 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEHRNavigator: A Multi-Agent System for Patient-Level Clinical Question Answering over Heterogeneous Electronic Health Records
Jan 15, 2026Clinical decision-making increasingly relies on timely and context-aware access to patient information within Electronic Health Records (EHRs), yet most existing natural language question-answering (QA) systems are evaluated solely on benchmark datasets, limiting their practical relevance. To overcome this limitation, we introduce EHRNavigator, a multi-agent framework that harnesses AI agents to perform patient-level question answering across heterogeneous and multimodal EHR data. We assessed its performance using both public benchmark and institutional datasets under realistic hospital conditions characterized by diverse schemas, temporal reasoning demands, and multimodal evidence integration. Through quantitative evaluation and clinician-validated chart review, EHRNavigator demonstrated strong generalization, achieving 86% accuracy on real-world cases while maintaining clinically acceptable response times. Overall, these findings confirm that EHRNavigator effectively bridges the gap between benchmark evaluation and clinical deployment, offering a robust, adaptive, and efficient solution for real-world EHR question answering.
Dynamic Experts Search: Enhancing Reasoning in Mixture-of-Experts LLMs at Test Time
Sep 26, 2025
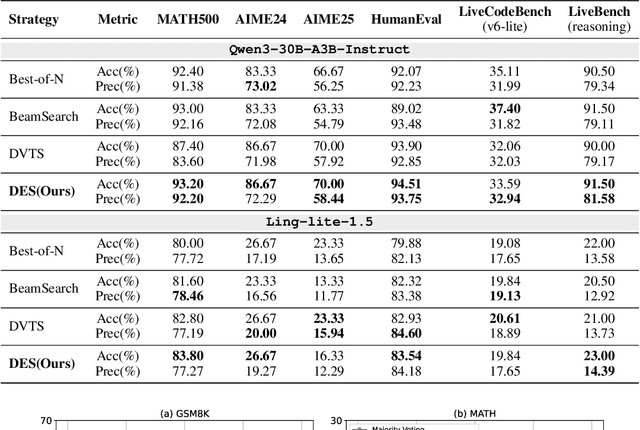


Test-Time Scaling (TTS) enhances the reasoning ability of large language models (LLMs) by allocating additional computation during inference. However, existing approaches primarily rely on output-level sampling while overlooking the role of model architecture. In mainstream Mixture-of-Experts (MoE) LLMs, we observe that varying the number of activated experts yields complementary solution sets with stable accuracy, revealing a new and underexplored source of diversity. Motivated by this observation, we propose Dynamic Experts Search (DES), a TTS strategy that elevates expert activation into a controllable dimension of the search space. DES integrates two key components: (1) Dynamic MoE, which enables direct control of expert counts during inference to generate diverse reasoning trajectories without additional cost; and (2) Expert Configuration Inheritance, which preserves consistent expert counts within a reasoning path while varying them across runs, thereby balancing stability and diversity throughout the search. Extensive experiments across MoE architectures, verifiers and reasoning benchmarks (i.e., math, code and knowledge) demonstrate that DES reliably outperforms TTS baselines, enhancing accuracy and stability without additional cost. These results highlight DES as a practical and scalable form of architecture-aware TTS, illustrating how structural flexibility in modern LLMs can advance reasoning.
From Trial to Triumph: Advancing Long Video Understanding via Visual Context Sample Scaling and Self-reward Alignment
Mar 26, 2025Multi-modal Large language models (MLLMs) show remarkable ability in video understanding. Nevertheless, understanding long videos remains challenging as the models can only process a finite number of frames in a single inference, potentially omitting crucial visual information. To address the challenge, we propose generating multiple predictions through visual context sampling, followed by a scoring mechanism to select the final prediction. Specifically, we devise a bin-wise sampling strategy that enables MLLMs to generate diverse answers based on various combinations of keyframes, thereby enriching the visual context. To determine the final prediction from the sampled answers, we employ a self-reward by linearly combining three scores: (1) a frequency score indicating the prevalence of each option, (2) a marginal confidence score reflecting the inter-intra sample certainty of MLLM predictions, and (3) a reasoning score for different question types, including clue-guided answering for global questions and temporal self-refocusing for local questions. The frequency score ensures robustness through majority correctness, the confidence-aligned score reflects prediction certainty, and the typed-reasoning score addresses cases with sparse key visual information using tailored strategies. Experiments show that this approach covers the correct answer for a high percentage of long video questions, on seven datasets show that our method improves the performance of three MLLMs.
DreamDPO: Aligning Text-to-3D Generation with Human Preferences via Direct Preference Optimization
Feb 05, 2025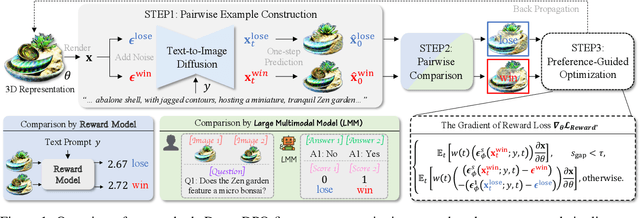
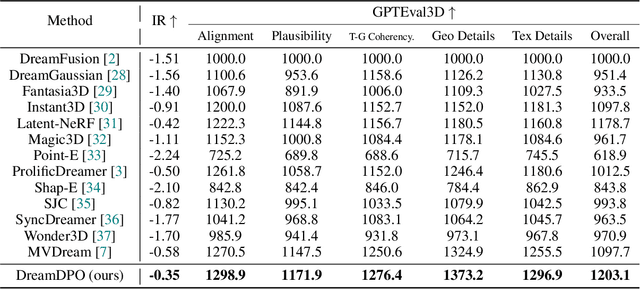

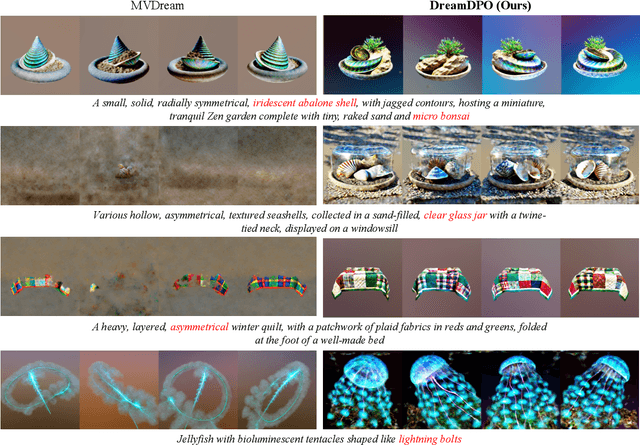
Text-to-3D generation automates 3D content creation from textual descriptions, which offers transformative potential across various fields. However, existing methods often struggle to align generated content with human preferences, limiting their applicability and flexibility. To address these limitations, in this paper, we propose DreamDPO, an optimization-based framework that integrates human preferences into the 3D generation process, through direct preference optimization. Practically, DreamDPO first constructs pairwise examples, then compare their alignment with human preferences using reward or large multimodal models, and lastly optimizes the 3D representation with a preference-driven loss function. By leveraging pairwise comparison to reflect preferences, DreamDPO reduces reliance on precise pointwise quality evaluations while enabling fine-grained controllability through preference-guided optimization. Experiments demonstrate that DreamDPO achieves competitive results, and provides higher-quality and more controllable 3D content compared to existing methods. The code and models will be open-sourced.
TV-Dialogue: Crafting Theme-Aware Video Dialogues with Immersive Interaction
Jan 31, 2025
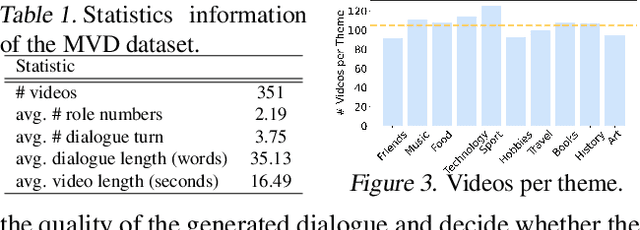
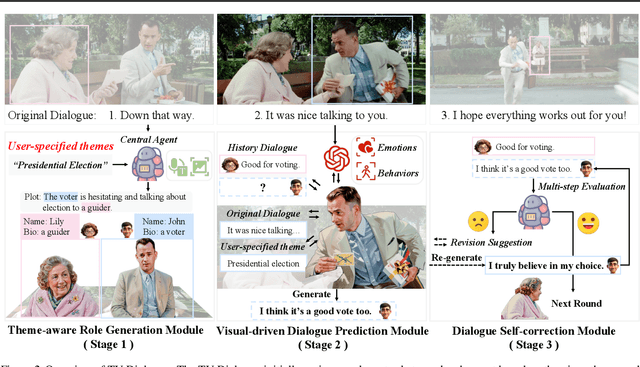

Recent advancements in LLMs have accelerated the development of dialogue generation across text and images, yet video-based dialogue generation remains underexplored and presents unique challenges. In this paper, we introduce Theme-aware Video Dialogue Crafting (TVDC), a novel task aimed at generating new dialogues that align with video content and adhere to user-specified themes. We propose TV-Dialogue, a novel multi-modal agent framework that ensures both theme alignment (i.e., the dialogue revolves around the theme) and visual consistency (i.e., the dialogue matches the emotions and behaviors of characters in the video) by enabling real-time immersive interactions among video characters, thereby accurately understanding the video content and generating new dialogue that aligns with the given themes. To assess the generated dialogues, we present a multi-granularity evaluation benchmark with high accuracy, interpretability and reliability, demonstrating the effectiveness of TV-Dialogue on self-collected dataset over directly using existing LLMs. Extensive experiments reveal that TV-Dialogue can generate dialogues for videos of any length and any theme in a zero-shot manner without training. Our findings underscore the potential of TV-Dialogue for various applications, such as video re-creation, film dubbing and its use in downstream multimodal tasks.
BrainGuard: Privacy-Preserving Multisubject Image Reconstructions from Brain Activities
Jan 24, 2025



Reconstructing perceived images from human brain activity forms a crucial link between human and machine learning through Brain-Computer Interfaces. Early methods primarily focused on training separate models for each individual to account for individual variability in brain activity, overlooking valuable cross-subject commonalities. Recent advancements have explored multisubject methods, but these approaches face significant challenges, particularly in data privacy and effectively managing individual variability. To overcome these challenges, we introduce BrainGuard, a privacy-preserving collaborative training framework designed to enhance image reconstruction from multisubject fMRI data while safeguarding individual privacy. BrainGuard employs a collaborative global-local architecture where individual models are trained on each subject's local data and operate in conjunction with a shared global model that captures and leverages cross-subject patterns. This architecture eliminates the need to aggregate fMRI data across subjects, thereby ensuring privacy preservation. To tackle the complexity of fMRI data, BrainGuard integrates a hybrid synchronization strategy, enabling individual models to dynamically incorporate parameters from the global model. By establishing a secure and collaborative training environment, BrainGuard not only protects sensitive brain data but also improves the image reconstructions accuracy. Extensive experiments demonstrate that BrainGuard sets a new benchmark in both high-level and low-level metrics, advancing the state-of-the-art in brain decoding through its innovative design.
InfiniDreamer: Arbitrarily Long Human Motion Generation via Segment Score Distillation
Nov 27, 2024



We present InfiniDreamer, a novel framework for arbitrarily long human motion generation. InfiniDreamer addresses the limitations of current motion generation methods, which are typically restricted to short sequences due to the lack of long motion training data. To achieve this, we first generate sub-motions corresponding to each textual description and then assemble them into a coarse, extended sequence using randomly initialized transition segments. We then introduce an optimization-based method called Segment Score Distillation (SSD) to refine the entire long motion sequence. SSD is designed to utilize an existing motion prior, which is trained only on short clips, in a training-free manner. Specifically, SSD iteratively refines overlapping short segments sampled from the coarsely extended long motion sequence, progressively aligning them with the pre-trained motion diffusion prior. This process ensures local coherence within each segment, while the refined transitions between segments maintain global consistency across the entire sequence. Extensive qualitative and quantitative experiments validate the superiority of our framework, showcasing its ability to generate coherent, contextually aware motion sequences of arbitrary length.
AnySynth: Harnessing the Power of Image Synthetic Data Generation for Generalized Vision-Language Tasks
Nov 24, 2024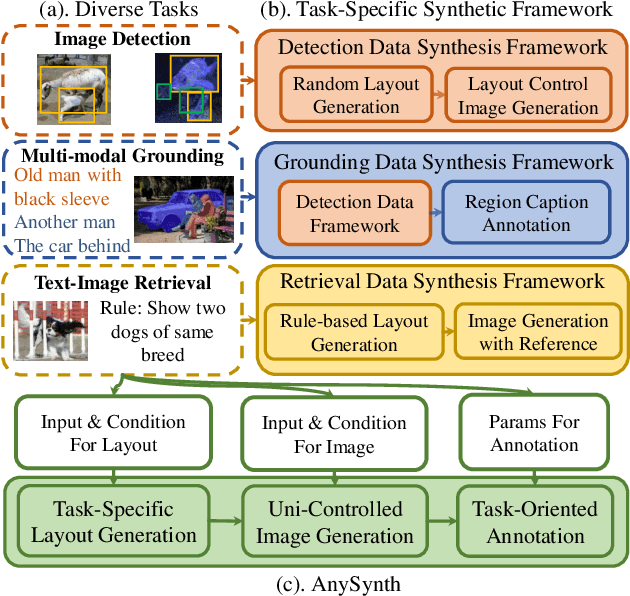


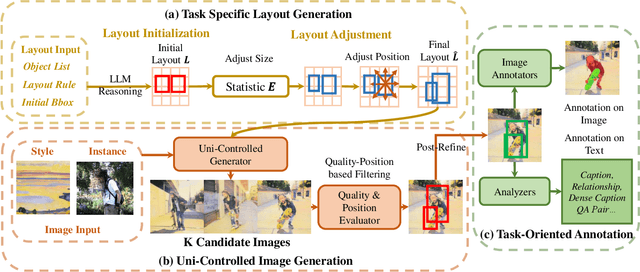
Diffusion models have recently been employed to generate high-quality images, reducing the need for manual data collection and improving model generalization in tasks such as object detection, instance segmentation, and image perception. However, the synthetic framework is usually designed with meticulous human effort for each task due to various requirements on image layout, content, and annotation formats, restricting the application of synthetic data on more general scenarios. In this paper, we propose AnySynth, a unified framework integrating adaptable, comprehensive, and highly controllable components capable of generating an arbitrary type of synthetic data given diverse requirements. Specifically, the Task-Specific Layout Generation Module is first introduced to produce reasonable layouts for different tasks by leveraging the generation ability of large language models and layout priors of real-world images. A Uni-Controlled Image Generation Module is then developed to create high-quality synthetic images that are controllable and based on the generated layouts. In addition, user specific reference images, and style images can be incorporated into the generation to task requirements. Finally, the Task-Oriented Annotation Module offers precise and detailed annotations for the generated images across different tasks. We have validated our framework's performance across various tasks, including Few-shot Object Detection, Cross-domain Object Detection, Zero-shot Composed Image Retrieval, and Multi-modal Image Perception and Grounding. The specific data synthesized by our framework significantly improves model performance in these tasks, demonstrating the generality and effectiveness of our framework.
Imagine and Seek: Improving Composed Image Retrieval with an Imagined Proxy
Nov 24, 2024



The Zero-shot Composed Image Retrieval (ZSCIR) requires retrieving images that match the query image and the relative captions. Current methods focus on projecting the query image into the text feature space, subsequently combining them with features of query texts for retrieval. However, retrieving images only with the text features cannot guarantee detailed alignment due to the natural gap between images and text. In this paper, we introduce Imagined Proxy for CIR (IP-CIR), a training-free method that creates a proxy image aligned with the query image and text description, enhancing query representation in the retrieval process. We first leverage the large language model's generalization capability to generate an image layout, and then apply both the query text and image for conditional generation. The robust query features are enhanced by merging the proxy image, query image, and text semantic perturbation. Our newly proposed balancing metric integrates text-based and proxy retrieval similarities, allowing for more accurate retrieval of the target image while incorporating image-side information into the process. Experiments on three public datasets demonstrate that our method significantly improves retrieval performances. We achieve state-of-the-art (SOTA) results on the CIRR dataset with a Recall@K of 70.07 at K=10. Additionally, we achieved an improvement in Recall@10 on the FashionIQ dataset, rising from 45.11 to 45.74, and improved the baseline performance in CIRCO with a mAPK@10 score, increasing from 32.24 to 34.26.
Image Regeneration: Evaluating Text-to-Image Model via Generating Identical Image with Multimodal Large Language Models
Nov 14, 2024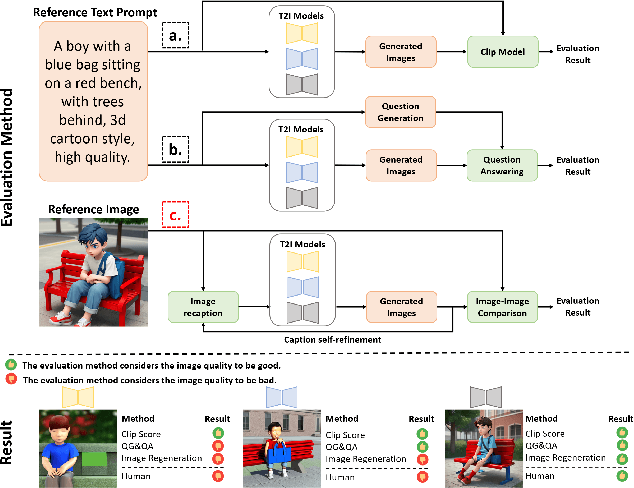



Diffusion models have revitalized the image generation domain, playing crucial roles in both academic research and artistic expression. With the emergence of new diffusion models, assessing the performance of text-to-image models has become increasingly important. Current metrics focus on directly matching the input text with the generated image, but due to cross-modal information asymmetry, this leads to unreliable or incomplete assessment results. Motivated by this, we introduce the Image Regeneration task in this study to assess text-to-image models by tasking the T2I model with generating an image according to the reference image. We use GPT4V to bridge the gap between the reference image and the text input for the T2I model, allowing T2I models to understand image content. This evaluation process is simplified as comparisons between the generated image and the reference image are straightforward. Two regeneration datasets spanning content-diverse and style-diverse evaluation dataset are introduced to evaluate the leading diffusion models currently available. Additionally, we present ImageRepainter framework to enhance the quality of generated images by improving content comprehension via MLLM guided iterative generation and revision. Our comprehensive experiments have showcased the effectiveness of this framework in assessing the generative capabilities of models. By leveraging MLLM, we have demonstrated that a robust T2M can produce images more closely resembling the reference image.