 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDMMG: Dual Min-Max Games for Self-Supervised Skeleton-Based Action Recognition
Feb 22, 2023In this work, we propose a new Dual Min-Max Games (DMMG) based self-supervised skeleton action recognition method by augmenting unlabeled data in a contrastive learning framework. Our DMMG consists of a viewpoint variation min-max game and an edge perturbation min-max game. These two min-max games adopt an adversarial paradigm to perform data augmentation on the skeleton sequences and graph-structured body joints, respectively. Our viewpoint variation min-max game focuses on constructing various hard contrastive pairs by generating skeleton sequences from various viewpoints. These hard contrastive pairs help our model learn representative action features, thus facilitating model transfer to downstream tasks. Moreover, our edge perturbation min-max game specializes in building diverse hard contrastive samples through perturbing connectivity strength among graph-based body joints. The connectivity-strength varying contrastive pairs enable the model to capture minimal sufficient information of different actions, such as representative gestures for an action while preventing the model from overfitting. By fully exploiting the proposed DMMG, we can generate sufficient challenging contrastive pairs and thus achieve discriminative action feature representations from unlabeled skeleton data in a self-supervised manner. Extensive experiments demonstrate that our method achieves superior results under various evaluation protocols on widely-used NTU-RGB+D and NTU120-RGB+D datasets.
AFE-CNN: 3D Skeleton-based Action Recognition with Action Feature Enhancement
Aug 06, 2022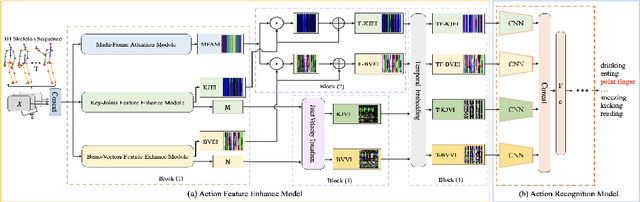
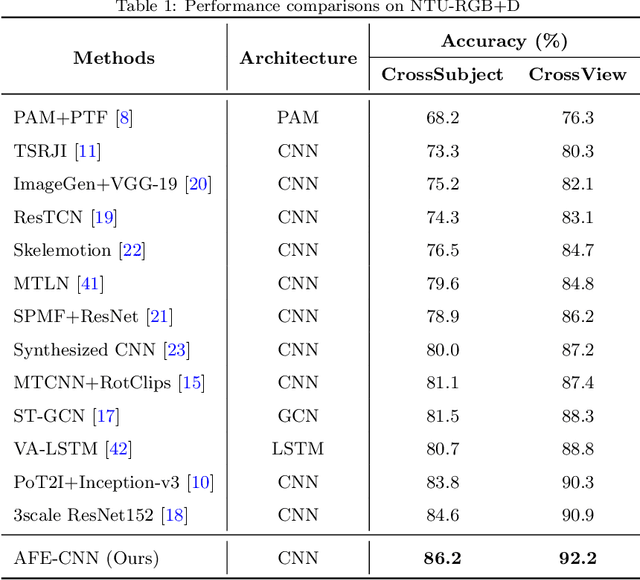
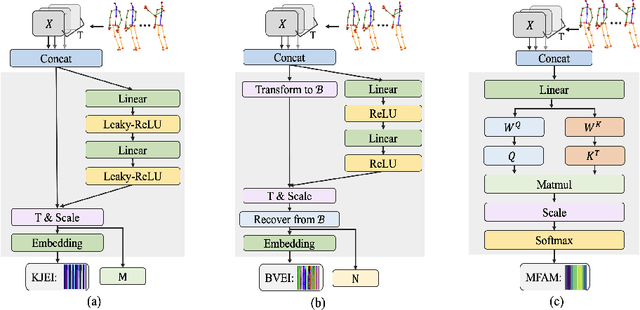
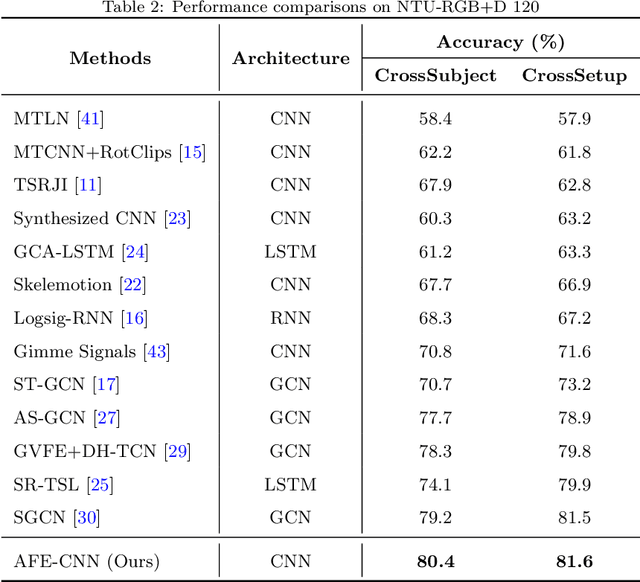
Existing 3D skeleton-based action recognition approaches reach impressive performance by encoding handcrafted action features to image format and decoding by CNNs. However, such methods are limited in two ways: a) the handcrafted action features are difficult to handle challenging actions, and b) they generally require complex CNN models to improve action recognition accuracy, which usually occur heavy computational burden. To overcome these limitations, we introduce a novel AFE-CNN, which devotes to enhance the features of 3D skeleton-based actions to adapt to challenging actions. We propose feature enhance modules from key joint, bone vector, key frame and temporal perspectives, thus the AFE-CNN is more robust to camera views and body sizes variation, and significantly improve the recognition accuracy on challenging actions. Moreover, our AFE-CNN adopts a light-weight CNN model to decode images with action feature enhanced, which ensures a much lower computational burden than the state-of-the-art methods. We evaluate the AFE-CNN on three benchmark skeleton-based action datasets: NTU RGB+D, NTU RGB+D 120, and UTKinect-Action3D, with extensive experimental results demonstrate our outstanding performance of AFE-CNN.
PoseGU: 3D Human Pose Estimation with Novel Human Pose Generator and Unbiased Learning
Jul 07, 2022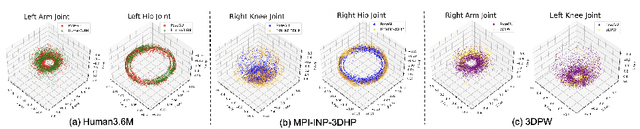
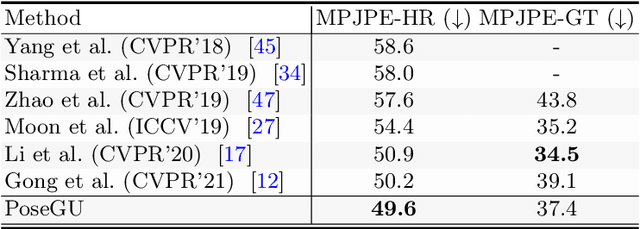

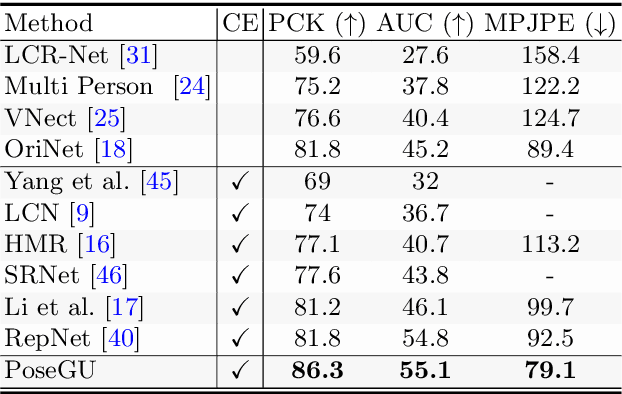
3D pose estimation has recently gained substantial interests in computer vision domain. Existing 3D pose estimation methods have a strong reliance on large size well-annotated 3D pose datasets, and they suffer poor model generalization on unseen poses due to limited diversity of 3D poses in training sets. In this work, we propose PoseGU, a novel human pose generator that generates diverse poses with access only to a small size of seed samples, while equipping the Counterfactual Risk Minimization to pursue an unbiased evaluation objective. Extensive experiments demonstrate PoseGU outforms almost all the state-of-the-art 3D human pose methods under consideration over three popular benchmark datasets. Empirical analysis also proves PoseGU generates 3D poses with improved data diversity and better generalization ability.