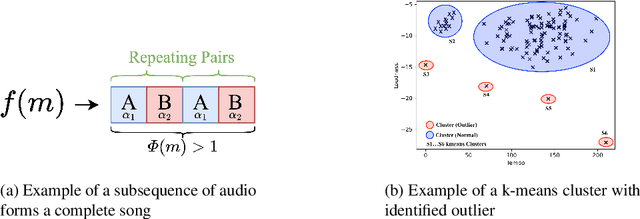
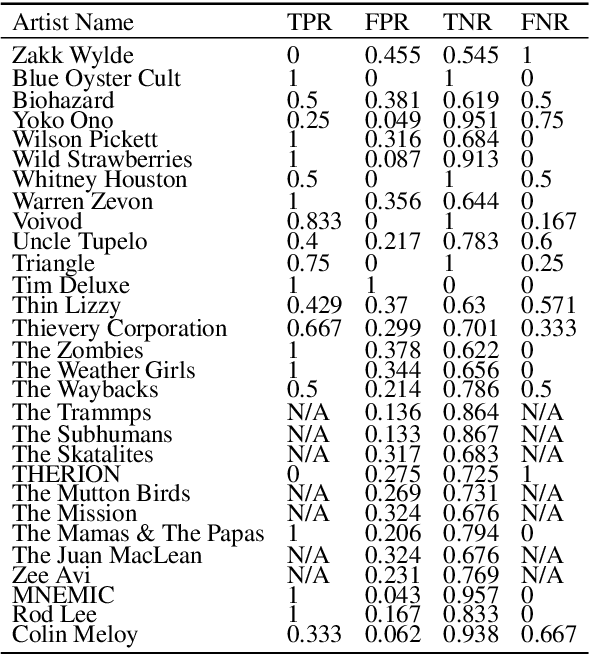
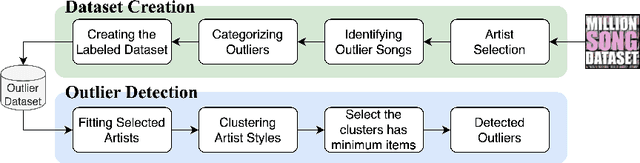
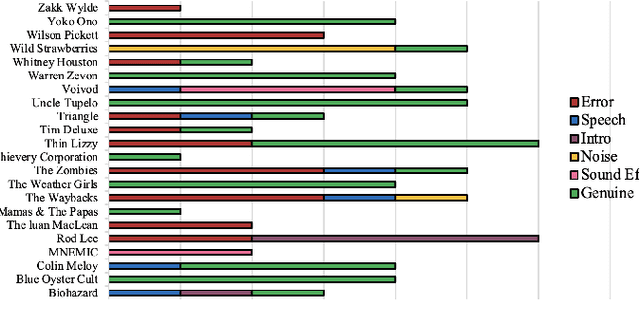
Existing research on music recommendation systems primarily focuses on recommending similar music, thereby often neglecting diverse and distinctive musical recordings. Musical outliers can provide valuable insights due to the inherent diversity of music itself. In this paper, we explore music outliers, investigating their potential usefulness for music discovery and recommendation systems. We argue that not all outliers should be treated as noise, as they can offer interesting perspectives and contribute to a richer understanding of an artist's work. We introduce the concept of 'Genuine' music outliers and provide a definition for them. These genuine outliers can reveal unique aspects of an artist's repertoire and hold the potential to enhance music discovery by exposing listeners to novel and diverse musical experiences.
DMMG: Dual Min-Max Games for Self-Supervised Skeleton-Based Action Recognition
Feb 22, 2023In this work, we propose a new Dual Min-Max Games (DMMG) based self-supervised skeleton action recognition method by augmenting unlabeled data in a contrastive learning framework. Our DMMG consists of a viewpoint variation min-max game and an edge perturbation min-max game. These two min-max games adopt an adversarial paradigm to perform data augmentation on the skeleton sequences and graph-structured body joints, respectively. Our viewpoint variation min-max game focuses on constructing various hard contrastive pairs by generating skeleton sequences from various viewpoints. These hard contrastive pairs help our model learn representative action features, thus facilitating model transfer to downstream tasks. Moreover, our edge perturbation min-max game specializes in building diverse hard contrastive samples through perturbing connectivity strength among graph-based body joints. The connectivity-strength varying contrastive pairs enable the model to capture minimal sufficient information of different actions, such as representative gestures for an action while preventing the model from overfitting. By fully exploiting the proposed DMMG, we can generate sufficient challenging contrastive pairs and thus achieve discriminative action feature representations from unlabeled skeleton data in a self-supervised manner. Extensive experiments demonstrate that our method achieves superior results under various evaluation protocols on widely-used NTU-RGB+D and NTU120-RGB+D datasets.
Feature Selection Approaches for Optimising Music Emotion Recognition Methods
Dec 27, 2022The high feature dimensionality is a challenge in music emotion recognition. There is no common consensus on a relation between audio features and emotion. The MER system uses all available features to recognize emotion; however, this is not an optimal solution since it contains irrelevant data acting as noise. In this paper, we introduce a feature selection approach to eliminate redundant features for MER. We created a Selected Feature Set (SFS) based on the feature selection algorithm (FSA) and benchmarked it by training with two models, Support Vector Regression (SVR) and Random Forest (RF) and comparing them against with using the Complete Feature Set (CFS). The result indicates that the performance of MER has improved for both Random Forest (RF) and Support Vector Regression (SVR) models by using SFS. We found using FSA can improve performance in all scenarios, and it has potential benefits for model efficiency and stability for MER task.
AFE-CNN: 3D Skeleton-based Action Recognition with Action Feature Enhancement
Aug 06, 2022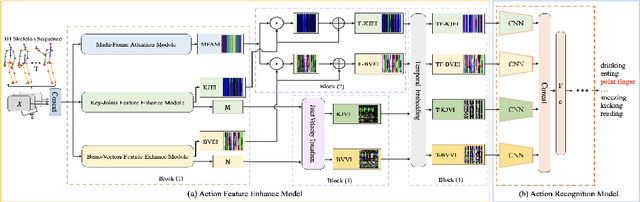
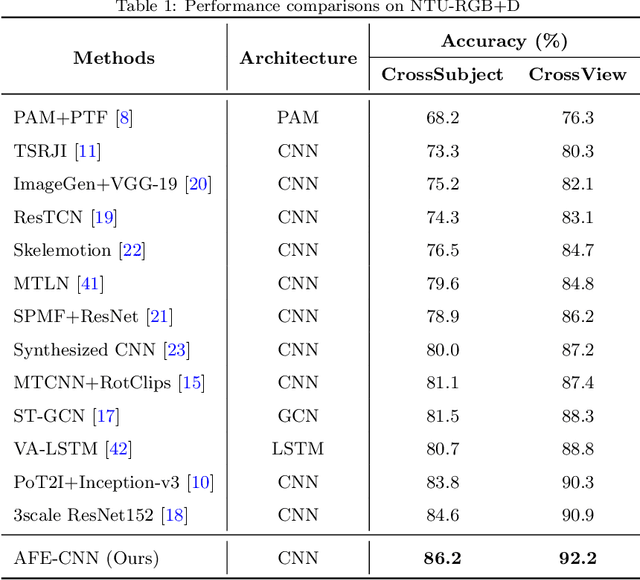
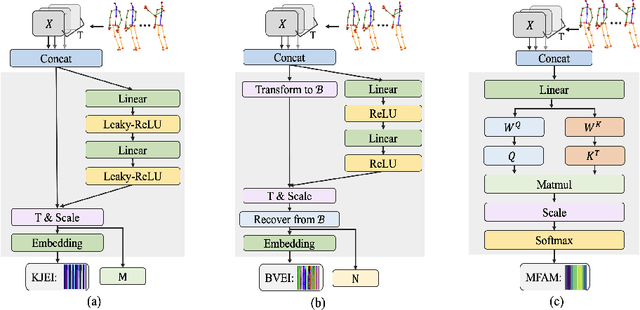
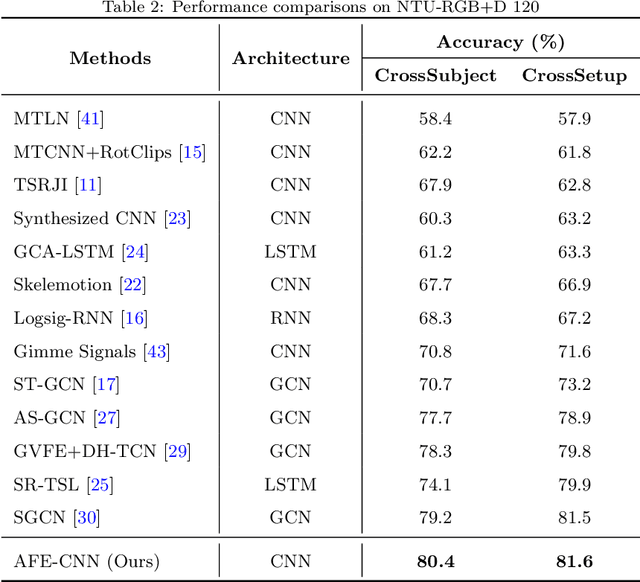
Existing 3D skeleton-based action recognition approaches reach impressive performance by encoding handcrafted action features to image format and decoding by CNNs. However, such methods are limited in two ways: a) the handcrafted action features are difficult to handle challenging actions, and b) they generally require complex CNN models to improve action recognition accuracy, which usually occur heavy computational burden. To overcome these limitations, we introduce a novel AFE-CNN, which devotes to enhance the features of 3D skeleton-based actions to adapt to challenging actions. We propose feature enhance modules from key joint, bone vector, key frame and temporal perspectives, thus the AFE-CNN is more robust to camera views and body sizes variation, and significantly improve the recognition accuracy on challenging actions. Moreover, our AFE-CNN adopts a light-weight CNN model to decode images with action feature enhanced, which ensures a much lower computational burden than the state-of-the-art methods. We evaluate the AFE-CNN on three benchmark skeleton-based action datasets: NTU RGB+D, NTU RGB+D 120, and UTKinect-Action3D, with extensive experimental results demonstrate our outstanding performance of AFE-CNN.
PoseGU: 3D Human Pose Estimation with Novel Human Pose Generator and Unbiased Learning
Jul 07, 2022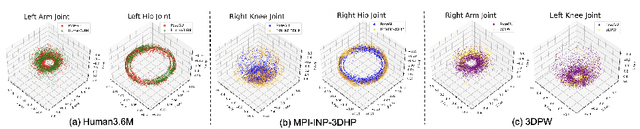
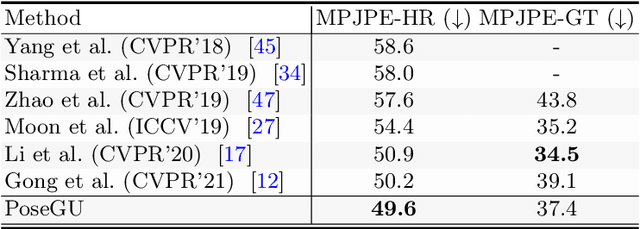

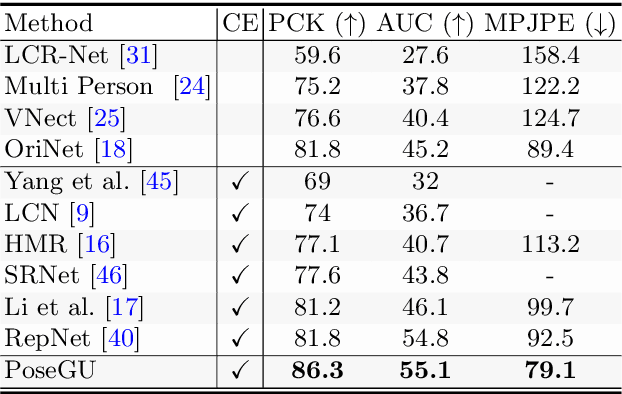
3D pose estimation has recently gained substantial interests in computer vision domain. Existing 3D pose estimation methods have a strong reliance on large size well-annotated 3D pose datasets, and they suffer poor model generalization on unseen poses due to limited diversity of 3D poses in training sets. In this work, we propose PoseGU, a novel human pose generator that generates diverse poses with access only to a small size of seed samples, while equipping the Counterfactual Risk Minimization to pursue an unbiased evaluation objective. Extensive experiments demonstrate PoseGU outforms almost all the state-of-the-art 3D human pose methods under consideration over three popular benchmark datasets. Empirical analysis also proves PoseGU generates 3D poses with improved data diversity and better generalization ability.
EdgeLoc: An Edge-IoT Framework for Robust Indoor Localization Using Capsule Networks
Sep 12, 2020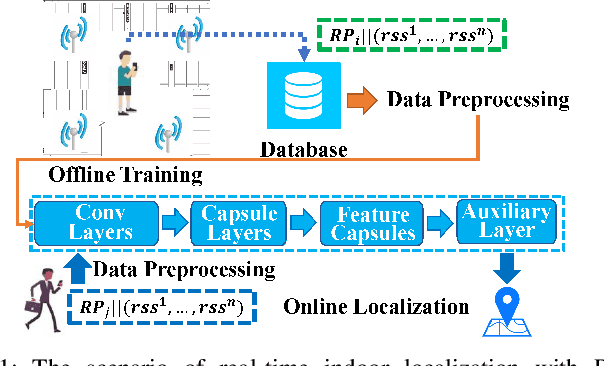
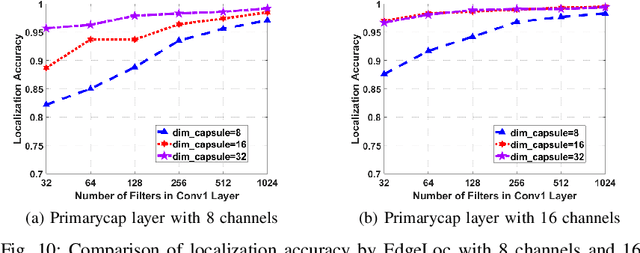
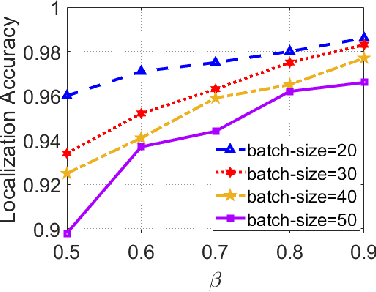

With the unprecedented demand for location-based services in indoor scenarios, wireless indoor localization has become essential for mobile users. While GPS is not available at indoor spaces, WiFi RSS fingerprinting has become popular with its ubiquitous accessibility. However, it is challenging to achieve robust and efficient indoor localization with two major challenges. First, the localization accuracy can be degraded by the random signal fluctuations, which would influence conventional localization algorithms that simply learn handcrafted features from raw fingerprint data. Second, mobile users are sensitive to the localization delay, but conventional indoor localization algorithms are computation-intensive and time-consuming. In this paper, we propose EdgeLoc, an edge-IoT framework for efficient and robust indoor localization using capsule networks. We develop a deep learning model with the CapsNet to efficiently extract hierarchical information from WiFi fingerprint data, thereby significantly improving the localization accuracy. Moreover, we implement an edge-computing prototype system to achieve a nearly real-time localization process, by enabling mobile users with the deep-learning model that has been well-trained by the edge server. We conduct a real-world field experimental study with over 33,600 data points and an extensive synthetic experiment with the open dataset, and the experimental results validate the effectiveness of EdgeLoc. The best trade-off of the EdgeLoc system achieves 98.5% localization accuracy within an average positioning time of only 2.31 ms in the field experiment.