 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge4DPC$^2$hat: Towards Dynamic Point Cloud Understanding with Failure-Aware Bootstrapping
Feb 03, 2026Point clouds provide a compact and expressive representation of 3D objects, and have recently been integrated into multimodal large language models (MLLMs). However, existing methods primarily focus on static objects, while understanding dynamic point cloud sequences remains largely unexplored. This limitation is mainly caused by the lack of large-scale cross-modal datasets and the difficulty of modeling motions in spatio-temporal contexts. To bridge this gap, we present 4DPC$^2$hat, the first MLLM tailored for dynamic point cloud understanding. To this end, we construct a large-scale cross-modal dataset 4DPC$^2$hat-200K via a meticulous two-stage pipeline consisting of topology-consistent 4D point construction and two-level captioning. The dataset contains over 44K dynamic object sequences, 700K point cloud frames, and 200K curated question-answer (QA) pairs, supporting inquiries about counting, temporal relationship, action, spatial relationship, and appearance. At the core of the framework, we introduce a Mamba-enhanced temporal reasoning MLLM to capture long-range dependencies and dynamic patterns among a point cloud sequence. Furthermore, we propose a failure-aware bootstrapping learning strategy that iteratively identifies model deficiencies and generates targeted QA supervision to continuously strengthen corresponding reasoning capabilities. Extensive experiments demonstrate that our 4DPC$^2$hat significantly improves action understanding and temporal reasoning compared with existing models, establishing a strong foundation for 4D dynamic point cloud understanding.
Seeing Is Believing? A Benchmark for Multimodal Large Language Models on Visual Illusions and Anomalies
Feb 02, 2026Multimodal Large Language Models (MLLMs) have shown remarkable proficiency on general-purpose vision-language benchmarks, reaching or even exceeding human-level performance. However, these evaluations typically rely on standard in-distribution data, leaving the robustness of MLLMs largely unexamined when faced with scenarios that defy common-sense priors. To address this gap, we introduce VIA-Bench, a challenging benchmark designed to probe model performance on visual illusions and anomalies. It includes six core categories: color illusions, motion illusions, gestalt illusions, geometric and spatial illusions, general visual illusions, and visual anomalies. Through careful human-in-the-loop review, we construct over 1K high-quality question-answer pairs that require nuanced visual reasoning. Extensive evaluation of over 20 state-of-the-art MLLMs, including proprietary, open-source, and reasoning-enhanced models, uncovers significant vulnerabilities. Notably, we find that Chain-of-Thought (CoT) reasoning offers negligible robustness, often yielding ``brittle mirages'' where the model's logic collapses under illusory stimuli. Our findings reveal a fundamental divergence between machine and human perception, suggesting that resolving such perceptual bottlenecks is critical for the advancement of artificial general intelligence. The benchmark data and code will be released.
DRFormer: A Dual-Regularized Bidirectional Transformer for Person Re-identification
Feb 01, 2026Both fine-grained discriminative details and global semantic features can contribute to solving person re-identification challenges, such as occlusion and pose variations. Vision foundation models (\textit{e.g.}, DINO) excel at mining local textures, and vision-language models (\textit{e.g.}, CLIP) capture strong global semantic difference. Existing methods predominantly rely on a single paradigm, neglecting the potential benefits of their integration. In this paper, we analyze the complementary roles of these two architectures and propose a framework to synergize their strengths by a \textbf{D}ual-\textbf{R}egularized Bidirectional \textbf{Transformer} (\textbf{DRFormer}). The dual-regularization mechanism ensures diverse feature extraction and achieves a better balance in the contributions of the two models. Extensive experiments on five benchmarks show that our method effectively harmonizes local and global representations, achieving competitive performance against state-of-the-art methods.
TransNormal: Dense Visual Semantics for Diffusion-based Transparent Object Normal Estimation
Jan 31, 2026Monocular normal estimation for transparent objects is critical for laboratory automation, yet it remains challenging due to complex light refraction and reflection. These optical properties often lead to catastrophic failures in conventional depth and normal sensors, hindering the deployment of embodied AI in scientific environments. We propose TransNormal, a novel framework that adapts pre-trained diffusion priors for single-step normal regression. To handle the lack of texture in transparent surfaces, TransNormal integrates dense visual semantics from DINOv3 via a cross-attention mechanism, providing strong geometric cues. Furthermore, we employ a multi-task learning objective and wavelet-based regularization to ensure the preservation of fine-grained structural details. To support this task, we introduce TransNormal-Synthetic, a physics-based dataset with high-fidelity normal maps for transparent labware. Extensive experiments demonstrate that TransNormal significantly outperforms state-of-the-art methods: on the ClearGrasp benchmark, it reduces mean error by 24.4% and improves 11.25° accuracy by 22.8%; on ClearPose, it achieves a 15.2% reduction in mean error. The code and dataset will be made publicly available at https://longxiang-ai.github.io/TransNormal.
DeMoGen: Towards Decompositional Human Motion Generation with Energy-Based Diffusion Models
Dec 26, 2025Human motions are compositional: complex behaviors can be described as combinations of simpler primitives. However, existing approaches primarily focus on forward modeling, e.g., learning holistic mappings from text to motion or composing a complex motion from a set of motion concepts. In this paper, we consider the inverse perspective: decomposing a holistic motion into semantically meaningful sub-components. We propose DeMoGen, a compositional training paradigm for decompositional learning that employs an energy-based diffusion model. This energy formulation directly captures the composed distribution of multiple motion concepts, enabling the model to discover them without relying on ground-truth motions for individual concepts. Within this paradigm, we introduce three training variants to encourage a decompositional understanding of motion: 1. DeMoGen-Exp explicitly trains on decomposed text prompts; 2. DeMoGen-OSS performs orthogonal self-supervised decomposition; 3. DeMoGen-SC enforces semantic consistency between original and decomposed text embeddings. These variants enable our approach to disentangle reusable motion primitives from complex motion sequences. We also demonstrate that the decomposed motion concepts can be flexibly recombined to generate diverse and novel motions, generalizing beyond the training distribution. Additionally, we construct a text-decomposed dataset to support compositional training, serving as an extended resource to facilitate text-to-motion generation and motion composition.
Motion Matters: Motion-guided Modulation Network for Skeleton-based Micro-Action Recognition
Jul 29, 2025Micro-Actions (MAs) are an important form of non-verbal communication in social interactions, with potential applications in human emotional analysis. However, existing methods in Micro-Action Recognition often overlook the inherent subtle changes in MAs, which limits the accuracy of distinguishing MAs with subtle changes. To address this issue, we present a novel Motion-guided Modulation Network (MMN) that implicitly captures and modulates subtle motion cues to enhance spatial-temporal representation learning. Specifically, we introduce a Motion-guided Skeletal Modulation module (MSM) to inject motion cues at the skeletal level, acting as a control signal to guide spatial representation modeling. In parallel, we design a Motion-guided Temporal Modulation module (MTM) to incorporate motion information at the frame level, facilitating the modeling of holistic motion patterns in micro-actions. Finally, we propose a motion consistency learning strategy to aggregate the motion cues from multi-scale features for micro-action classification. Experimental results on the Micro-Action 52 and iMiGUE datasets demonstrate that MMN achieves state-of-the-art performance in skeleton-based micro-action recognition, underscoring the importance of explicitly modeling subtle motion cues. The code will be available at https://github.com/momiji-bit/MMN.
Uni3D-MoE: Scalable Multimodal 3D Scene Understanding via Mixture of Experts
May 27, 2025Recent advancements in multimodal large language models (MLLMs) have demonstrated considerable potential for comprehensive 3D scene understanding. However, existing approaches typically utilize only one or a limited subset of 3D modalities, resulting in incomplete representations of 3D scenes and reduced interpretive accuracy. Furthermore, different types of queries inherently depend on distinct modalities, indicating that uniform processing of all modality tokens may fail to effectively capture query-specific context. To address these challenges, we propose Uni3D-MoE, a sparse Mixture-of-Experts (MoE)-based 3D MLLM designed to enable adaptive 3D multimodal fusion. Specifically, Uni3D-MoE integrates a comprehensive set of 3D modalities, including multi-view RGB and depth images, bird's-eye-view (BEV) maps, point clouds, and voxel representations. At its core, our framework employs a learnable routing mechanism within the sparse MoE-based large language model, dynamically selecting appropriate experts at the token level. Each expert specializes in processing multimodal tokens based on learned modality preferences, thus facilitating flexible collaboration tailored to diverse task-specific requirements. Extensive evaluations on standard 3D scene understanding benchmarks and specialized datasets demonstrate the efficacy of Uni3D-MoE.
TSGS: Improving Gaussian Splatting for Transparent Surface Reconstruction via Normal and De-lighting Priors
Apr 17, 2025Reconstructing transparent surfaces is essential for tasks such as robotic manipulation in labs, yet it poses a significant challenge for 3D reconstruction techniques like 3D Gaussian Splatting (3DGS). These methods often encounter a transparency-depth dilemma, where the pursuit of photorealistic rendering through standard $\alpha$-blending undermines geometric precision, resulting in considerable depth estimation errors for transparent materials. To address this issue, we introduce Transparent Surface Gaussian Splatting (TSGS), a new framework that separates geometry learning from appearance refinement. In the geometry learning stage, TSGS focuses on geometry by using specular-suppressed inputs to accurately represent surfaces. In the second stage, TSGS improves visual fidelity through anisotropic specular modeling, crucially maintaining the established opacity to ensure geometric accuracy. To enhance depth inference, TSGS employs a first-surface depth extraction method. This technique uses a sliding window over $\alpha$-blending weights to pinpoint the most likely surface location and calculates a robust weighted average depth. To evaluate the transparent surface reconstruction task under realistic conditions, we collect a TransLab dataset that includes complex transparent laboratory glassware. Extensive experiments on TransLab show that TSGS achieves accurate geometric reconstruction and realistic rendering of transparent objects simultaneously within the efficient 3DGS framework. Specifically, TSGS significantly surpasses current leading methods, achieving a 37.3% reduction in chamfer distance and an 8.0% improvement in F1 score compared to the top baseline. The code and dataset will be released at https://longxiang-ai.github.io/TSGS/.
VideoGrain: Modulating Space-Time Attention for Multi-grained Video Editing
Feb 24, 2025



Recent advancements in diffusion models have significantly improved video generation and editing capabilities. However, multi-grained video editing, which encompasses class-level, instance-level, and part-level modifications, remains a formidable challenge. The major difficulties in multi-grained editing include semantic misalignment of text-to-region control and feature coupling within the diffusion model. To address these difficulties, we present VideoGrain, a zero-shot approach that modulates space-time (cross- and self-) attention mechanisms to achieve fine-grained control over video content. We enhance text-to-region control by amplifying each local prompt's attention to its corresponding spatial-disentangled region while minimizing interactions with irrelevant areas in cross-attention. Additionally, we improve feature separation by increasing intra-region awareness and reducing inter-region interference in self-attention. Extensive experiments demonstrate our method achieves state-of-the-art performance in real-world scenarios. Our code, data, and demos are available at https://knightyxp.github.io/VideoGrain_project_page/
DreamDPO: Aligning Text-to-3D Generation with Human Preferences via Direct Preference Optimization
Feb 05, 2025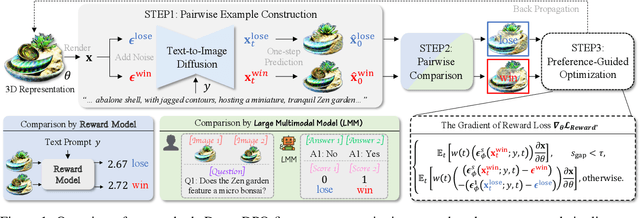
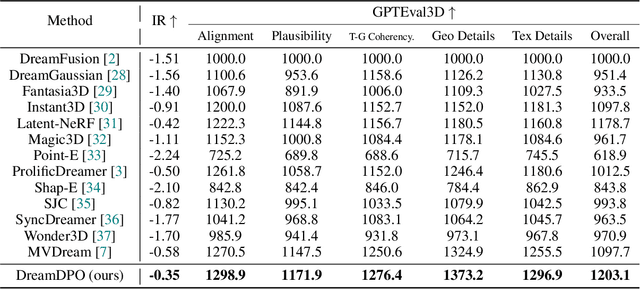

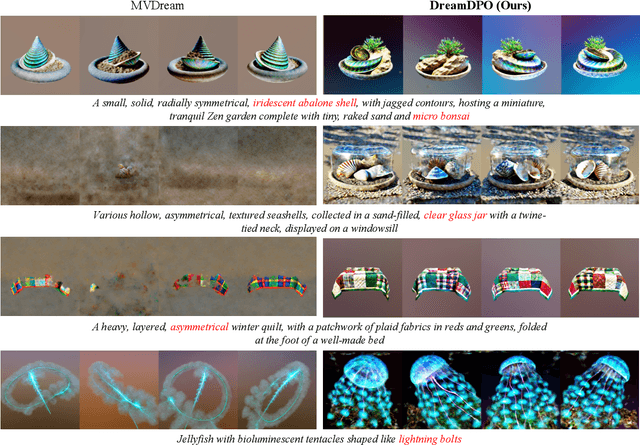
Text-to-3D generation automates 3D content creation from textual descriptions, which offers transformative potential across various fields. However, existing methods often struggle to align generated content with human preferences, limiting their applicability and flexibility. To address these limitations, in this paper, we propose DreamDPO, an optimization-based framework that integrates human preferences into the 3D generation process, through direct preference optimization. Practically, DreamDPO first constructs pairwise examples, then compare their alignment with human preferences using reward or large multimodal models, and lastly optimizes the 3D representation with a preference-driven loss function. By leveraging pairwise comparison to reflect preferences, DreamDPO reduces reliance on precise pointwise quality evaluations while enabling fine-grained controllability through preference-guided optimization. Experiments demonstrate that DreamDPO achieves competitive results, and provides higher-quality and more controllable 3D content compared to existing methods. The code and models will be open-sourced.