 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Fixed-Point Neural Operator for Size- and Functional-Transferable Hamiltonian Prediction
Jun 12, 2026Predicting the Kohn-Sham Hamiltonian with machine learning can accelerate density functional theory while retaining access to molecular orbitals, energy levels, and electronic-structure observables that energy-only surrogates cannot resolve. Yet element-wise agreement with the converged Hamiltonian, an implicit fixed point of the self-consistent field iteration, does not determine the occupied subspace that governs orbital energies and densities. Here we present HamEvo, a neural operator that learns the single-step self-consistent update and returns the converged Hamiltonian as its fixed point. HamEvo is pre-trained on intermediate self-consistent trajectories and calibrated at equilibrium with density-matrix supervision. Across benchmarks from MD17 to drug-like QMugs, HamEvo lowers Hamiltonian errors by 35-49% over direct-regression and deep-equilibrium baselines, and predicts QMugs HOMO and LUMO energies with mean absolute errors of 0.036 and 0.053 eV, near the 1 kcal/mol chemical-accuracy scale. Few-shot fine-tuning with only 20 reference conformations extends HamEvo to molecules of up to 122 atoms, well beyond the size range covered by pre-training. With thermal molecular-dynamics sampling, HamEvo captures temperature-dependent HOMO-LUMO gap renormalization beyond the harmonic approximation. Inference is up to 242 times faster than conventional DFT.
VISTA: View-Consistent Self-Verified Training for GUI Grounding
Jun 12, 2026When applying Group Relative Policy Optimization (GRPO) for GUI Grounding, rollouts are sampled from a single screenshot view; groups often become either all failures on difficult instances or all successes on easy ones, yielding no useful relative advantage. We propose VISTA (View-Consistent Self-Verified Training), a GRPO-based training framework that constructs each comparison group from multiple target-preserving views of the same GUI instance.Each view is generated by a crop that keeps the target element visible and remaps its box exactly, so model rollouts are compared across semantically equivalent but geometrically different inputs. To stabilize short coordinate generation without turning reinforcement learning into unconditional imitation, VISTA further adds a self-verified cross-view anchor: an oracle answer optimized with an advantage-weighted loss, excluded from the group baseline and activated only when the model has produced a maximum-reward rollout. Across five GUI-grounding benchmarks and multiple Qwen backbones, VISTA consistently improves grounding accuracy.On ScreenSpot-Pro, it raises Qwen3-VL 4B/8B/30B-A3B from 55.5/52.7/53.7 to 63.4/65.8/67.0. Robustness analyses further show higher worst-view accuracy and lower prediction flip rates.
N-GRPO: Embedding-Level Neighbor Mixing for Enhanced Policy Optimization
Jun 09, 2026The success of Large Language Models in mathematical reasoning relies heavily on the generation of diverse and valid solution paths during the rollout phase. However, current rollout techniques face a fundamental trade-off: token-level sampling often yields redundant trajectories that differ only in rephrasing, while embedding-level methods utilizing random noise frequently disrupt semantic consistency. To resolve this, we introduce N-GRPO, a novel exploration strategy integrated into the Group Relative Policy Optimization (GRPO) framework. Rather than relying on token-level sampling or native embedding-level noise, our approach leverages Semantic Neighbor Mixing. This mechanism dynamically constructs input representations by mixing the embeddings of an anchor token and its nearest semantic neighbors, thereby injecting diversity while strictly adhering to the local semantic manifold. Experimental evaluations on the DeepSeek-R1-Distill-Qwen models across different sizes show that N-GRPO not only achieves consistent improvements over strong baselines on math reasoning benchmarks but also exhibits robust generalization capabilities on out-of-distribution tasks.
Verifier-Free RL for LLMs via Intrinsic Gradient-Norm Reward
May 11, 2026While Reinforcement Learning with Verifiable Rewards (RLVR) has recently emerged as a promising post-training paradigm for Large Language Models (LLMs), its dependency on the gold label or domain-specific verifiers limits its scalability to new tasks and domains. In this work, we propose Verifier-free Intrinsic Gradient-Norm Reward (VIGOR), a simple reward that uses only the policy model itself. Given a prompt, VIGOR samples a group of completions and assigns higher within-group rewards to outputs that induce smaller $\ell_2$ norms of the teacher-forced negative log-likelihood gradients under the current parameters. Intuitively, lower gradient norms suggest the completion aligns better with the current policy, serving as an intrinsic preference signal for policy optimization. To make this intrinsic signal practical for RL, we correct the systematic length bias of averaged token-level gradients with a $\sqrt{T}$ scaling, and apply group-wise rank shaping to stabilize reward scales across prompts. Across mathematical reasoning benchmarks, VIGOR outperforms the state-of-the-art Reinforcement Learning from Internal Feedback (RLIF) baseline, and it also exhibits cross-domain transfer to code benchmarks when trained only on math data. For instance, on Qwen2.5-7B-Base post-trained on MATH, VIGOR improves the average math accuracy by +3.31% and the average code accuracy by +1.91% over this baseline, while exhibiting more stable training dynamics. The code is available at https://github.com/ZJUSCL/VIGOR.
UI-Venus-1.5 Technical Report
Feb 09, 2026GUI agents have emerged as a powerful paradigm for automating interactions in digital environments, yet achieving both broad generality and consistently strong task performance remains challenging.In this report, we present UI-Venus-1.5, a unified, end-to-end GUI Agent designed for robust real-world applications.The proposed model family comprises two dense variants (2B and 8B) and one mixture-of-experts variant (30B-A3B) to meet various downstream application scenarios.Compared to our previous version, UI-Venus-1.5 introduces three key technical advances: (1) a comprehensive Mid-Training stage leveraging 10 billion tokens across 30+ datasets to establish foundational GUI semantics; (2) Online Reinforcement Learning with full-trajectory rollouts, aligning training objectives with long-horizon, dynamic navigation in large-scale environments; and (3) a single unified GUI Agent constructed via Model Merging, which synthesizes domain-specific models (grounding, web, and mobile) into one cohesive checkpoint. Extensive evaluations demonstrate that UI-Venus-1.5 establishes new state-of-the-art performance on benchmarks such as ScreenSpot-Pro (69.6%), VenusBench-GD (75.0%), and AndroidWorld (77.6%), significantly outperforming previous strong baselines. In addition, UI-Venus-1.5 demonstrates robust navigation capabilities across a variety of Chinese mobile apps, effectively executing user instructions in real-world scenarios. Code: https://github.com/inclusionAI/UI-Venus; Model: https://huggingface.co/collections/inclusionAI/ui-venus
Mitigating Conversational Inertia in Multi-Turn Agents
Feb 03, 2026Large language models excel as few-shot learners when provided with appropriate demonstrations, yet this strength becomes problematic in multiturn agent scenarios, where LLMs erroneously mimic their own previous responses as few-shot examples. Through attention analysis, we identify conversational inertia, a phenomenon where models exhibit strong diagonal attention to previous responses, which is associated with imitation bias that constrains exploration. This reveals a tension when transforming few-shot LLMs into agents: longer context enriches environmental feedback for exploitation, yet also amplifies conversational inertia that undermines exploration. Our key insight is that for identical states, actions generated with longer contexts exhibit stronger inertia than those with shorter contexts, enabling construction of preference pairs without environment rewards. Based on this, we propose Context Preference Learning to calibrate model preferences to favor low-inertia responses over highinertia ones. We further provide context management strategies at inference time to balance exploration and exploitation. Experimental results across eight agentic environments and one deep research scenario validate that our framework reduces conversational inertia and achieves performance improvements.
GPD: Guided Progressive Distillation for Fast and High-Quality Video Generation
Feb 02, 2026Diffusion models have achieved remarkable success in video generation; however, the high computational cost of the denoising process remains a major bottleneck. Existing approaches have shown promise in reducing the number of diffusion steps, but they often suffer from significant quality degradation when applied to video generation. We propose Guided Progressive Distillation (GPD), a framework that accelerates the diffusion process for fast and high-quality video generation. GPD introduces a novel training strategy in which a teacher model progressively guides a student model to operate with larger step sizes. The framework consists of two key components: (1) an online-generated training target that reduces optimization difficulty while improving computational efficiency, and (2) frequency-domain constraints in the latent space that promote the preservation of fine-grained details and temporal dynamics. Applied to the Wan2.1 model, GPD reduces the number of sampling steps from 48 to 6 while maintaining competitive visual quality on VBench. Compared with existing distillation methods, GPD demonstrates clear advantages in both pipeline simplicity and quality preservation.
MTC-VAE: Multi-Level Temporal Compression with Content Awareness
Feb 01, 2026Latent Video Diffusion Models (LVDMs) rely on Variational Autoencoders (VAEs) to compress videos into compact latent representations. For continuous Variational Autoencoders (VAEs), achieving higher compression rates is desirable; yet, the efficiency notably declines when extra sampling layers are added without expanding the dimensions of hidden channels. In this paper, we present a technique to convert fixed compression rate VAEs into models that support multi-level temporal compression, providing a straightforward and minimal fine-tuning approach to counteract performance decline at elevated compression rates.Moreover, we examine how varying compression levels impact model performance over video segments with diverse characteristics, offering empirical evidence on the effectiveness of our proposed approach. We also investigate the integration of our multi-level temporal compression VAE with diffusion-based generative models, DiT, highlighting successful concurrent training and compatibility within these frameworks. This investigation illustrates the potential uses of multi-level temporal compression.
Unified Generation and Self-Verification for Vision-Language Models via Advantage Decoupled Preference Optimization
Jan 04, 2026Parallel test-time scaling typically trains separate generation and verification models, incurring high training and inference costs. We propose Advantage Decoupled Preference Optimization (ADPO), a unified reinforcement learning framework that jointly learns answer generation and self-verification within a single policy. ADPO introduces two innovations: a preference verification reward improving verification capability and a decoupled optimization mechanism enabling synergistic optimization of generation and verification. Specifically, the preference verification reward computes mean verification scores from positive and negative samples as decision thresholds, providing positive feedback when prediction correctness aligns with answer correctness. Meanwhile, the advantage decoupled optimization computes separate advantages for generation and verification, applies token masks to isolate gradients, and combines masked GRPO objectives, preserving generation quality while calibrating verification scores. ADPO achieves up to +34.1% higher verification AUC and -53.5% lower inference time, with significant gains of +2.8%/+1.4% accuracy on MathVista/MMMU, +1.9 cIoU on ReasonSeg, and +1.7%/+1.0% step success rate on AndroidControl/GUI Odyssey.
MVP: Multiple View Prediction Improves GUI Grounding
Dec 09, 2025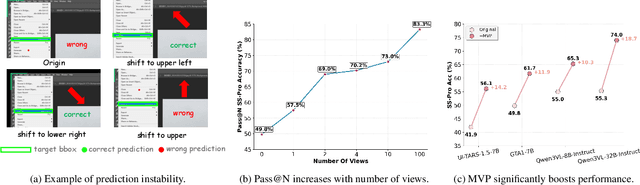
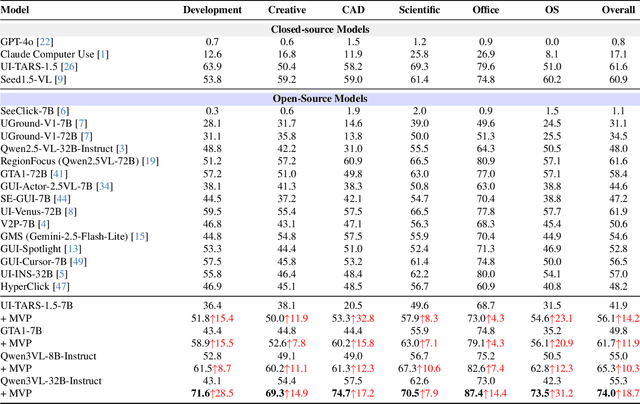
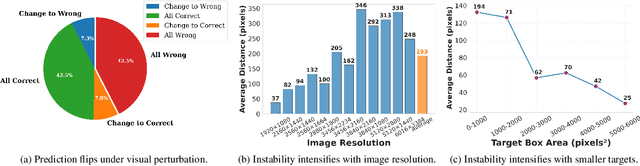
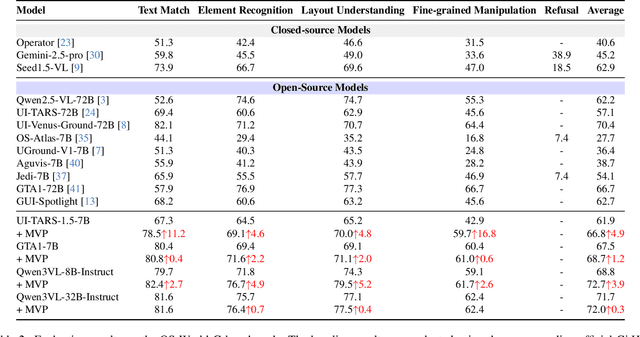
GUI grounding, which translates natural language instructions into precise pixel coordinates, is essential for developing practical GUI agents. However, we observe that existing grounding models exhibit significant coordinate prediction instability, minor visual perturbations (e.g. cropping a few pixels) can drastically alter predictions, flipping results between correct and incorrect. This instability severely undermines model performance, especially for samples with high-resolution and small UI elements. To address this issue, we propose Multi-View Prediction (MVP), a training-free framework that enhances grounding performance through multi-view inference. Our key insight is that while single-view predictions may be unstable, aggregating predictions from multiple carefully cropped views can effectively distinguish correct coordinates from outliers. MVP comprises two components: (1) Attention-Guided View Proposal, which derives diverse views guided by instruction-to-image attention scores, and (2) Multi-Coordinates Clustering, which ensembles predictions by selecting the centroid of the densest spatial cluster. Extensive experiments demonstrate MVP's effectiveness across various models and benchmarks. Notably, on ScreenSpot-Pro, MVP boosts UI-TARS-1.5-7B to 56.1%, GTA1-7B to 61.7%, Qwen3VL-8B-Instruct to 65.3%, and Qwen3VL-32B-Instruct to 74.0%. The code is available at https://github.com/ZJUSCL/MVP.